[转帖]Prometheus-使用python开发exporter
exporter有很多,但想要特定需求的话,还需自行开发。在这里使用python写一个exporter,用于监控/root下的目录数量。
开发exporter需要使用prometheus_client库,具体规范可参考:https://github.com/prometheus/client_python ,根据规范可知要想开发一个exporter需要先
1. 定义数据类型,metric,describe(描述),标签
2. 获取数据
3. 传入数据和标签
4. 暴露端口,不断的传入数据和标签
知道了开发的步骤,下边开始实战。
1. 安装prometheus_client库
pip3 install prometheus_client
2. 代码
#!/usr/bin/python3
from prometheus_client import start_http_server,Gauge
import os
import time
#定义数据类型,metric,describe(描述),标签
dir_num = Gauge('dirNum','Calculate the number of directories',['instance'])
def get_dir_num():
#获取目录个数
path = "/root/"
count = 0
for cdir in os.listdir(path):
if os.path.isdir(path+cdir) and not cdir.startswith('.'):
count += 1
#获取主机ip
f = os.popen("hostname -i | awk '{print $2}'")
ip = f.read().strip('\n')
f.close()
dir_num.labels(instance=ip).set(count)
if name == "main":
#暴露端口
start_http_server(8000)
#不断传入数据
while True:
get_dir_num()
time.sleep(10)
3. 创建两个文件

4. 访问
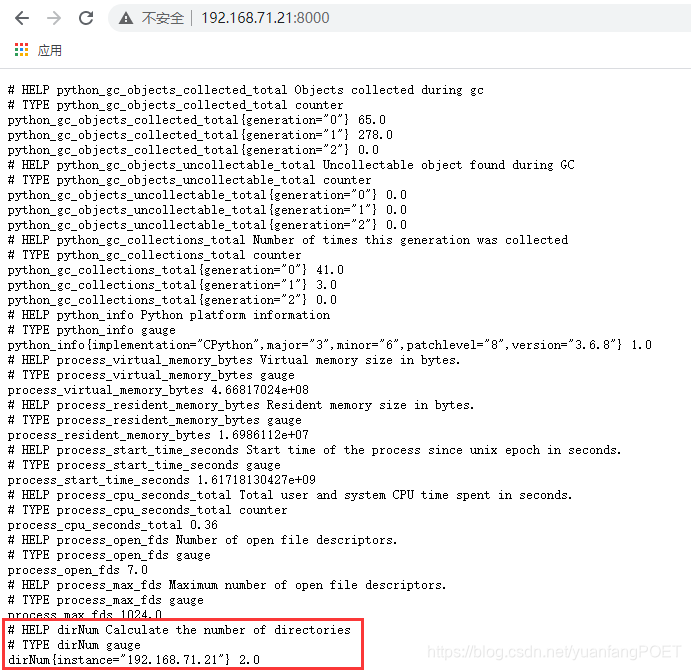
5. python进程托管到supervisord
当然托管到systemd也可以
安装supervisord
yum install supervisor -y
添加子进程配置文件(supervisord默认配置文件为/etc/supervisord.conf,为主进程配置文件,子进程配置文件可在/etc/supervisord.d/下创建,具体可参考https://www.jianshu.com/p/0b9054b33db3)
vim /etc/supervisord.d/dirNum_exporter.ini
[program:dirNum_exporter]
directory=/opt/bin
command=/usr/bin/python3 /opt/bin/dirNum_exporter.py
autostart=true
autorestart=false
startsecs=1
user=root
启动supervisord服务
systemctl start supervisord
查看子进程
[root@prometheus ~]# supervisorctl status
dirNum_exporter RUNNING pid 7458, uptime 0:09:21
- 1
- 2
6. 修改Promehteus配置文件
修改prometheus配置文件
vim /usr/local/prometheus/prometheus.yml
- job_name: "dirNum"
static_configs:
- targets:
- 192.168.71.21:8000
重载服务
curl -X POST http://192.168.71.21:9090/-/reload
查看
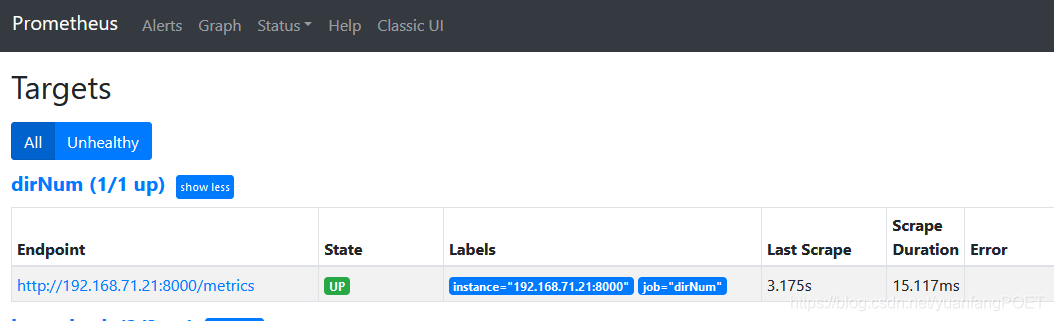
[转帖]Prometheus-使用python开发exporter的更多相关文章
- python开发环境搭建
虽然网上有很多python开发环境搭建的文章,不过重复造轮子还是要的,记录一下过程,方便自己以后配置,也方便正在学习中的同事配置他们的环境. 1.准备好安装包 1)上python官网下载python运 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- Python开发工具PyCharm个性化设置(图解)
Python开发工具PyCharm个性化设置,包括设置默认PyCharm解析器.设置缩进符为制表符.设置IDE皮肤主题等,大家参考使用吧. JetBrains PyCharm Pro 4.5.3 中文 ...
