mapreduce的shuffle机制
1.1 概述:
mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;(从map的输出到reduce的输入)
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
1.2 主要流程:
Shuffle缓存流程:
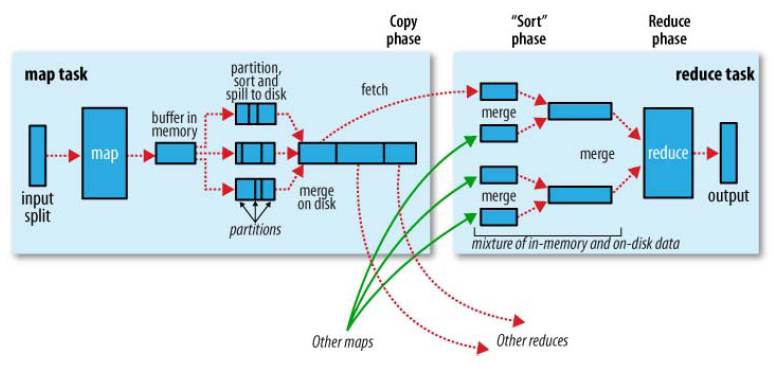
Buffer in memory:内存缓冲区
Partition:分区
Sort:分类
Spill to disk:切片到磁盘
Merge on disk:合并到磁盘
Fetch:拿来,拿取
Copy phase:复制阶段
Mixture of in-memory and on-disk data:内存和磁盘数据的混合
(可以看出一个maptask可以对应多个reducetask)
shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的,整体来看,分为3个操作:
1、分区partition
2、Sort根据key排序
3、Combiner进行局部value的合并
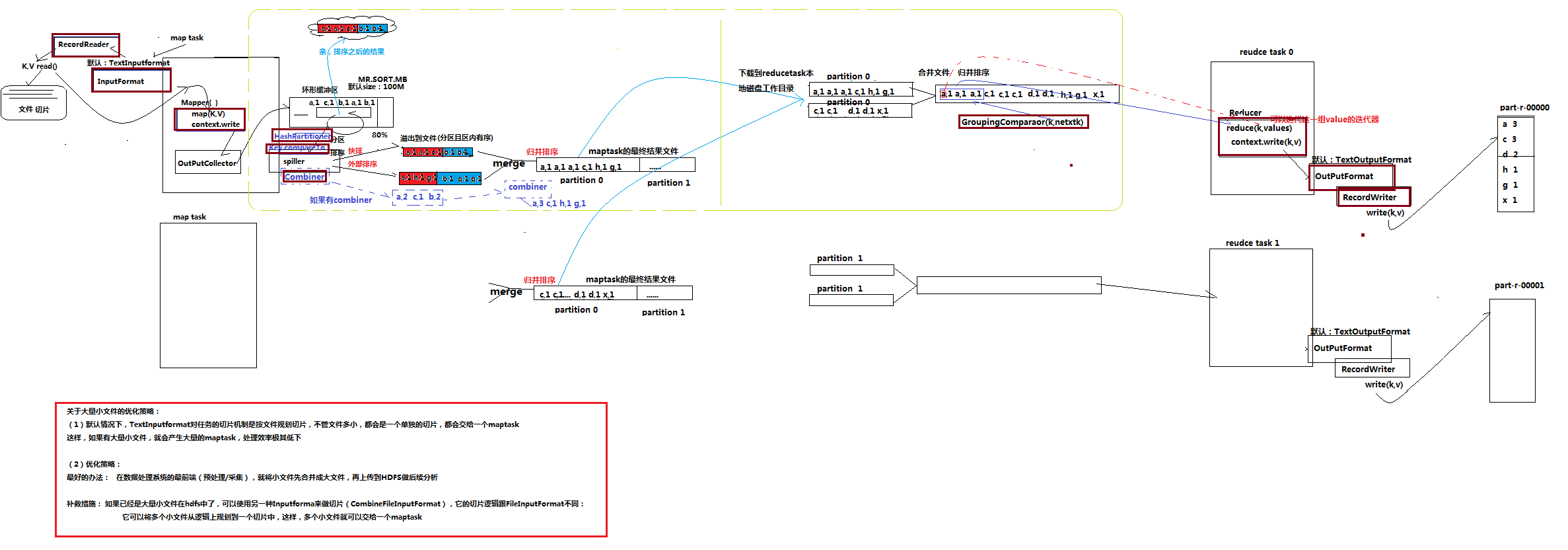
1.3 详细流程
1、 maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
(环形缓冲区默认100M)
2、 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(经过patition分区,key的compareto方法,经过排序,由combiner合并同key键值对,再经过快排/外部排序,溢出到文件)
3、 多个溢出文件会被合并成大的溢出文件
(经过merge文件合并,归并排序,得到maptask的最终结果文件)
------------------------------------------------------------------------------------------------------------
4、 在溢出过程,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5、 reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6、 reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)(一个reducetask可以对应多个maptask,两者是多对多)
7、 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
1.4 详细流程示意图
mapreduce的shuffle机制的更多相关文章
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- MapReduce原理——Shuffle机制
在Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle. Map方法输出的数据会获得对应的分区,进入环形缓冲区(缓冲区一半写索引,另一半写数据).数据达到缓冲区的80%会发生溢写.在 ...
