100天搞定机器学习|Day60 遇事不决,XGBoost
XGBoost 是一种集大成的机器学习算法,可用于回归,分类和排序等各种问题,在机器学习大赛及工业领域被广泛应用。成功案例包括:网页文本分类、顾客行为预测、情感挖掘、广告点击率预测、恶意软件分类、物品分类、风险评估、大规模在线课程退学率预测。
XGBoost是初学者最值得深度理解的模型之一,它将决策树、boosting、GBDT 等知识点串联起来,强烈建议大家都手撸一波。
本文我将从XGBoost渊源及优点、模型原理及优化推导、XGBoost模型参数解析、调参实例,XGBoost可视化等方面介绍XGBoost。提醒一下,XGBoost 是在 GBDT 基础上的改进,阅读本文需对 GBDT 有一定的了解,不熟悉的同学可以看一下前篇: 100天搞定机器学习|Day58 机器学习入门:硬核拆解GBDT
XGBoost渊源及优势
在数据建模中,经常采用Boosting方法,该方法将成百上千个分类准确率较低的树模型组合起来,成为一个准确率很高的预测模型。这个模型会不断地迭代,每次迭代就生成一颗新的树。但在数据集较复杂的时候,可能需要几千次迭代运算,这将造成巨大的计算瓶颈。
针对这个问题,华盛顿大学的陈天奇博士开发的XGBoost(eXtreme Gradient Boosting)基于C++通过多线程实现了回归树的并行构建,并在原有Gradient Boosting算法基础上加以改进,从而极大地提升了模型训练速度和预测精度。
XGBoost 主要优势如下:
1、GBDT在优化时只用到一阶导数信息,XGBoost同时用到了一阶和二阶导数,还支持自定义损失函数,前提是损失函数可一阶和二阶求导;
2、加入了正则项,用于控制模型的复杂度,防止过拟合;
3、借鉴了随机森林的做法,支持列抽样(随机选择特征),不仅能降低过拟合,还能减少计算;
4、寻找最佳分割点时,实现了一种近似法,还考虑了稀疏数据集、缺失值的处理,大大提升算法的效率;
5、支持并行;
6、近似直方图算法,用于高效地生成候选的分割点;
7、在算法实现时做了很多优化,大大提升了算法的效率,内存空间不够时,利用了分块、预取、压缩、多线程协作的思想。
XGBoost模型原理及优化推导
XGBoost其实也是GBDT的一种,还是加性模型和前向优化算法。
加法模型就是说强分类器由一系列弱分类器线性相加而成。一般组合形式如下:
$$F_M(x;P)=\sum_{m=1}^n\beta_mh(x;a_m)$$
其中,$h(x;a_m)$就是一个个的弱分类器,$a_m$是弱分类器学习到的最优参数,$β_m$就是弱学习在强分类器中所占比重,P是所有$α_m$和$β_m$的组合。这些弱分类器线性相加组成强分类器。
前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以写成这样的形式:
$$F_m (x)=F_{m-1}(x)+ \beta_mh_m (x;a_m)$$
XGBoost 的模型是什么样子的呢?
