Spark Structured Streaming(二)实战
5. 实战Structured Streaming
5.1. Static版本
先读一份static 数据:
val static = spark.read.json("s3://xxx/data/activity-data/")
static.printSchema
root
|-- Arrival_Time: long (nullable = true
|-- Creation_Time: long (nullable = true)
|-- Device: string (nullable = true)
|-- Index: long (nullable = true)
|-- Model: string (nullable = true)
|-- User: string (nullable = true)
|-- gt: string (nullable = true)
|-- x: double (nullable = true)
|-- y: double (nullable = true)
|-- z: double (nullable = true)
看一下部分内容:

5.2. Streaming 版本
下面我们使用同样的数据集创建一个streaming 版本,在流的情况下,它会一个接一个地读取每个输入文件。
Streaming DataFrames与static DataFrame基本一致,基本上,所有static DF中的transformation都可以应用在Streaming DF中。不过,一个小小的区别是:Structured Streaming并不允许我们执行schema 推断(inference),除非显式地启用此功能。可以通过设置spark.sql.streaming.schemaInference 为 true来开启schema inference。在这个例子中,我们会读取一个文件的schema(当然我们已知了这些文件具有有效的schema),并从static DF中pass一个dataSchema对象到streaming DF中。不过在实际中一般要避免这么做,因为数据可能是会改变的。
val dataSchema = static.schema
val streaming = spark.readStream.schema(dataSchema).option("maxFilesPerTrigger", 1).json("s3://tang-spark/data/activity-data")
(这里我们指定了maxFilesPerTrigger为1,仅是为了测试方便,让stream一次读一个文件,但是一般在生产环境中不会配置这么低。)
与其他Spark API 一样,streaming DataFrame 的创建以及执行是lazy的。现在我们可以为streaming DF指定一个transformation,最后调用一个action开始执行这个流。在这个例子中,我们会展示一个简单的transformation —— 根据字段gt,进行group 并 count:
val activityCounts = streaming.groupBy("gt").count()
若是使用的单机模式,也可以设置一个更小的spark.sql.shuffle.partitions 值(默认为200,Configures the number of partitions to use when shuffling data for joins or aggregations.),以避免创建过多的shuffle partitions:
spark.conf.set("spark.sql.shuffle.partitions", 5)
现在我们已经设置好了transformation,下一步仅需要指定一个action就可以开始执行query了。根据上文所述,我们还需要指定一个输出的destination,或是针对这个query结果的output sink。对于这个简单的例子,我们会使用memory sink,它会维护一个在内存中的一个table of the results。
在指定sink时,我们还需要定义Spark如何输出它的数据,在这个例子中,我们会使用complete 的输出模式。这个模式会在每次trigger后,重写所有的keys以及它们的counts值:
val activityQuery = activityCounts.writeStream.queryName("activity_counts").format("memory").outputMode("complete").start()
在我们运行上面的代码前,我们也要加上这条代码:
activityQuery.awaitTermination()
在这条代码开始运行后,streaming 计算将会在后台运行。而这个query object即是active streaming query 对应的handle,而我们必须使用activityQuery.awaitTermination() 等待query的结束,以防止driver进程在query仍是active时退出。在生产环境中必须要加上这条语句,否则stream无法执行。
开始执行:
[Stage 8:==========================> (94 + 4) / 200]
可以看到有 200 个task,因为使用的是默认的 spark.sql.shuffle.partitions 值。
可以使用 spark.streams.active 列出active的stream:
> spark.streams.active res24: Array[org.apache.spark.sql.streaming.StreamingQuery] = Array(org.apache.spark.sql.execution.streaming.StreamingQueryWrapper@612c6083)
它也会为每个stream分配一个UUID,所以如果有必要的话,可以迭代这个list,并选出上面的那个流。不过在这个例子中,我们已经将这个流assign给一个变量了,所以没有必要。