- 【待完成】[MapReduce_9] MapReduce 的 Shuffle 机制
0. 说明 待补充...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
随机推荐
- 莫队算法(基础莫队)小结(也做markdown测试)
莫队 基础莫队 本质是通过排序优化了普通尺取法的时间复杂度. 考虑如果某一列询问的右端点是递增的,那么我们更新答案的时候,右指针只会从左往右移动,那么i指针的移动次数是$O(n)$的. 当然,我们不可 ...
- Django国际化与本地化指南
title: Django国际化与本地化指南 date: 2024/5/12 16:51:04 updated: 2024/5/12 16:51:04 categories: 后端开发 tags: D ...
- linux time测试命令的运行时间
在linux中,time命令是用来测试命令的运行时间的,命令的运行时间有三种: real:实际使用时间,该时间包括进程执行时实际使用的 CPU 时间,进程耗费在阻塞上的时间(如等待完成 I/O 操 ...
- 阿里巴巴 MySQL 数据库之索引规约 (二)
索引规约 强制部分 [强制] 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引. 说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的:另外 ...
- Newtonsoft.Json解决中文编码问题
Newtonsoft.Json解决中文编码 默认Newtonsoft.Json序列化对象后,返回的中文未进行编码. 需要将编码转换的话,需要 1 2 3 4 5 6 7 var json = Json ...
- ASP.NET Core SignalR .NET 客户端
项目 2022/11/29 13 个参与者 反馈 通过 ASP.NET Core SignalR .NET 客户端库可以从 .NET 应用与 SignalR 中心进行通信. 查看或下载示例代码(如何下 ...
- Flutter(六):Flutter_Boost接入现有原生工程(iOS+Android)
本篇博客会介绍如何通过第三方插件Flutter_Boost实现接入原有工程. 如果不希望引入第三方插件,可以参考博客Flutter混合开发--接入现有原生工程(iOS+Android) 一.新建原生工 ...
- 8.16考试总结(NOIP模拟41)[你相信引力吗·marshland·party?·半夜]
美丽的不是这个世界,而是看世界的你的眼神. T1 你相信引力吗 解题思路 好像只有我一个人没有看出来这个题是单调栈(现在一看区间问题就是双指针,线段树) 维护一个单调递减的栈. 我们把最大值放到左端点 ...
- 一文了解JVM(中)
HotSpot 虚拟机对象探秘 对象的创建 Header 解释 使用 new 关键字 调用了构造函数 使用 Class 的 newInstance 方法 调用了构造函数 使用 Constructor ...
- Linux Shell命令提示样式修改
对linux shell命令样式进行美化. 修改前的效果: 修改后的效果: 直接给出.bashrc脚本代码: 1 # ~/.bashrc: executed by bash(1) for non-lo ...