Go实例解析
Go语言包的加载顺序如图
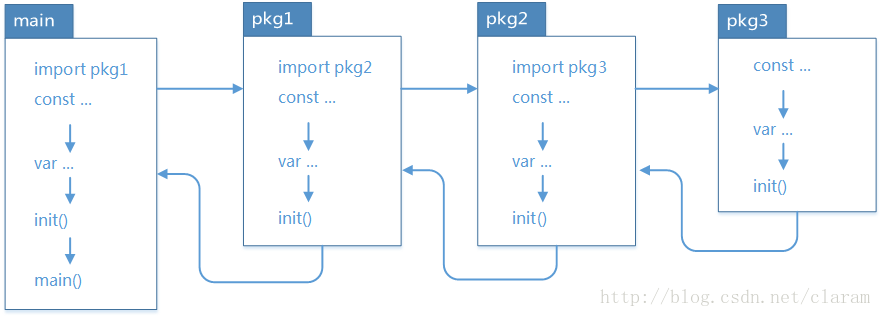
可以通过如下实例详细了解
代码来源于《Go实战》
代码地址:https://github.com/goinaction/code
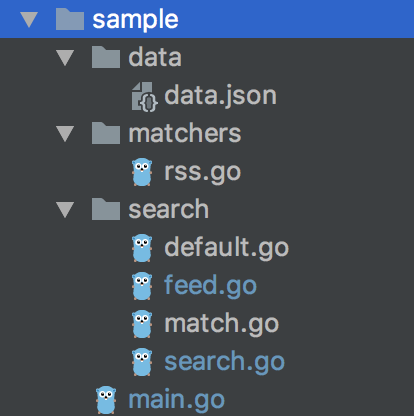
项目代码结构
程序架构
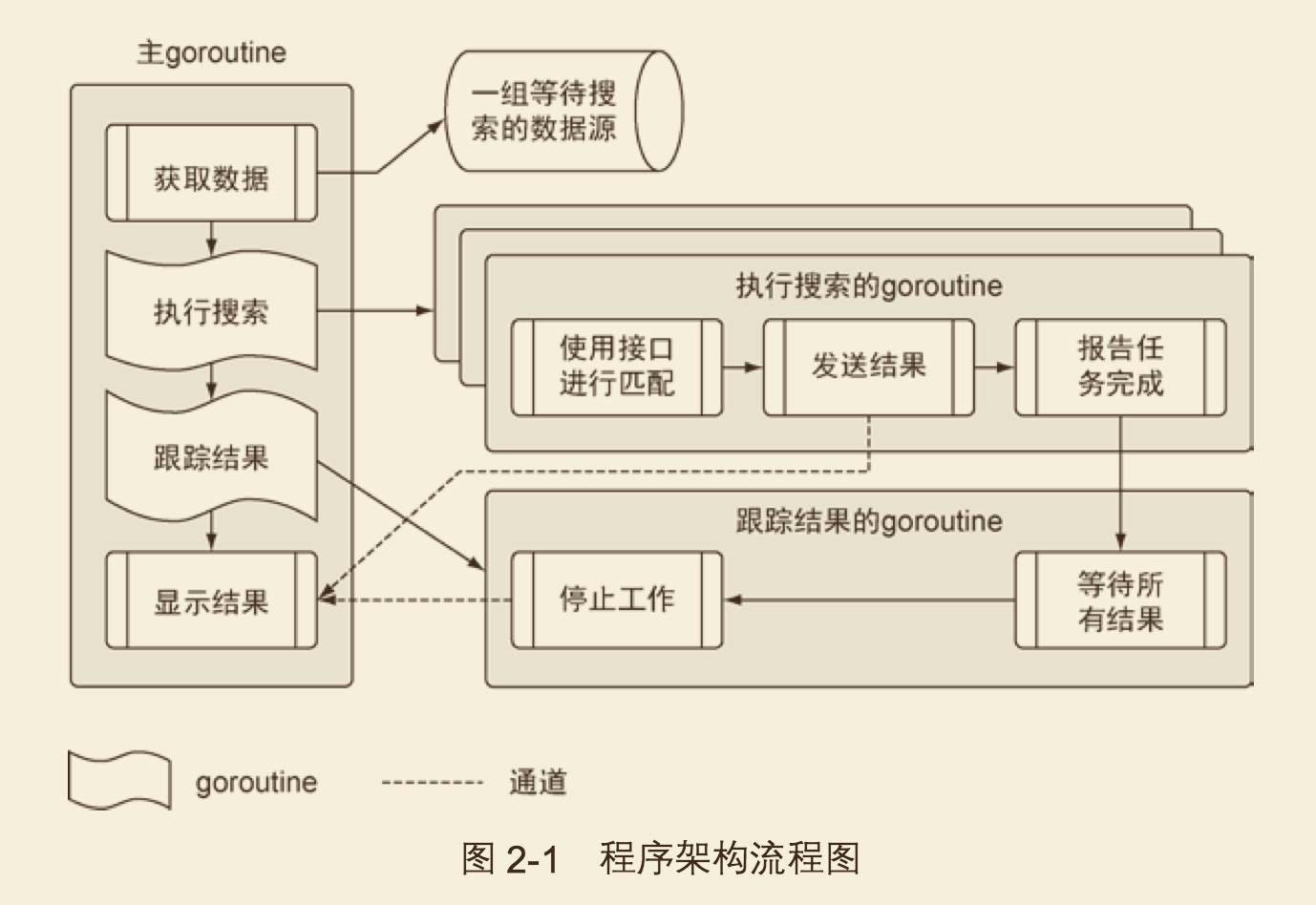
首先分析main文件
main.main.go
package main
import (
"log"
"os"
_ "github.com/goinaction/code/chapter2/sample/matchers" // 对包做初始化操作,但是不使用包里的标志符。调用包里所有的init函数
"github.com/goinaction/code/chapter2/sample/search"
)
// init is called prior to main.