$$\hat{y}i = \sum^K f_k(x_i), f_k \in \mathcal{F}$$
- 其中 K 是树的棵数。
- $f$是回归树,$f(x)=w_{q(x)}$,满足$(q: R^m \rightarrow T, w \in R^T)$
- q表示每棵树的结构,它会将一个训练样本实例映射到相对应的叶子索引上。
- T是树中的叶子数。
- 每个对应于一个独立的树结构q和叶子权重w。
- $\mathcal{F}$ 是所有回归树组成的函数空间。
与决策树不同的是,每棵回归树包含了在每个叶子上的一个连续分值,我们使用来表示第i个叶子上的分值。对于一个给定样本实例,我们会使用树上的决策规则(由q给定)来将它分类到叶子上,并通过将相应叶子上的分值(由w给定)做求和,计算最终的预测值。
XGBoost的学习
为了在该模型中学到这些函数集合,我们会对下面的正则化目标函数做最小化:
$$\text{obj}(\theta) = \sum_i^n l(y_i, \hat{y}i) + \sum^K \Omega(f_k)$$
其中:$l$ 是损失函数,常见的有 2 种:
平方损失函数:$l(yi,yi)=(y_i−yi)2$
逻辑回归损失函数:$l(yi,yi)=y_i\ln\left(1+e_i}\right)+\left(1-y_i\right)\ln\left(1+e^{\hat{y}_i}\right)$
$Ω(Θ)$: 正则化项,用于惩罚复杂模型,避免模型过分拟合训练数据。常用的正则有L1正则与L2正则:
L1正则(lasso): $Ω ( w ) = λ∣∣w∣∣_1$
L2正则: $Ω ( w ) = \lambda ||w||^2$
下一步就是对目标函数进行学习,每一次保留原来的模型不变,加入一个新的函数$f$到我们的模型中。
$$\begin{split}\hat{y}_i^{(0)} &= 0\
\hat{y}_i^{(1)} &= f_1(x_i) = \hat{y}_i^{(0)} + f_1(x_i)\
\hat{y}_i^{(2)} &= f_1(x_i) + f_2(x_i)= \hat{y}i^{(1)} + f_2(x_i)\
&\dots\
\hat{y}i^{(t)} &= \sum^t f_k(x_i)= \hat{y}i^{(t-1)} + f_t(x_i)\end{split}$$
其中,$\hat{y_i}^{(t)}$为第i个实例在第t次迭代时的预测,我们需要添加树 $f_t$,然后最小化下面的目标函数:
$$
\begin{split}\text{obj}^{(t)} & = \sum^n l(y_i, \hat{y}i^{(t)}) + \sum^t\Omega(f_i) \
& = \sum^n l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) + \Omega(f_t) + \mathrm{constant}\end{split}
$$
假设损失函数使用的是平方损失$l(yi,yi)=(y_i−yi)2$ ,则上式进一步写为:
$$
\begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n (y_i - (\hat{y}i^{(t-1)} + f_t(x_i)))^2 + \sum^t\Omega(f_i) \
& = \sum_{i=1}^n [2(\hat{y}_i^{(t-1)} - y_i)f_t(x_i) + f_t(x_i)^2] + \Omega(f_t) + \mathrm{constant}\end{split}
$$
现在,我们采用泰勒展开来定义一个近似的目标函数:
$\text{obj}^{(t)} = \sum_{i=1}^n [l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t) + \mathrm{constant}$
其中:
$$\begin{split}g_i &= \partial_{\hat{y}_i^{(t-1)}} l(y_i, \hat{y}i^{(t-1)})\
h_i &= \partial_i{(t-1)}}2 l(y_i, \hat{y}_i^{(t-1)})\end{split}$$