现在这个流正在运行,我们可以通过query这个in-memory table来检查结果,这个表维护了当前streaming aggregation的输出。这个table将被称为 activity_counts,与流的名称一样。在检查当前output table 的输出时,仅需要query此表即可。我们会写一个循环,每秒打出这个streaming query 的结果:
for (i <- 1 to 5){
spark.sql("select * from activity_counts").show()
Thread.sleep(1000)
}
结果类似于:
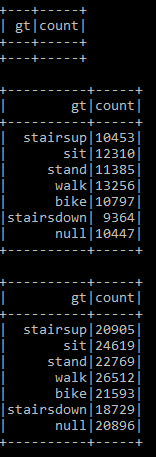
整体语句为:
val static = spark.read.json("s3://tang-spark/data/activity-data/")
val dataSchema = static.schema
val streaming = spark.readStream.schema(dataSchema).option("maxFilesPerTrigger", 1).json("s3://tang-spark/data/activity-data")
val activityCounts = streaming.groupBy("gt").count()
val activityQuery = activityCounts.writeStream.queryName("activity_counts").format("memory").outputMode("complete").start()
for (i <- 1 to 5){
spark.sql("select * from activity_counts").show()
Thread.sleep(1000)
}
6. Streams 中的 Transformations
Streaming中的transformations 基本涵盖了static DF 中的 transformations,例如select、filter等简单的transformations。不过仍是有些限制,例如在Spark 2.2 版本中,用户无法sort一个没有aggregated的stream,并且在没有使用Stateful Processing时,无法执行多层的aggregation,等等。这些限制可能会随着版本更替有所解决,对此最好参考Spark的官方文档,查看更新情况。
6.1. Selections and Filtering
在Structured Streaming中,支持所有的select 与 filter。下面是一个简单的例子,由于我们并不会随着时间更新key,所以会使用Append output mode,将新数据append到输出表中:
import org.apache.spark.sql.functions.expr
val simpleTransform = streaming.withColumn("stairs", expr("gt like '%stairs%'"))
.where("stairs")
.where("gt is not null")
.select("gt", "model", "arrival_time", "creation_time")
.writeStream
.queryName("simple_transform")
.format("memory")
.outputMode("append")
.start()
下面查询一下,先可以看看有哪些表:

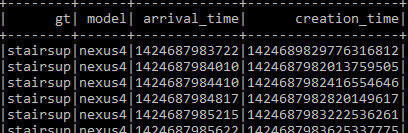
然后查询 simple_transform 表:
spark.sql("select * from simple_transform").show()
6.2. Aggregations
Structured Streaming 对 aggregation操作的支持非常好。我们可以指定任意聚合操作。例如,我们可以使用一个比较有特点的聚合(例如Cube),在sensor的phone model 、activity、以及average x,y,z acceleration 字段上聚合Cube:
val deviceModelStats = streaming.cube("gt", "model").avg()
.drop("avg(Arrival_time)")
.drop("avg(Creation_Time)")
.drop("avg(Index)")
.writeStream.queryName("device_counts").format("memory").outputMode("complete")
.start()
spark.sql("select * from device_counts").show()
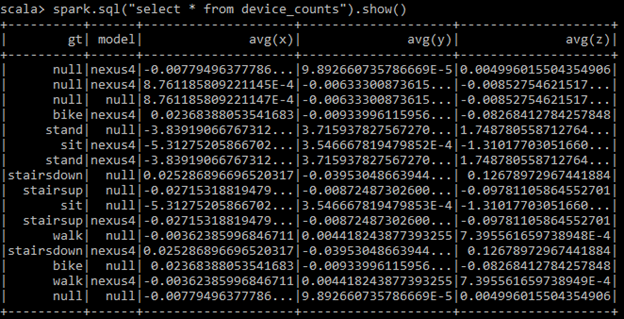
相信大家已经发现了,这里queryName(“device_counts”) 也就是我们最后生成的表名。
6.3. Joins
在Spark 2.2 版本以后,Structured Streaming支持streaming DataFrames 与 static DataFrames进行join。Spark 2.3 会增加多个streams 的join 功能。
val historicalAgg = static.groupBy("gt", "model").avg()
val deviceModelStats = streaming.drop("Arrival_Time", "Creation_Time", "Index")
.cube("gt", "model").avg()
.join(historicalAgg, Seq("gt", "model"))
.writeStream.queryName("device_counts_join").format("memory").outputMode("complete")
.start()