func init() {
// Change the device for logging to stdout.
log.SetOutput(os.Stdout)
}
// main is the entry point for the program.
func main() {
// Perform the search for the specified term.
search.Run("president")
}
在执行main文件之前,会首先加载matchers、search包里的init函数和包级别的常量变量定义
加载matchers包的变量常量定义和init函数
type (
item struct {
XMLName xml.Name `xml:"item"`
PubDate string `xml:"pubDate"`
Title string `xml:"title"`
Description string `xml:"description"`
Link string `xml:"link"`
GUID string `xml:"guid"`
GeoRssPoint string `xml:"georss:point"`
}
image struct {
XMLName xml.Name `xml:"image"`
URL string `xml:"url"`
Title string `xml:"title"`
Link string `xml:"link"`
}
channel struct {
XMLName xml.Name `xml:"channel"`
Title string `xml:"title"`
Description string `xml:"description"`
Link string `xml:"link"`
PubDate string `xml:"pubDate"`
LastBuildDate string `xml:"lasteBuildDate"`
TTL string `xml:"ttl"`
Language string `xml:"language"`
ManagingEditor string `xml:"managingEditor"`
WebMaster string `xml:"webMaster"`
Image image `xml:"image"`
Item []item `xml:"item"`
}
rssDocument struct {
XMLName xml.Name `xml:"rss"`
Channel channel `xml:"channel"`
}
)
type rssMatcher struct{}
func init() {
var matcher rssMatcher
search.Register("rss", matcher)
}
加载search包的常量变量定义和init函数
const dataFile = "data/data.json"
type Feed struct {
Name string `json:"site"`
URI string `json:"link"`
Type string `json:"type"`
}
type Result struct {
Field string
Content string
}
type Matcher interface {
Search(feed *Feed, searchTerm string) ([]*Result, error)
}
var matchers = make(map[string]Matcher)
type defaultMatcher struct{}
func init() {
var matcher defaultMatcher
Register("default", matcher)
}
在回到main函数,首先执行search.Run()的函数,
func Run(searchTerm string) {
feeds, err := RetrieveFeeds()
if err != nil {
log.Fatal(err)
}
results := make(chan *Result)
//添加线程等待
var waitGroup sync.WaitGroup
waitGroup.Add(len(feeds))
for _, feed := range feeds {
log.Printf("%v", *feed)
matcher, exists := matchers[feed.Type]
if !exists {
matcher = matchers["default"]
}
//起协程是执行匹配
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
}
go func() {
waitGroup.Wait()
close(results)
}()
Display(results)
}
在Run函数中,执行RetrieveFeeds()函数
func RetrieveFeeds() ([]*Feed, error) {
//打开配置文件
file, err := os.Open(dataFile)
if err != nil {
return nil, err
}
defer file.Close()
var feeds []*Feed
//解析json格式到Feed结构体
err = json.NewDecoder(file).Decode(&feeds)
return feeds, err
}
执行匹配
func Match(matcher Matcher, feed *Feed, searchTerm string, results chan<- *Result) {
searchResults, err := matcher.Search(feed, searchTerm)
if err != nil {
log.Println(err)
return
}
//将匹配到的结果写入chan
for _, result := range searchResults {
results <- result
}
}
执行搜索
func (m rssMatcher) Search(feed *search.Feed, searchTerm string) ([]*search.Result, error) {
var results []*search.Result
log.Printf("search Feed Type[%s] Site[%s] For URI[%s]\n", feed.Type, feed.Name, feed.URI)
document, err := m.retrieve(feed)
if err != nil {
return nil, err
}
for _, channelItem := range document.Channel.Item {
matched, err := regexp.MatchString(searchTerm, channelItem.Title)
if err != nil {
return nil, err
}
if matched {
results = append(results, &search.Result{
Field: "Title",
Content: channelItem.Title,
})
}
matched, err = regexp.MatchString(searchTerm, channelItem.Description)
if err != nil {
return nil, err
}
if matched {
results = append(results, &search.Result{
Field: "Description",
Content: channelItem.Description,
})
}
}
return results, nil
}
func (m rssMatcher) retrieve(feed *search.Feed) (*rssDocument, error) {
if feed.URI == "" {
return nil, errors.New("NO rss feed uri provided")
}
//http获取uri返回
resp, err := http.Get(feed.URI)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return nil, fmt.Errorf("HTTP Response Error %d\n", resp.StatusCode)
}
//将结果解析到xml格式的struct
var document rssDocument
err = xml.NewDecoder(resp.Body).Decode(&document)
return &document, err
}
最后展示结构
func Display(results chan *Result) {
//从chan中读取,会阻塞直到chan close
for result := range results {
log.Printf("%s:\n%s\n\n", result.Field, result.Content)
}
}
Go实例解析的更多相关文章
- exec函数族实例解析
exec函数族实例解析 fork()函数通过系统调用创建一个与原来进程(父进程)几乎完全相同的进程(子进程是父进程的副本,它将获得父进程数据空间.堆.栈等资源的副本.注意,子进程持有的是上述存储空间的 ...
