Diffusers实战
Smiling & Weeping
---- 一生拥有自由和爱,是我全部的野心
1. 环境准备
%pip install diffusers
from huggingface_hub import notebook_login # 登录huggingface
notebook_login()
import numpy as np
import torch
import torch.nn.functional as F
from matplotlib import pyplot as plt
import torchvision
from PIL import Image
def show_images(x):
"""给定一批图像,创建一个网格并将其转换成PIL"""
x = x*0.5 + 0.5
grid = torchvision.utils.make_grid(x)
grid_im = grid.detach().cpu().permute(1, 2, 0).clip(0, 1)*255
grad_im = Image.fromarray(np.array(grid_im).astype(np.uint8))
return grad_im
def make_grid(images, size=64):
"""给定一个PIL图像列表,将他们叠加成一行以便查看"""
output_im = Image.new("RGB", (size*len(images), size))
for i, im in enumerate(images):
out_im.paste(im.resize((size, size)), (i*size, 0))
return output_im
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
from diffusers import DDPMPipeline, StableDiffusionPipeline model_id = "sd-dreambooth-library/mr-potato-head"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to(device)
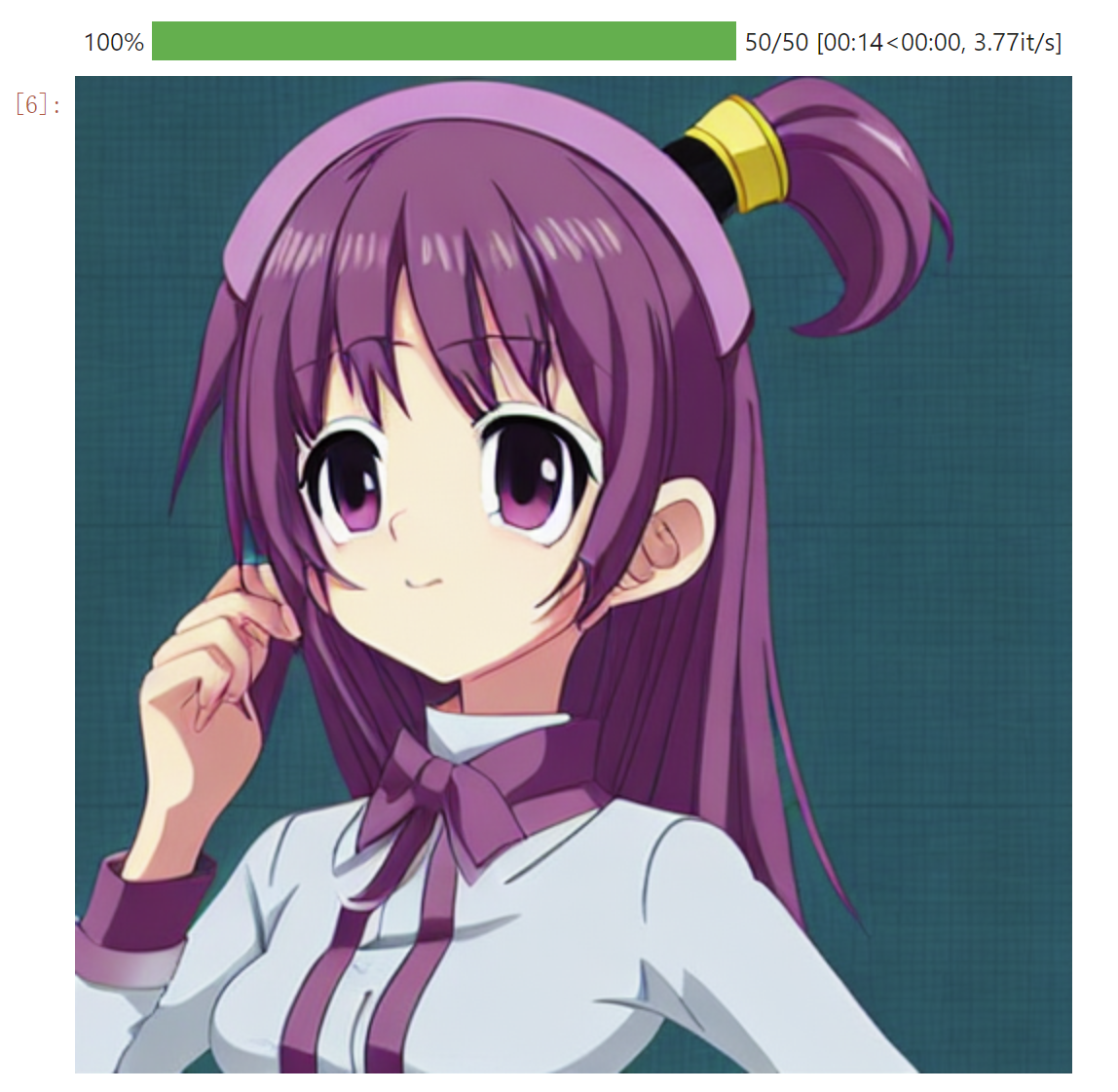
prompt = "a cute anime characters using 8K resolution"
image = pipe(prompt, num_inference_steps=50, guidance_scale=5.5).images[0]
image
Diffusers核心API:
- 管线:从高层次设计的多种类函数,便于部署的方式实现,能够快速利用预训练的主流扩散模型来生成样本。
- 模型:在训练新的扩散模型时需要用到的网络结构。
- 调度器:在推理过程中使用多种不同的技巧来从噪声中生成图像,同时可以生成训练过程中所需的“带噪”图像。
import torchvision
from datasets import load_dataset
from torchvision import transforms
from diffusers import DDPMScheduler
from diffusers import DDPMPipeline, StableDiffusionPipeline dataset = load_dataset('lowres/anime', split="train") image_size = 256
batch_size = 8 preprocess = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.RandomHorizontalFlip(),
transforms.Normalize([0.5], [0.5]),
]) def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images} dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
xb = next(iter(train_dataloader))['images'].to(device)[:8]
print("X shape:", xb.shape)
show_images(xb).resize((8*256, 256), resample=Image.NEAREST)

# 定义调度器
from diffusers import DDPMScheduler noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_start=0.001, beta_end=0.004)
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.rand_like(xb)