spark.sql("select * from device_counts_join").show()

在Spark 2.2 中,full outer join、left join(stream在右)、right join(stream在左)暂不支持。Structured Streaming 也还没有支持stream-to-stream 的join,不过这个也是一个正在开发中的功能。
7. Input 与 Output
这节我们会深入讨论,在Structured Streaming 中,sources、sinks以及output modes 是如何工作的。特别地,我们会讨论数据流是怎样、何时、从哪,进入以及流出系统。
下面讨论的source 与 sink 都是端到端相同的情况一起讨论的,当然端到端也可以是不一样的(例如source 是kafka,sink 是file)
7.1. 数据在哪读写(Sources 与 Sinks)
Structured Streaming 支持多个production sources 与 sinks(files 以及Kafka),以及一些debug 工具(例如memory table sink)。我们之前已经介绍过这些,现在进一步讨论。
File Source 与 Sink
可能能想到的最简单的source就是file source,基本上我们能想到的所有文件类型都适用,如Parquet、text、JSON、CSV等。
在Spark static file source 与Structured Streaming file source 中,它们唯一的区别就是:在streaming 中,我们可以控制每次trigger中读入的文件数,通过maxFilesPerTriger选项即可。
需要注意的是,任何添加到Streaming input 目录中的文件,都必须是原子的。否则,在你写入完成前,Spark会partially 处理文件。在如本地文件系统或是HDFS这种允许partial write 文件系统中,最好是在外部文件夹写完文件后,再移动到 input 目录中。在Amazon S3 中,对象一般仅在fully writes 后才可被访问。
Kafka Source 与 Sink
Kafka 是一个分布式的publish-and-subscribe 系统,它可以像一个消息队列一样,让我们可以publish records 到流中。可以将Kafka 认作为一个分布式的buffer,它让我们在某个类别中(topic)存储流中的records。
读Kafka Source
在读kafka 时,需要选择一种选项:assign,subscribe,或是subscribePattern。在读Kafka时,只能选择其中一种选项。
- Assign :是一种细粒度的配置模式,不仅需要指定topic,还需要指定你想要读的topic 的partitions。这个通过一个JSON string来配置,例如{“topicA”: [0, 1], “topicB”: [2, 4]}。
- Subscribe与SubscribePattern:是用于subscribe 一个或多个topics 的模式,可以指定一个list(subscribe),或是一个pattern(subscribePattern)
然后,我们还需要指定kafka.bootstrap.servers,除此之外,还有其他几个options需要指定:
- StartingOffsets 与 endingOffsets:query开始时的初始点,可以是earliest,也就是最开始的offsets;latest,也就是最新的offsets;或者是一个JSON string,为每个TopicPartition指定的初始offset。在JSON中,-2 作为offset可以用于指向earliest,-1指向latest。例如,一个JSON定义为 {"topicA":{"0":23,"1":-1},"topicB":{"0":-2}}。
- failOnDataLoss:如果有数据丢失(例如topics 被删除、或者offsets 超出范围),是否要fail掉query。默认是true,可以根据任务需求进行修改。
- maxOffsetsPerTrigger:对于给定的一个trigger,读入多少个offsets
当然,还有其他配置选项,如Kafka consumer timeouts,fetch retries,以及 intervals 等。
下面是一个例子:
// subscribe to 1 topic
val ds1 = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "b-1.xxxxxx:9092,b-2.xxxxxx:9092")
.option("subscribe", "topic1")
.load() // subscribe to multiple topics
val ds1 = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "b-1.xxxxxx:9092,b-2.xxxxxxx:9092")
.option("subscribe", "topic1, topic2")
.load() // subscribe to a pattern of topics
val ds1 = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "b-1.xxxxxx:9092,b-2.xxxxxxxx:9092")
.option("subscribePattern", "topic.*")
.load()
这里若是弹出以下报错:
org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".
则根据Spark 官网添加jar 包:
spark-shell --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.5
或:
./bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.5 ...