$g_i,h_i$分别是loss function上的一阶梯度和二阶梯度。
忘记基础知识的同学顺便重温一下泰勒公式吧
泰勒公式(Taylor’s Formula)是一个用函数在某点的信息描述其附近取值的公式。其初衷是用多项式来近似表示函数在某点周围的情况。
函数$f(x)$在$x_0$处的基本形式如下
$$
\begin{align}
f(x) &= \sum_{n=0}\infty\frac{f(x_0)}{n!}(x-x_0)^n
\&= f(x_0) +f^{1}(x_0)(x-x_0)+ \frac{f{2}(x_0)}{2}(x-x_0)2 + \cdots + \frac{f{(n)}(x_0)}{n!}(x-x_0)n
\end{align}
$$
还有另外一种常见的写法,$x^{t+1} = x^t + \Delta x$,将$f(x{t+1})$在$xt$处进行泰勒展开,得:
$$\begin{align}
f(x^{t+1}) &= f(x^t) +f{1}(xt)\Delta x+ \frac{f{2}(xt)}{2}\Delta x^2 + \cdots
\end{align}$$
现在,我们去掉常量,然后重新认识一下我们新的目标函数:
$$\sum_{i=1}^n [g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t)$$
定义$I_j = {i|q(x_i)=j}$是叶子 j 的实例集合。
$\Omega(f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2$
将正则项带入,展开目标函数:
$$
\begin{split}\text{obj}^{(t)} &\approx \sum_{i=1}^n [g_i w_{q(x_i)} + \frac{1}{2} h_i w_{q(x_i)}^2] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2\
&= \sum^T_{j=1} [(\sum_{i\in I_j} g_i) w_j + \frac{1}{2} (\sum_{i\in I_j} h_i + \lambda) w_j^2 ] + \gamma T\end{split}$$
看起来有点复杂,令:
$G_j = \sum_{i\in I_j} g_i$,$H_j = \sum_{i\in I_j} h_i$,上式简化为:
$$
\text{obj}^{(t)} = \sum^T_{j=1} [G_jw_j + \frac{1}{2} (H_j+\lambda) w_j^2] +\gamma T
$$
上式中$w_j$是相互独立的,$G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2$是平方项。
对于一个确定的结构$q(x)$,我们可以计算最优的权重$w_j^{\ast}$:
$$
\begin{split}w_j^\ast &= -\frac{G_j}{H_j+\lambda}\
\end{split}
$$
将$w_j{\ast}$带入上式,计算得到的loss最优解${obj}*$:
$$\begin{align}
Obj^{\ (t)} &=\sum_{j=1}^T \left(G_jw_j + \frac{1}{2} (H_j + \lambda) w_j^2\right) +\gamma T\
&=\sum_{j=1}^T \left(- \frac{G_j^2}{H_j+\lambda} + \frac{1}{2} \frac{G_j^2}{H_j+\lambda} \right) +\gamma T\
&=- \frac{1}{2}\sum_{j=1}^T \left({\color{red}{\frac{G_j^2}{H_j+\lambda}} } \right) +\gamma T \tag{2-8}
\end{align}$$
${obj}^*$可以作为一个得分函数(scoring function)来衡量一棵树结构$q(x)$的质量。