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print("Noise X Shape", noisy_xb.shape)
show_images(noisy_xb).resize((8*64, 64), resample=Image.NEAREST)
from diffusers import UNet2DModel model = UNet2DModel(
sample_size=image_size, # 目标图像的分辨率
in_channels=3,
out_channels=3,
layers_per_block=2, # 每一个UNet块中的ResNet层数
block_out_channels=(64, 128, 128, 256),
down_block_types=(
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # 带有空域维度的self-att的ResNet下采样模块
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # 带有空域维度的self-att的ResNet上采样模块
"UpBlock2D",
"UpBlock2D",
),
) model = model.to(device)
with torch.no_grad():
model_pred = model(noisy_xb, timesteps).sample model_pred.shape
训练
# 设定噪声调度器
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule="squaredcos_cap_v2") # 训练循环
optimizer = torch.optim.Adam(model.parameters(), lr=4e-4) losses = [] # 定义损失函数
loss_fn = torch.nn.MSELoss() for epoch in range(45):
for step, batch in enumerate(train_dataloader):
# 未添加噪声的数据(clean data)
clean_data = batch['images'].to(device) # 生成噪声
noise = torch.randn(clean_data.shape).to(device)
bs = clean_data.shape[0] # 为每张图片随机采样一个时间步
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bs, ), device=device).long() # 噪声数据
# 根据每个时间步的噪声幅度(迭代次数),向清晰的图片中添加噪声
noisy_data = noise_scheduler.add_noise(clean_data, noise, timesteps) # 获得预测模型
pred_data = model(noisy_data, timesteps, return_dict=False)[0] # 计算损失
loss = loss_fn(pred_data, clean_data)
loss.backward()
losses.append(loss.item()) # 迭代模型参数
optimizer.step()
optimizer.zero_grad() if (epoch+1) % 5 == 0:
loss_last_epoch = sum(losses[-len(train_dataloader):]) / len(train_dataloader)
print(f"Epoch: {epoch+1}, loss: {loss_last_epoch}")
torch.save(model.state_dict(), 'save.pt')
绘制损失图线
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
axs[0].plot(losses)
axs[1].plot(np.log(losses))
plt.show()
Diffusers实战的更多相关文章
- SSH实战 · 唯唯乐购项目(上)
前台需求分析 一:用户模块 注册 前台JS校验 使用AJAX完成对用户名(邮箱)的异步校验 后台Struts2校验 验证码 发送激活邮件 将用户信息存入到数据库 激活 点击激活邮件中的链接完成激活 根 ...
- GitHub实战系列汇总篇
基础: 1.GitHub实战系列~1.环境部署+创建第一个文件 2015-12-9 http://www.cnblogs.com/dunitian/p/5034624.html 2.GitHub实战系 ...
- MySQL 系列(四)主从复制、备份恢复方案生产环境实战
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 第三篇:MySQL 系列(三)你不知道的 视图.触发器.存储过程.函数 ...
