使用GPU计算时,单精度float32类型和半精度float16类型运算效率的区别
最近在看资料时发现写着使用float16 半精度类型的数据计算速度要比float32的单精度类型数据计算要快,因为以前没有考虑过数据类型对计算速度的影响,只知道这个会影响最终的计算结果精度。于是,好奇的使用TensorFlow写了些代码,试试看看是否有很大的区别,具体代码如下:
import tensorflow as tf
import time x = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float32))
y = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float32))
#x = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float16))
#y = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float16))
init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init) a = time.time()
for _ in range(500):
sess.run(tf.matmul(x,y))
b = time.time() print(b-a)
上述代码,分别使用单精度或半精度类型的x,y来进行计算。
分别使用RTX titan 和 RTX 2060super 两个类型的显卡分别测试:
RTX titan 显卡环境下:
Float32 , 单精度数据类型的x, y:












RTX titan 显卡环境下:
Float16 , 半精度数据类型的x, y:








-------------------------------------------------------------------------
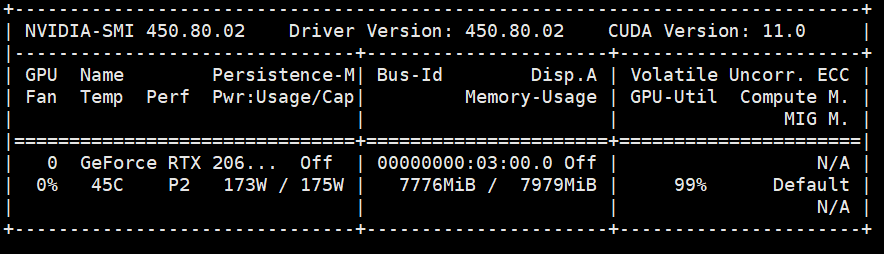
RTX 2060super 显卡环境下:
Float32 , 单精度数据类型的x, y:




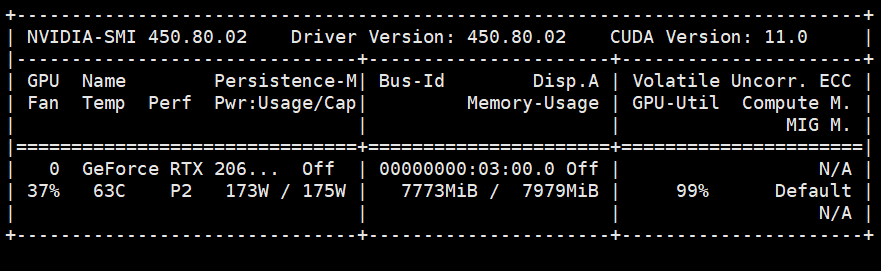
RTX 2060super 显卡环境下:
Float16 , 半精度数据类型的x, y:




