【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
一、爬虫对象-豆瓣读书TOP250
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣读书TOP250排行榜数据:
https://book.douban.com/top250
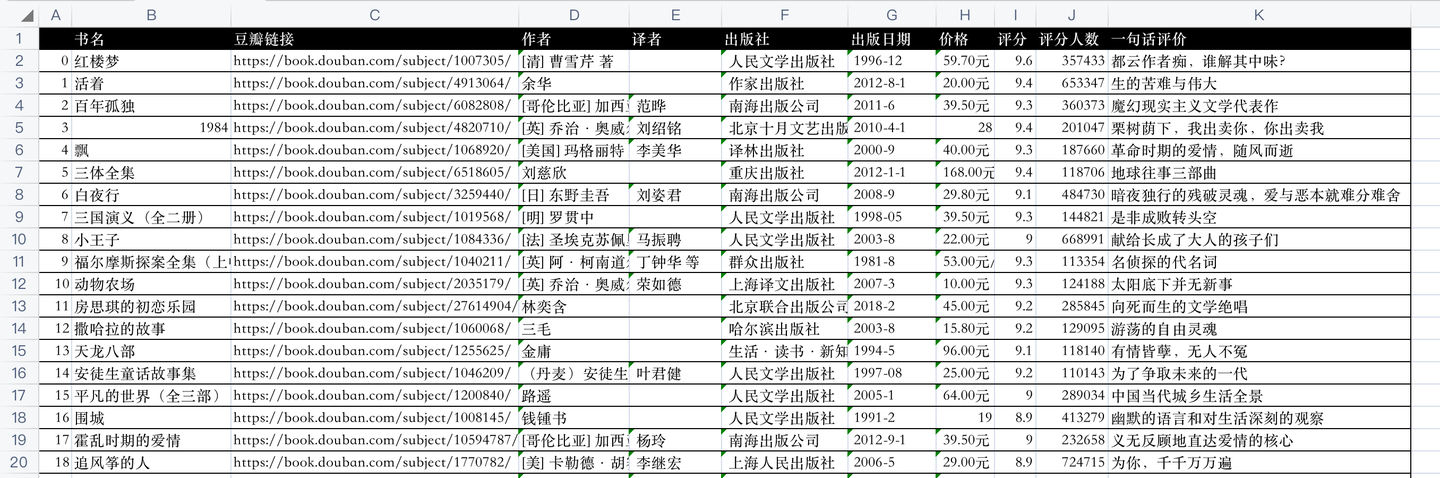
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣读书网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = book.select('.pl2 a')[0]['title'] # 书名
book_name.append(name)
bkurl = book.select('.pl2 a')[0]['href'] # 书籍链接
book_url.append(bkurl)
star = book.select('.rating_nums')[0].text # 书籍评分
book_star.append(star)
star_people = book.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
book_star_people.append(star_people)
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['书名'] = book_name
df['豆瓣链接'] = book_url
df['作者'] = book_author
df['译者'] = book_translater
df['出版社'] = book_publisher
df['出版日期'] = book_pub_year
df['价格'] = book_price
df['评分'] = book_star
df['评分人数'] = book_star_people
df['一句话评价'] = book_comment
df.to_csv(csv_name, encoding='utf8') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
三、讲解视频
同步讲解视频:https://www.zhihu.com/zvideo/1464515550177546240
四、完整源码
附完整源代码:【python爬虫案例】利用python爬虫爬取豆瓣读书TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣读书TOP250排行榜!的更多相关文章
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- 豆瓣读书top250数据爬取与可视化
爬虫–scrapy 题目:根据豆瓣读书top250,根据出版社对书籍数量分类,绘制饼图 搭建环境 import scrapy import numpy as np import pandas as p ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
随机推荐
- 为什么医疗保健需要MFT来帮助保护EHR文件传输
毫无疑问,医疗保健行业需要EHR技术来处理患者,设施,提供者等之间的敏感患者信息.但是,如果没有安全的MFT解决方案,您将无法安全地传输患者文件,从而使您的运营面临遭受数据泄露,尴尬,声誉损失以及随之 ...
- verilog中的数据类型
Verilog中的数据格式 1.基本概念 verilog中写一个数据的通用格式是 n'b000_000_···_000,表示一个n位的二进制数.基于这个通用式,可以将其分为三个部分:位数.加权数和实际 ...
- #KM算法#UVA1411 Ants
题目 在一个平面直角坐标系中,有 \(n\) 个黑点,\(n\) 个白点. 给出一种二分图匹配的方案,使得没有两条由黑白点连接的线段相交 分析 如果线段都不相交,根据三角形的两边之和大于第三边,那么线 ...
- #动态规划,组合计数,树状数组,前缀和#F 简单计数题&K 最简单的题
先膜两位出题人 F 简单计数题 题目 有\(n\)个活动,预约期有\(k\)天,第\(j\)天YC可以获得\(a_j(1\leq a_j\leq n)\)张预约券, 他会在\(n\)个活动中等概率选择 ...
- #线段树分治,线性基,并查集#CF938G Shortest Path Queries
题目 给出一个连通带权无向图,边有边权,要求支持 \(q\) 个操作: \(x\) \(y\) \(d\) 在原图中加入一条 \(x\) 到 \(y\) 权值为 \(b\) 的边 \(x\) \(y\ ...
- #扩展域并查集,线段树分治#CF576E Painting Edges
题目链接 题目翻译 给定一张 \(n\) 个点 \(m\) 条边的无向图. 一共有 \(k\) 种颜色,一开始,每条边都没有颜色. 定义合法状态为仅保留染成 \(k\) 种颜色中的任何一种颜色的边,图 ...
- 【中秋国庆不断更】OpenHarmony组件内状态变量使用:@State装饰器
[中秋国庆不断更]OpenHarmony组件内状态变量使用:@State装饰器 @State装饰的变量,或称为状态变量,一旦变量拥有了状态属性,就和自定义组件的渲染绑定起来.当状态改变时,UI会发生对 ...
- 如何利用OpenHarmony ArkUI的Canvas组件实现涂鸦功能?
简介 ArkUI是一套UI开发框架,提供了开发者进行应用UI开发时所需具备的能力.随着OpenAtom OpenHarmony(以下简称"OpenHarmony")不断更新迭代,A ...
- C++ 条件与 If 语句:掌握逻辑判断与流程控制精髓
C++ 条件和 If 语句 您已经知道 C++ 支持数学中的常见逻辑条件: 小于:a < b 小于或等于:a <= b 大于:a > b 大于或等于:a >= b 等于:a = ...
- RabbitMQ 05 直连模式-Spring Boot操作
Spring Boot集成RabbitMQ是现在主流的操作RabbitMQ的方式. 官方文档:https://docs.spring.io/spring-amqp/docs/current/refer ...