- Python黑帽编程1.2 基于VS Code构建Python开发环境
Python黑帽编程1.2 基于VS Code构建Python开发环境 0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks Atta ...
- Eclipse中Python开发环境搭建
Eclipse中Python开发环境搭建 目 录 1.背景介绍 2.Python安装 3.插件PyDev安装 4.测试Demo演示 一.背景介绍 Eclipse是一款基于Java的可扩展开发平台. ...
- Python开发:环境搭建(python3、PyCharm)
Python开发:环境搭建(python3.PyCharm) python3版本安装 PyCharm使用(完全图解(最新经典))
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
随机推荐
- history详解
linux下history命令详解 如果你经常使用 Linux 命令行,那么使用 history(历史)命令可以有效地提升你的效率.本文将通过实例的方式向你介绍 history 命令的 15 个用法. ...
- ubuntu frame 个人开发心得
引言 有一次我在树莓派上安装 Ubuntu Core 我给创新创业项目开发一个可视化 gui 看板,用于展示数据. 然后我就找到了我需要的工具 Ubuntu Frame 初次尝试使用 Ubuntu F ...
- rime中州韵 输入效果一览 100+增强功能效果
rime是一个定制化程度很高的输入法框架, 我们可以在该框架上搭建适合自己的输入法程序.我们将在专栏 小狼毫 Rime 保姆教程 中完成以下近百种定制化效果的配置与演示.欢迎订阅. 以下为个性化定制的 ...
- 斯坦福 UE4 C++ ActionRoguelike游戏实例教程 06.敲定AI——游戏框架拓展和细节优化
斯坦福课程 UE4 C++ ActionRoguelike游戏实例教程 0.绪论 概述 这篇文章对应课程13课, 50~54节.虽然标题是敲定AI,实际内容和AI关联并不大,主要工作是对游戏内各种细节 ...
- 2023-11-29:用go语言,给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。 需保证 返回结果的字典序最小。 要求不能打乱其他字符的相对位置)。 输入:s = “cba
2023-11-29:用go语言,给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次. 需保证 返回结果的字典序最小. 要求不能打乱其他字符的相对位置). 输入:s = &quo ...
- 详解MRS HBase全局二级索引
本文分享自华为云社区<MRS HBase全局二级索引原理与使用场景>,作者:学习一下大数据 . 一.HBase二级索引背景介绍 HBase是基于Key-Value的分布式存储数据库,对表中 ...
- 华为云GaussDB助力工商银行、华夏银行斩获“十佳卓越实践奖”
近日,2023金融街论坛年会在北京成功举办.活动期间,由北京金融科技产业联盟举办的全球金融科技大会系列活动--分布式数据库金融应用研究与实践大赛获奖结果正式公布.其中,由华为云GaussDB参与支持的 ...
- 云图说|云数据库GaussDB如何做到卓越性能
摘要:对于数据库来说,性能一直被视为最关键的部分.GaussDB作为华为自主创新研发的分布式关系型数据库,那么华为云数据库GaussDB在提升数据库性能方面都有哪些黑科技呢? 本文分享自华为云社区&l ...
- 一文带你了解GaussDB(DWS) 的Roach逻辑备份实现原理
摘要:Roach工具是GaussDB(DWS)推出的一款主力的备份恢复工具,包含物理与逻辑备份两种主要能力,本文着重于讲解Roach逻辑备份的实现原理. 一.简介 在大数据时代,数据的完整和可靠性成为 ...
- 正确理解c# default关键字
背景 最近QA测试一个我开发的一个Web API时,我意识到之前对C#的default的理解一直是想当然的.具体情况是这样,这个API在某些条件下要返回模型的默认值,写法类似于下面这样 [HttpGe ...