- Asp.Net Core 项目实战之权限管理系统(4) 依赖注入、仓储、服务的多项目分层实现
0 Asp.Net Core 项目实战之权限管理系统(0) 无中生有 1 Asp.Net Core 项目实战之权限管理系统(1) 使用AdminLTE搭建前端 2 Asp.Net Core 项目实战之 ...
- 给缺少Python项目实战经验的人
我们在学习过程中最容易犯的一个错误就是:看的多动手的少,特别是对于一些项目的开发学习就更少了! 没有一个完整的项目开发过程,是不会对整个开发流程以及理论知识有牢固的认知的,对于怎样将所学的理论知识应用 ...
- asp.net core 实战之 redis 负载均衡和"高可用"实现
1.概述 分布式系统缓存已经变得不可或缺,本文主要阐述如何实现redis主从复制集群的负载均衡,以及 redis的"高可用"实现, 呵呵双引号的"高可用"并不是 ...
- Linux实战教学笔记08:Linux 文件的属性(上半部分)
第八节 Linux 文件的属性(上半部分) 标签(空格分隔):Linux实战教学笔记 第1章 Linux中的文件 1.1 文件属性概述(ls -lhi) linux里一切皆文件 Linux系统中的文件 ...
- Linux实战教学笔记07:Linux系统目录结构介绍
第七节 Linux系统目录结构介绍 标签(空格分隔):Linux实战教学笔记 第1章 前言 windows目录结构 C:\windows D:\Program Files E:\你懂的\精品 F:\你 ...
- Linux实战教学笔记06:Linux系统基础优化
第六节 Linux系统基础优化 标签(空格分隔):Linux实战教学笔记-陈思齐 第1章 基础环境 第2章 使用网易163镜像做yum源 默认国外的yum源速度很慢,所以换成国内的. 第一步:先备份 ...
- Linux实战教学笔记05:远程SSH连接服务与基本排错(新手扫盲篇)
第五节 远程SSH连接服务与基本排错 标签(空格分隔):Linux实战教学笔记-陈思齐 第1章 远程连接LInux系统管理 1.1 为什么要远程连接Linux系统 在实际的工作场景中,虚拟机界面或物理 ...
随机推荐
- 【实践案例】Databricks 数据洞察 Delta Lake 在基智科技(STEPONE)的应用实践
简介: 获取更详细的 Databricks 数据洞察相关信息,可至产品详情页查看:https://www.aliyun.com/product/bigdata/spark 作者 高爽,基智科技数据中心 ...
- [FAQ] Error 1142: INDEX command denied to user
MySQL 用户没有某个命令权限时提示的错误.具体这里提示的是没有 index 命令权限. 把某库的所有表的 index 命令授权给用户即可: grant index on xxdb.* to 'xx ...
- dotnet 5 的 bin 文件夹下的 ref 文件夹是做什么用的
本文来和大家聊聊在 dotnet 5 和 dotnet 6 或更高版本的 dotnet 构建完成,在 bin 文件夹下,输出的 ref 文件夹.在此文件夹里面,将会包含项目程序集同名的 dll 文件, ...
- 实验2 C语言分支与循环基础应用编程 王刚202383310053
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<time.h> 4 #define N 5 5 int ma ...
- EPAI手绘建模APP资源管理和模型编辑器2
g) 矩形 图 26模型编辑器-矩形 i. 修改矩形的中心位置. ii. 修改矩形的长度和宽度. h) 正多边形 图 27模型编辑器-内接正多边形 图 28模型编辑器-外切正多边形 i. 修改正多 ...
- 2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k。 要进行分割操作,直到字符串s为空: 选择s的最长前缀,该前缀最多包含k个不同字符; 删除该前缀,递增分割计数。如果有剩余
2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k. 要进行分割操作,直到字符串s为空: 选择s的最长前缀,该前缀最多包含k个不同字符: 删除该前缀,递增分割计数.如果有剩余 ...
- 简说Python之flask初体验
目录 flask初体验 1.安装Flask 2.创建"Hello, World" Flask应用 3.执行结果 flask是python web的轻量框架,简单的几条命令就可以创建 ...
- HTML link标签中preload,prefetch,dns-prefetch,preconnect,prerender
Preload 在我们的浏览器加载资源的时候,对于每一个资源都有其自身的默认优先级,倘若我们能修改每一个资源的默认优先级,那我们几乎可以按照我们的预期加载想要加载的资源. 以谷歌浏览器为例,我们打开控 ...
- uniAPP Android平台完整更新与热更新
一.概述 1.uni-app打包成apk或wgt文件,使用plus.runtime.getProperty方法获取本地应用资源版本号.2.调用后端接口,拿到与后端规定好的版本号,与前面获取的版本号进行 ...
- 简易的 Linux 流量实时监控工具 watch+ifstat
非常简单小巧的流量实时监控工具,贵在不需要安装,Linux 操作系统自带,在不出外网的环境中很是实用. watch -d ifstat eth1 如果连 ifstat 都没有的环境中也可以使用 ifc ...