我们有了一个方法来衡量一棵树有多好,现在来看XGBoost优化的第二个问题:如何选择哪个特征和特征值进行分裂,使最终我们的损失函数最小?
XGBoost特征选择和切分点选择指标定义为:
$$
\begin{align}
gain=\underbrace{\frac{G_L2}{H_L+\lambda}}_{左节点得分}+\underbrace{\frac{G_R2}{H_R+\lambda}}{右节点得分}-\underbrace{\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}}-\gamma
\end{align}
$$
具体如何分裂?
可以使用完全贪婪算法(exact greedy algorithm),在所有特征上,枚举所有可能的划分。

- 基于当前节点尝试分裂决策树,默认分数score=0,G和H为当前需要分裂的节点的一阶二阶导数之和。
- 对特征序号 k=1,2...K:$G_L=0, H_L=0$
- 将样本按特征k从小到大排列,依次取出第i个样本,依次计算当前样本放入左子树后,左右子树一阶和二阶导数和:
$G_L = G_L+ g_{ti}, G_R=G-G_L$
$H_L = H_L+ h_{ti}, H_R=H-H_L$ - 尝试更新最大的分数:
$$score = max(score, \frac{1}{2}\frac{G_L^2}{H_L + \lambda} + \frac{1}{2}\frac{G_R^2}{H_R+\lambda} - \frac{1}{2}\frac{(G_L+G_R)^2}{H_L+H_R+ \lambda} -\gamma)$$ - 基于最大score对应的划分特征和特征值分裂子树。
- 如果最大score为0,则当前决策树建立完毕,计算所有叶子区域的$w_{tj}$, 得到弱学习器$h_t(x)$,更新强学习器$f_t(x)$,进入下一轮弱学习器迭代.如果最大score不是0,则继续尝试分裂决策树。
原理推导(精简版)
下面是XGBoost原理推导的精简版,方便同学们复习使用。
$$
\begin{align*}
\begin{array}{l}
\text{预测模型: }F(x)=\sum_{i=1}^Tw_if_i(x)\
\text{目标函数: }objt=\sum_{i=1}NL(y_i,F_i^t(x_i))+\Omega(f_t)\
\because obj^t=\sum_{i=1}^NL(y_i,F_i^t(x_i))+\Omega(f_t)\\
~~~~~~~~~=\sum_{i=1}^NL(y_i,F_i^{t-1}(x_i)+w_tf_t(x_i))+\Omega(f_t)\\
\text{由泰勒公式: }f(x+\Delta x)\thickapprox f(x)+\nabla f(x)\Delta x+\frac{1}{2}\nabla^2 f(x)\Delta x^2\\
\therefore obj^t\thickapprox\sum_{i=1}^N[L(y_i,F_i^{t-1}(x_i))+\nabla _{F_{t-1}}L(y_i,F_i^{t-1}(x_i))w_tf_t(x_i)\\
~~~~~~~~~~~~~~~\frac{1}{2}\nabla _{F_{t-1}}^2L(y_i,F_i^{t-1}(x_i))w_t^2f_t^2(x_i)]+\Omega(f_t)\\
\text{令 $g_i=\nabla _{F_{t-1}}L(y_i,F_i^{t-1}(x_i))$}\\
~~~~~~h_i=\nabla _{F_{t-1}}^2L(y_i,F_i^{t-1}(x_i))\\
~~~obj^t\thickapprox \sum_{i=1}^N[L(y_i,F_i^{t-1}(x_i))+g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)\\
\because L(y_i,F_i^{t-1}(x_i)) \text{ 是常量}\\
\therefore \text{目标函数:}\\
~~~obj^t=\sum_{i=1}^N[g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)+C\\
