Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data
KNime - GUI based
Spark MLlib - inside Spark
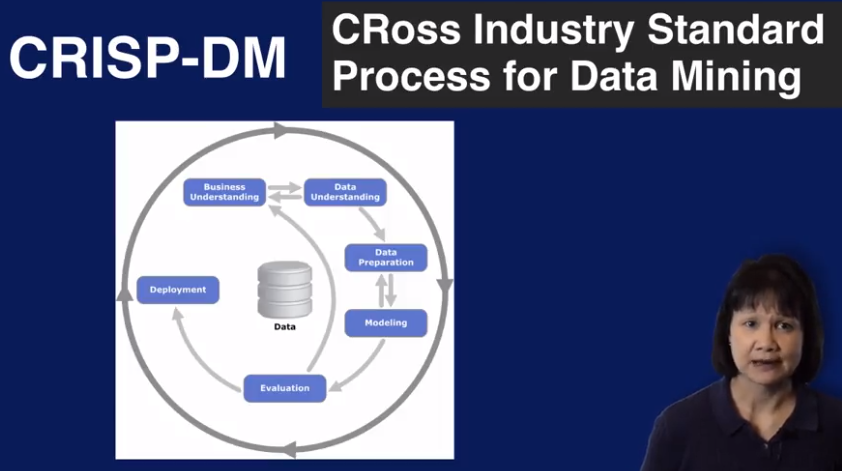
CRISP-DM

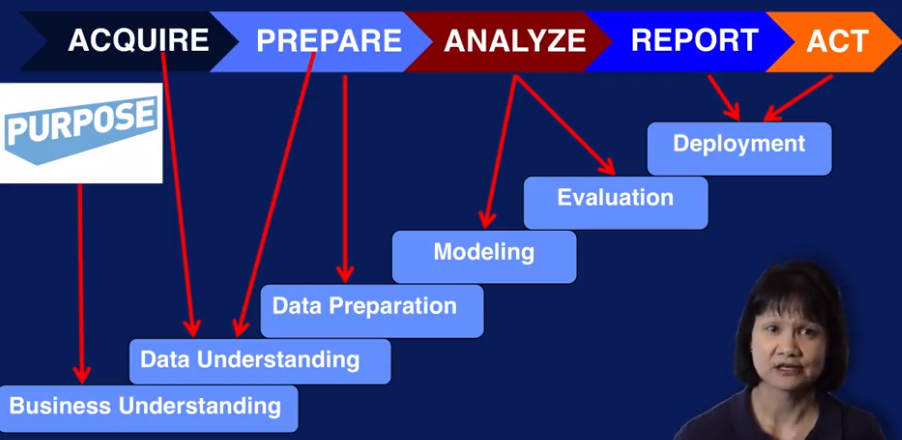
Week 2, Data Exploration
一般有两种方法,summary statistics 和 visualization

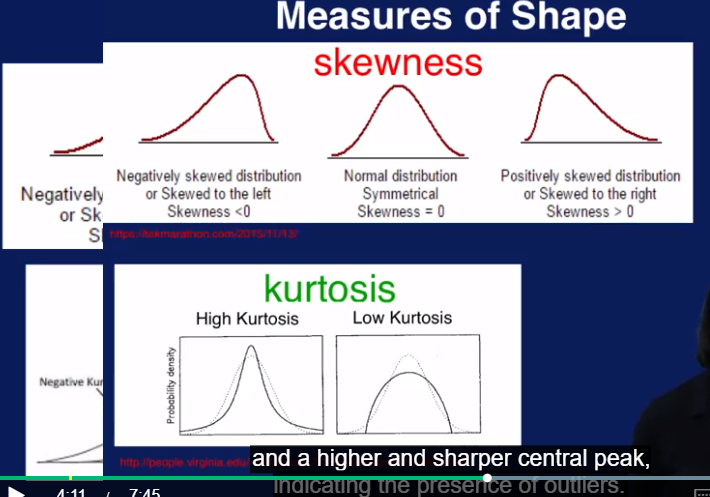
Summary statistics (mean 平均数,median 中位数, mode 最常见的数)