======================================================
说下个人的结论:
1. 如果任务需要的计算能力在家用级别显卡的计算能力之下(显卡利用率在100%以内,不考虑显存的前提),那么家用级显卡计算时间不会比服务器级别显卡运算时间长。或者说,如果你的任务使用家用级别显卡可以应付,那么运行时间不会比使用服务器级别显卡的时间长。
2. 服务器级别的显卡运行效率受多方面的条件影响,同一任务多次运行的时间会有一定波动;而家用级别的显卡一般所受影响的方面较少,同一任务多次运行的时间也比较一致。
3.同一个任务可能使用服务器显卡,显卡的利用率可能只有40%,但是使用家用级别的显卡利用率可能就有99%了,证明服务器显卡的性能上限要远高于家用级别显卡。但是如果你的计算任务并没有那么高的计算性能要求,可能使用家用级别的显卡(此时,如果你在超个频啥的,oc版显卡)运算时间很可能要短于服务器级别显卡的运算时间的。
======================
使用GPU计算时,单精度float32类型和半精度float16类型运算效率的区别的更多相关文章
- JAVA中使用浮点数类型计算时,计算精度的问题
标题 在Java中实现浮点数的精确计算 AYellow(原作) 修改 关键字 Java 浮点数 精确计算 问题的提出:如果我们编译运行下面这个程序会看到什么?publi ...
- Julia:高性能 GPU 计算的编程语言
Julia:高性能 GPU 计算的编程语言 0条评论 2017-10-31 18:02 it168网站 原创 作者: 编译|田晓旭 编辑: 田晓旭 [IT168 评论]Julia是一种用于数学计 ...
- GPU计算的后CUDA时代-OpenACC(转)
在西雅图超级计算大会(SC11)上发布了新的基于指令的加速器并行编程标准,既OpenACC.这个开发标准的目的是让更多的编程人员可以用到GPU计算,同时计算结果可以跨加速器使用,甚至能用在多核CPU上 ...
- 基于Flink秒级计算时CPU监控图表数据中断问题
基于Flink进行秒级计算时,发现监控图表中CPU有数据中断现象,通过一段时间的跟踪定位,该问题目前已得到有效解决,以下是解决思路: 一.问题现象 以SQL02为例,发现本来10秒一 ...
- GPU计算的十大质疑—GPU计算再思考
http://blog.csdn.NET/babyfacer/article/details/6902985 原文链接:http://www.hpcwire.com/hpcwire/2011-06-0 ...
- 使用Deeplearning4j进行GPU训练时,出错的解决方法
一.问题 使用deeplearning4j进行GPU训练时,可能会出现java.lang.UnsatisfiedLinkError: no jnicudnn in java.library.path错 ...
- OpenGL实现通用GPU计算概述
可能比較早一点做GPU计算的开发者会对OpenGL做通用GPU计算,随着GPU计算技术的兴起,越来越多的技术出现,比方OpenCL.CUDA.OpenAcc等,这些都是专门用来做并行计算的标准或者说接 ...
- 14、Java中用浮点型数据Float和Double进行精确计算时的精度问题
一.浮点计算中发生精度丢失 大概很多有编程经验的朋友都对这个问题不陌生了:无论你使用的是什么编程语言,在使用浮点型数据进行精确计算时,你都有可能遇到计算结果出错的情况.来看下面的例子. // 这是一个 ...
- (Matlab)GPU计算简介,及其与CPU计算性能的比较
1.GPU与CPU结构上的对比 2.GPU能加速我的应用程序吗? 3.GPU与CPU在计算效率上的对比 4.利用Matlab进行GPU计算的一般流程 5.GPU计算的硬件.软件配置 5.1 硬件及驱动 ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
随机推荐
- 卷积神经网络-AlexNet
AlexNet 一些前置知识 top-1 和top-5错误率 top-1错误率指的是在最后的n哥预测结果中,只有预测概率最大对应的类别是正确答案才算预测正确. top-5错误率指的是在最后的n个预测结 ...
- SpringBoot 过滤器更改 Request body ,并实现数据解密
客户端.服务端网络通信,为了安全,会对报文数据进行加解密操作. 在SpringBoot项目中,最好使用参考AOP思想,加解密与Controller业务逻辑解耦,互不影响. 以解密为例:需要在reque ...
- Linux 内核:设备驱动模型 学习总结
背景 其实之前就转载过别人针对Linux的设备驱动模型(Linux Device Driver Model,LDDM)的文章,但是受限于自身的能力,因此花了点时间重新学习了一下. 前人写的文章很好,我 ...
- MyBase 7.1 可用的 Markdown 配置表
背景 找到了一款Markdown 笔记本软件MyBase,7.1版本支持markdown,所以我非常喜欢,修改了自己博客的css到软件里面,瞬间变得好看了. 效果图 设置方法 "工具 - 编 ...
- Spark内核架构核心组件.txt
1.Application2.spark-submit3.Driver4.SparkContext5.Master6.Worker7.Executor8.Job9.DAGScheduler10.Tas ...
- C#多态性学习,虚方法、抽象方法、接口等用法举例
1. 多态性定义 C#中的多态性是OOP(面向对象编程)的一个基本概念,它允许一个对象在不同情况下表现出不同的行为,以增强代码的可重用性和灵活性. 根据网上的教程,我们得知C#多态性分为两类, ...
- win11 vmware16 启动虚拟机引起蓝屏
前言 在win11 上安装 vmware16, 之后安装ubuntu16时,一打开ubuntu虚拟机就触发系统蓝屏. 正文 我改了两个地方: 控制面板->程序->启用或关闭Windows功 ...
- Oracle 锁表查询和解锁方法
system登录 查询被锁表信息 select sess.sid, sess.serial#, lo.oracle_username, lo.os_user_name, ao.object_name, ...
- 算法金 | DL 骚操作扫盲,神经网络设计与选择、参数初始化与优化、学习率调整与正则化、Loss Function、Bad Gradient
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 今日 216/10000 抱个拳,送个礼 神经网络设计与选择 参数初始化与优化 学习率 ...
- 国产开源存储之光:Curve 通过信创认证
网易数帆喜讯再传,Curve 近日通过信息技术应用创新(信创)认证! Curve 是一款高性能.易运维.云原生的分布式存储系统,由网易数帆存储团队发起开源,现为 CNCF 沙箱项目.国家工业信息安全发 ...