\text{用叶子节点集合以及叶子节点得分表示 ,每个样本都落在一个叶子节点上:}\\
f_t(x)=m_q(x),~~m\in R^T,~~q:R^d\rightarrow\{1,2,3,...,T\}\\
\Omega(f_t)=\gamma T+ \frac{1}{2}\lambda \sum_{i=1}^Tm_j^2,\\
\text{$T$ 是第 $t$ 棵树叶子结点总数}\\
\text{$m_j$ 是第j个叶子结点的权重}\\
\text{定义第 $j$ 个叶子节点所在的样本为 $I_j=\{i|j=q(x_i)\}$}\\
\text{新的目标函数:}\\
obj^t=\sum_{i=1}^N[g_iw_tf_t(x_i)+\frac{1}{2}h_iw_t^2f_t^2(x_i)]+\Omega(f_t)\\
~~~~~~~=\sum_{i=1}^N[g_iw_tm_q(x_i)+\frac{1}{2}h_iw_t^2m_q^2(x_i)]+\gamma T+ \frac{1}{2}\lambda \sum_{i=1}^Tm_j^2\\
~~~~~~~=\sum_{j=1}^T[(\sum_{i \in I_j}g_i)w_tm_j+\frac{1}{2}(\sum_{i \in I_j}h_iw_t^2+\lambda )m_j^2]+\gamma T\\
\text{令: $G_j=\sum_{i \in I_j}g_i$ , $H_j=\sum_{i \in I_j}h_i$ }\\
obj^t=\sum_{j=1}^T[G_jw_tm_j+\frac{1}{2}(H_jw_t^2+\lambda)m_j^2]+\gamma T\\
\text{对二次函数优化问题:}\\
m_j^*=-\frac{G_j^2w_t}{H_jw_t^2+\lambda}\\
obj^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2w_t^2}{H_jw_t^2+\lambda}+\gamma T\\
\text{令 $w_t=1$ :}\\
m_j^*=-\frac{G_j}{H_j+\lambda}\\
obj^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2}{H_j+\lambda}+\gamma T\\
\text{所以当我们新增一个切分点增益为:}\\
gain=\underbrace{\frac{G_L^2}{H_L+\lambda}}_{左节点得分}+\underbrace{\frac{G_R^2}{H_R+\lambda}}_{右节点得分}-\underbrace{\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}}_{切分前得分}-\gamma
\end{array}
\end{align*}
$$
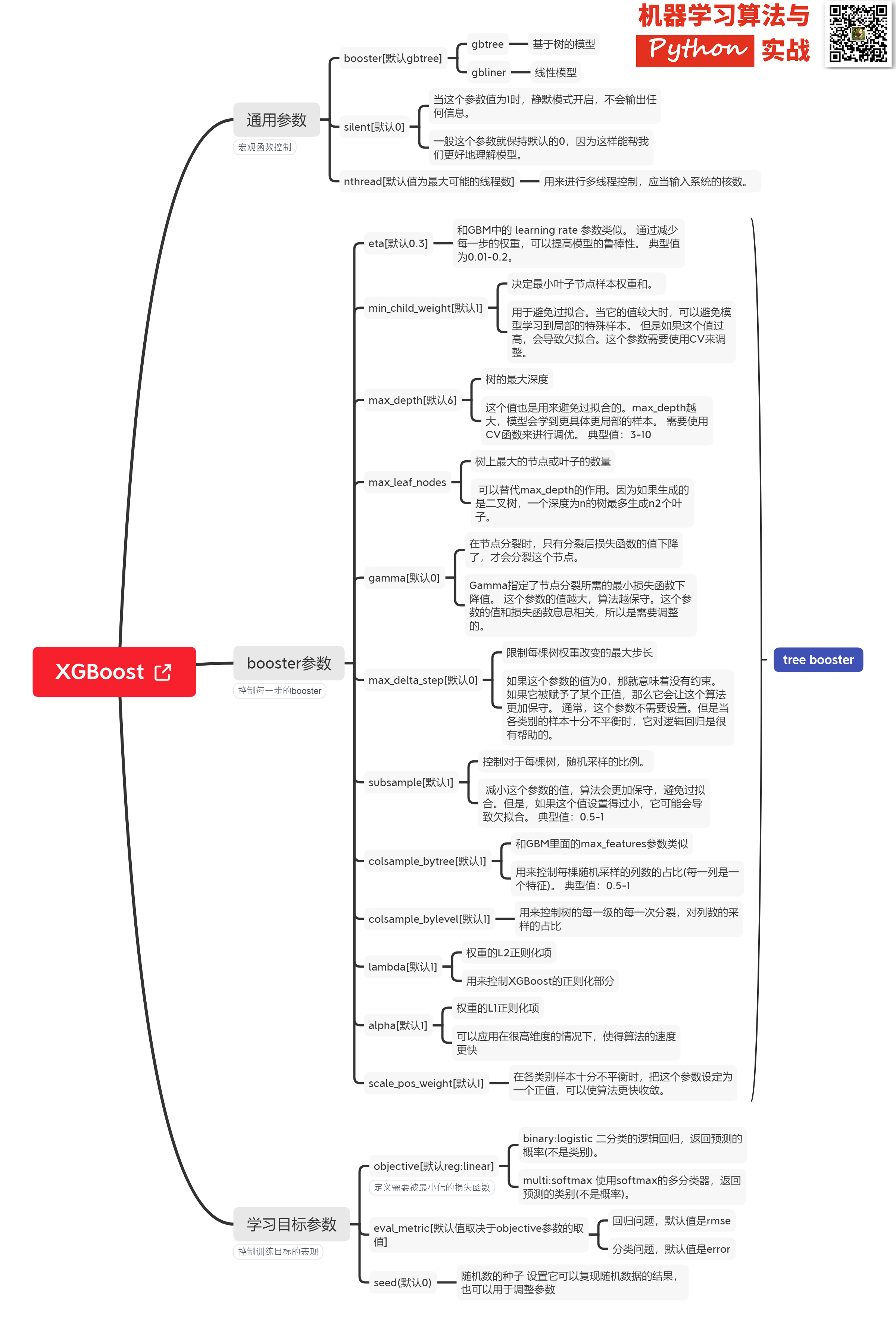
### Xgboost@sklearn模型参数解析
XGBoost的实现有原生版本,同时也有Scikit-learn版本,两者在使用上有一些微差异,这里给出xgboost.sklearn 参数解释。XGBoost使用**key-value**字典的方式存储参数:
```
#部分重要参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
}
```
篇幅原因,调参实例及XGBoost可视化且听下回分解。
如有收获,还请不吝给个**在看、收藏、转发**
## 参考
https://www.cnblogs.com/pinard/p/10979808.html
https://www.biaodianfu.com/xgboost.html
https://www.zybuluo.com/vivounicorn/note/446479
https://www.cnblogs.com/chenjieyouge/p/12026339.html100天搞定机器学习|Day60 遇事不决,XGBoost的更多相关文章
- 100天搞定机器学习|Day22 机器为什么能学习?