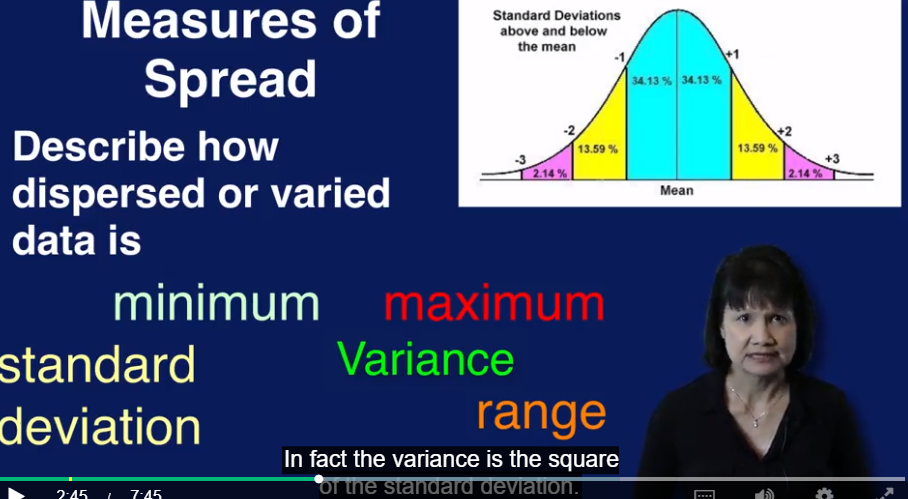
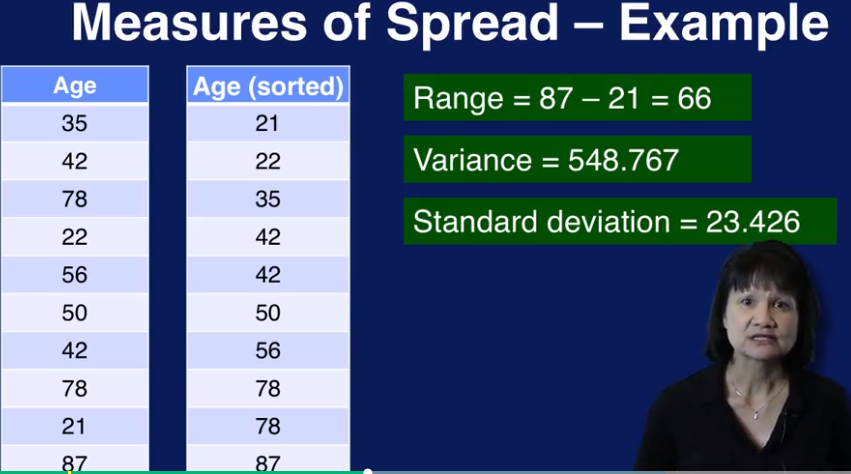
high Kurtosis 预示着有outlier的存在
visualization

这里详细讲一下 box plot
下图的 upper quartile 和 lower quartile 分别指的是 75% 和 25% 的点, median 很明显是中位数点,中间柱状部分的数据占了总数据的50%. Upper extreme 和 Lower extreme 分别是90% 和 10% 数据的点,超出部分就是outliers.

Data preparing


data wrangling 主要是transformation

Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)的更多相关文章
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- In machine learning, is more data always better than better algorithms?
In machine learning, is more data always better than better algorithms? No. There are times when mor ...
- [Javascript] Classify JSON text data with machine learning in Natural
In this lesson, we will learn how to train a Naive Bayes classifier and a Logistic Regression classi ...
- Coursera 学习笔记|Machine Learning by Standford University - 吴恩达
/ 20220404 Week 1 - 2 / Chapter 1 - Introduction 1.1 Definition Arthur Samuel The field of study tha ...
- [Machine Learning with Python] Data Preparation through Transformation Pipeline
In the former article "Data Preparation by Pandas and Scikit-Learn", we discussed about a ...
- [Machine Learning with Python] Data Preparation by Pandas and Scikit-Learn
In this article, we dicuss some main steps in data preparation. Drop Labels Firstly, we drop labels ...
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- [Machine Learning with Python] Data Visualization by Matplotlib Library
Before you can plot anything, you need to specify which backend Matplotlib should use. The simplest ...
- Coursera《machine learning》--(14)数据降维
本笔记为Coursera在线课程<Machine Learning>中的数据降维章节的笔记. 十四.降维 (Dimensionality Reduction) 14.1 动机一:数据压缩 ...
随机推荐
- 练习 python之数据库增删改查
# 文件存储时可以这样表示 ## id,name,age,phone,dept,enroll_date# 1,Alex Li,22,13651054608,IT,2013-04-01# 2,Jack ...
- input type=file的几个属性
<input type='file' /> inputDom.onchange=function (e){ e.currentTarget.files 是只有一个对象的数组 var ob ...
- python科学计算库的numpy基础知识,完美抽象多维数组(原创)
#导入科学计算库 #起别名避免重名 import numpy as np #小技巧:从外往内看==从左往右看 从内往外看==从右往左看 #打印版本号 print(np.version.version) ...
- day09(垃圾回收机制)
1,复习 文件处理 1.操作文件的三步骤 -- 打开文件:硬盘的空间被操作系统持有 | 文件对象被应用程序持续 -- 操作文件:读写操作 -- 释放文件:释放操作系统对硬盘空间的持有 2.基础的读写 ...
- win10x64 批处理自动安装打印机
系统版本:Windows 10企业版 64位(10.0 ,版本17134)- 中文(简体) 话不多说,直接上脚本: REM 提升管理员权限 @echo off chcp 65001 >nul s ...
- mybatis中常见的问题总结
如下所有举例基于springboot+mybatis项目中,SSH使用mybatis的写法也一样,只是形式不同而已 问题1.org.apache.ibatis.binding.BindingExcep ...
- 二叉树最近公共祖先(LeetCode)
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先. 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p.q,最近公共祖先表示为一个结点 x,满足 x 是 p.q 的祖先且 x 的深 ...
- Capability配置简介
什么是Capability desired capability的功能是配置Appium会话.他们告诉Appium服务器您想要自动化的平台和应用程序. Desired Capabilities是一组设 ...
- python-装饰器的最终形态和固定格式 语法糖
import time def timer(f): # 这是一个装饰器函数 def inner(): start = time.time() f() # 被装饰的函数 end = time.time( ...
- ElementUI DatePicker 日期选择器控制选择时间范围
选择今天以及今天之后的日期 <el-date-picker v-model="value1" type="date" placeholder=" ...