在Kafka Source 中的每条row都会有以下schema:
- key: binary
- value: binary
- topic: string
- partition: int
- offset: long
- timestamp: long
在Kafka中的每条message都会以某种方式序列化。可以使用Spark原生的方法或是UDF将message 处理为一个更具结构化的形式,常见的模式有JSON或是Avro,去读写Kafka。
写Kafka Sink
写 Kafka Sink与读Kafka Sink 类似,仅有几个参数不一样。我们仍需要指定Kafka bootstrap servers,而其他需要提供的选项是topic以及列名,有两种方式提供,如下所示,下面两个写法是等价的:
// specify topic and columns together
ds1.selectExpr("topic", "CAST(key as STRING)", "CAST(value AS STRING)")
.writeStream.format("kafka")
.option("checkpointLocation", "/kafka/checkpoint/dir")
.option("kafka.bootstrap.servers", "b-1.tang-kafka-plain.hnjunx.c4.kafka.cn-north-1.amazonaws.com.cn:9092,b-2.tang-kafka-plain.hnjunx.c4.kafka.cn-north-1.amazonaws.com.cn:9092")
.start() // specify column and topic seperately
ds1.selectExpr("CAST(key as STRING)", "CAST(value AS STRING)")
.writeStream.format("kafka")
.option("checkpointLocation", "/kafka/checkpoint/dir")
.option("kafka.bootstrap.servers", "b-1.tang-kafka-plain.hnjunx.c4.kafka.cn-north-1.amazonaws.com.cn:9092,b-2.tang-kafka-plain.hnjunx.c4.kafka.cn-north-1.amazonaws.com.cn:9092")
.option("topic", "topic1")
.start()
foreach Sink
foreach sink 类似于Dataset API 中的 foreachPartitions。这个操作允许operations可以在per-partition 的基础下进行并行地计算。在使用foreach sink时,必须实现ForeachWriter 接口,可以在Scala/Java 文档中查看,它包含3个方法:open、process 和 close。在trigger触发了一组生成的rows后,会执行相对应的这三个方法。
总的来说,这个是一个自定义的方法,可以实现自己想要的业务逻辑。
针对测试的Sources与Sinks
这些主要用于做测试,一般不会在生产环境中使用,因为它们无法提供端到端的fault tolerance。
Socket source
通过TCP sockets发送的数据,指定host和port 来读数据,如:
val socketDF = spark.readStream.format("socket")
.option("host", "localhost").option("port", 9999).load()
在客户端可以执行:
nc -lk 9999
Console sink
可以将输出吸入到console,支持append和complete的输出模式:
activityCounts.format("console").write()
Memory sink
类似于console sink,区别是会将数据collect到driver中,然后以in-memory table的形式提供交互式query:
activityCounts.writeStream.format("memory").queryName("my_device_table")
7.2. 数据如何输出(Output Modes)
在Structured Streaming 中,output modes的概念与static DF 中的一样。
Append Mode
Append mode 是默认的行为,也是最简单最容易理解的。在一个新row添加到result table时,它们会基于指定的trigger,输出到sink。在fault-tolerant sink的条件下,这个模式可以确保每行row仅输出一次(并且仅此一次)。当我们将append mode 与event-time 和watermarks 结合使用时,仅有最终的结果会输出到sink。
Complete Mode
Complete mode 会输出result table 的整个state到配置的output sink 中。在一些stateful 数据的场景下,例如所有的rows都会随时间改变,或是配置的sink 并不支持行级的updates 时,complete mode 非常有用。如果query 并不包含aggregation,则这个等同于 append mode
Update Mode
Update mode 类似于 complete mode,区别是:仅有与上一次不同的rows 会被写入到sink 中。不过,sink必须支持行级的 updates,才能支持这个模式。如果query 不包含任何 aggregation,则这个模式等同于 append mode。
什么场景选择各个mode?
Structured Streaming 对于每个output mode,都会结合query的信息进行限制。例如,假设我们的query仅是做一个map操作,那么Structured Streaming不会允许complete mode,因为这样会需要记录所有的输入records,并重写整个output table。下面是一些小手册,关于什么时候使用各个output mode。

什么时候数据输出(Triggers)
在控制什么时候将数据输出到sink时,我们会设置一个trigger。默认情况下,Structured Streaming会在上一个trigger完成处理后,启动数据。我们可以使用triggers来确保不会有太多的updates压垮output sink,或是控制output中的文件大小。当前,仅有一种定期触发的trigger类型,基于的是processing time;以及一次性的trigger,用于手动一次执行一个processing step。在未来会加入更多的triggers。
Processing Time Trigger
对于processing time trigger,我们仅需要指定一个string 类型的duration时间即可(或是在Scalat中的Duration 类型、Java中的TimeUnit类型),例如:
import org.apache.spark.sql.streaming.Trigger
activityCounts.writeStream
.trigger(Trigger.ProcessingTime("100 seconds"))
.format("memory")
.outputMode("complete")
.start()
ProcessingTime trigger 会等到给定duration的时间再输出数据。例如,假设给定的duration是1分钟,则trigger会在12:00,12:01,12:02 触发,依次类推。如果由于上一个处理没完成,导致了一个trigger time miss,则Spark会等到下一个trigger 点(也就是下一分钟),而不是在上一个处理完成后立即终止。
Once Trigger
我们也可以仅让一个streaming job 执行一次,指定once trigger即可。这个听起来有点奇怪,不过在开发与生产中,这个trigger都非常有用。对于开发,可以用于测试。而对于生产,Once trigger可以让我们以一个非常低频的方式执行任务(例如,向数据源导入数据是一个不确定的时间周期)。由于Structured Streaming 仍可以追溯所有已经处理过的文件,以及计算后的state,它比自身再写一个追溯batch job 的处理要简单地多,并且可以节省较多的资源(因为流程序定期运行的话,会一直消耗计算资源)。使用方式如下:
import org.apache.spark.sql.streaming.Trigger
activityCounts.writeStream.trigger(Trigger.Once())
.format("console")
.outputMode("complete")
.start()
8. Streaming Dataset API
最后一点需要提到的是,在Structured Streaming 中,不仅只限于对stream使用DataFrame API。还可以使用Datasets执行同样的计算,但是用的是type-safe 的方式。我们可以将一个streaming DataFrame转换为一个Dataset。
Spark Structured Streaming(二)实战的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十九):推送avro格式数据到topic,并使用spark structured streaming接收topic解析avro数据
推送avro格式数据到topic 源代码:https://github.com/Neuw84/structured-streaming-avro-demo/blob/master/src/main/j ...
- Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景: 需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新 ...
- Spark2.3(三十五)Spark Structured Streaming源代码剖析(从CSDN和Github中看到别人分析的源代码的文章值得收藏)
从CSDN中读取到关于spark structured streaming源代码分析不错的几篇文章 spark源码分析--事件总线LiveListenerBus spark事件总线的核心是LiveLi ...
- Spark Structured streaming框架(1)之基本使用
Spark Struntured Streaming是Spark 2.1.0版本后新增加的流计算引擎,本博将通过几篇博文详细介绍这个框架.这篇是介绍Spark Structured Streamin ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
- Spark2.3(三十四):Spark Structured Streaming之withWaterMark和windows窗口是否可以实现最近一小时统计
WaterMark除了可以限定来迟数据范围,是否可以实现最近一小时统计? WaterMark目的用来限定参数计算数据的范围:比如当前计算数据内max timestamp是12::00,waterMar ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- Spark Structured Streaming框架(3)之数据输出源详解
Spark Structured streaming API支持的输出源有:Console.Memory.File和Foreach.其中Console在前两篇博文中已有详述,而Memory使用非常简单 ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
随机推荐
- SuperSonic简介
SuperSonic融合ChatBI和HeadlessBI打造新一代的数据分析平台.通过SuperSonic的问答对话界面,用户能够使用自然语言查询数据,系统会选择合适的可视化图表呈现结果. Supe ...
- 13、web 中间件加固-Nginx 加固
1.隐藏版本信息 避免被针对版本直接使用漏洞 修改 nginx.conf 文件 在 http 模块中添加信息:server_tokens off; 2.限制目录权限 某些目录为运维页面,不要公开访问 ...
- 在Deepin 20.2系统中换源并全新图解安装MySQL数据库
在Deepin 20.2系统中换源并全新图解安装MySQL数据库 https://www.ywnz.com/linuxysjk/9249.html ubuntu下apt-get彻底卸载mysql 删除 ...
- ssh秘钥对免密码登陆
准备两台linux服务器 a和b , 在a上使用ssh命令登陆b服务器 , 并且不用 输入密码 1.在a服务器上,比如是root用户 ,进去/root/.ssh目录 ,没有就创建, 就是进入家目录的. ...
- nim 6. 使用包
本来想按照制作包 - 发布包 - 使用包的顺序写.发现制作包一时还没搞懂,先看看怎么使用包吧. nim的包管理工具,是自带的 nimble. nimble的官方包列表是:Nim package di ...
- Ubuntu更新源文件报错:E: 仓库 “http://ppa.launchpad.net/chris-lea/node.js/ubuntu bionic Release” 没有 Release 文件。
E: 仓库 "http://ppa.launchpad.net/chris-lea/node.js/ubuntu bionic Release" 没有 Release 文件. 一条 ...
- 西门子PLC设备如何接入AIRIOT物联网低代码平台 ?
西门子PLC设备广泛应用于工业控制领域,高性能和稳定是它最大的优势.下面我们要把西门子300 1200 1500 PLC设备连接到AIRIOT物联网低代码平台,具体操作如下所示: 西门子驱动配置(配套 ...
- sqlerver 报错5120 无法为该请求检索数据 系统找不到指定路径
背景: 数据库mdf文件所在盘符F盘被删除了,也就是文件不存在了,sqlserver管理器打开就报错5120,并且正常路径的数据库也不显示出来. 要让正常的数据库显示出来,就需要删除掉已经没有的数据库 ...
- 【C#】 封装的异步HttpRequest
private async void btn_userLogin_Click(object sender, EventArgs e) { UInfo = new ...
- 制作SSL证书(签发免费证书)
制作SSL证书(签发免费证书) 下载证书生成器 wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 wget https://pkg.cfssl.org ...