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|day40-42 Tensorflow Keras识别猫狗
100天搞定机器学习|1-38天 100天搞定机器学习|day39 Tensorflow Keras手写数字识别 前文我们用keras的Sequential 模型实现mnist手写数字识别,准确率0. ...
- 100天搞定机器学习|Day7 K-NN
最近事情无比之多,换了工作.组队参加了一个比赛.和朋友搞了一些小项目,公号荒废许久.坚持是多么重要,又是多么艰难,目前事情都告一段落,我们继续100天搞定机器学习系列.想要继续做这个是因为,一方面在具 ...
- 100天搞定机器学习|Day11 实现KNN
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day9-12 支持向量机
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 100天搞定机器学习|Day17-18 神奇的逻辑回归
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day21 Beautiful Soup
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
随机推荐
- Element类型&Text类型&Comment类型
Element节点类型 nodetype=1 nodename=大写元素标签名 父节点可以说document 或element 其子节点可以是Element .Text .comment 访问元素 ...
- L2-040 哲哲打游戏
这题读懂题目之后就发现它很呆 #include <bits/stdc++.h> using namespace std; const int N = 100010, M = 110; ve ...
- python数值列表之range()和list()
range() 学习了for循环后,显示数字当然也可以很轻松啦,这个时候我们就可以用到range()函数 for list_2 in range(1, 5): print(list_2) range( ...
- C++ Qt开发:CheckBox多选框组件
Qt 是一个跨平台C++图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍CheckBo ...
- Head First Java学习:第七章-继承和多态
第七章:继承和多态 1. 覆盖(override) 覆盖的意思是由子类重新定义继承下来的方法,以改变或延伸此方法的行为. 2. 继承(extends) 类的成员:实例变量+方法 实例变量无法覆盖是因为 ...
- Python+Selenium+Webdriver+unittest 实现登录126邮箱
第一版:登录 #encoding=utf-8 import unittest import time from selenium import webdriver from selenium.webd ...
- python tkinter使用(九)
python tkinter使用(九) 本文主要讲下scrolledText中图片的插入,以及常见的错误. 使用Image.open来打开图片 使用ImageTk.PhotoImage()方法将图片转 ...
- CENTOS docker拉取私服镜像
概述 docker的应用越来越多,安装部署越来越方便,批量自动化的镜像生成和发布都需要docker镜像的拉取. centos6版本太老,docker的使用过程中问题较多,centos7相对简单容易. ...
- Java 面试题及答案整理(2021最新版)持续更新中~~~
2021年java实习校招秋招春招 后端 知识点及面试题(持续更新) Java面试总结汇总,整理了包括Java基础知识,集合容器,并发编程,JVM,常用开源框架Spring,MyBatis,数据库,中 ...
- Pikachu漏洞靶场 Unsafe Fileupload(文件上传)
Unsafe Fileupload 文章目录 Unsafe Fileupload 1.client check 2.MIME type 3.getimagesize 1.client check 标题 ...