- [Reprint] C++函数模板与类模板实例解析
这篇文章主要介绍了C++函数模板与类模板,需要的朋友可以参考下 本文针对C++函数模板与类模板进行了较为详尽的实例解析,有助于帮助读者加深对C++函数模板与类模板的理解.具体内容如下: 泛型编程( ...
- [Reprint]C++普通函数指针与成员函数指针实例解析
这篇文章主要介绍了C++普通函数指针与成员函数指针,很重要的知识点,需要的朋友可以参考下 C++的函数指针(function pointer)是通过指向函数的指针间接调用函数.相信很多人对指向一般 ...
- JavaWeb实现文件上传下载功能实例解析
转:http://www.cnblogs.com/xdp-gacl/p/4200090.html JavaWeb实现文件上传下载功能实例解析 在Web应用系统开发中,文件上传和下载功能是非常常用的功能 ...
- Android实例-Delphi开发蓝牙官方实例解析(XE10+小米2+小米5)
相关资料:1.http://blog.csdn.net/laorenshen/article/details/411498032.http://www.cnblogs.com/findumars/p/ ...
- Android开发之IPC进程间通信-AIDL介绍及实例解析
一.IPC进程间通信 IPC是进程间通信方法的统称,Linux IPC包括以下方法,Android的进程间通信主要采用是哪些方法呢? 1. 管道(Pipe)及有名管道(named pipe):管道可用 ...
- easyUI:ComboTree and comselector使用实例解析
ComboTree 使用场景:故名思意,ComboTree是combox和Tree的结合体,在需要通过选择得到某一个node值的时候触发. 栗子: 定义: 使用标签创建树形下拉框. Comselect ...
- Maven--多模块依赖实例解析(五)
<Maven--搭建开发环境(一)> <Maven--构建企业级仓库(二)> <Maven—几个需要补充的问题(三)> <Maven—生命周期和插件(四)&g ...
- SoapUI简介和入门实例解析
SoapUI简介 SoapUI是一个开源测试工具,通过soap/http来检查.调用.实现Web Service的功能/负载/符合性测试.该工具既可作为一个单独的测试软件使用,也可利用插件集成到Ecl ...
- shell test和find命令实例解析
shell test和find命令实例解析 下面以\build\core\product.mk相关部分来学习 define _find-android-products-files $(shell t ...
随机推荐
- 20145338 《网络对抗》 MSF基础应用
20145338<网络对抗> MSF基础应用 实验内容 ·掌握metasploit的基本应用方式,掌握常用的三种攻击方式的思路. 具体需要完成(1)一个主动攻击;(2)一个针对浏览器的攻击 ...
- 使用U盘为龙芯笔记本安装操作系统
摘要:在没有光驱的情况下,可以使用dd命令或者ultraISO软件制作Linux安装U盘,方法适合龙芯和X86.AMD64的设备. 前段时间,由于开发需要,拿到了一部龙芯3A3000的笔记本.出厂的安 ...
- MyBatis工具类
package cn.word.util; import java.io.IOException;import java.io.InputStream;import java.util.Enumera ...
- 部署安装kubernetes client-python,执行pip install setup.py时报错
之前在本地安装过kubernetes的python库,安装下来一切正常,但今天换到测试机器上去部署,确保错了,具体步骤如下. 第一步,克隆代码,执行以下命令: # git clone --rec ...
- java应用性能分析
dump内存信息 通过jps -lm找到进程id jmap -dump:format=b,file=./heap.hprof <pid> 使用jprofile等分析内存占用情况 dump线 ...
- vim学习纪要
普通模式 根据屏幕行上下移动. gj gk g0 g^ g$ 移动到行首第一个非空字符 ^ 反向移动到上一单词的词尾 ge 插入模式 粘贴寄存器中内容 <C-r> 可视模式 移动光标的起始 ...
- Intellij IDEA xxx.properties变成纯文本模式解决方案
今天在创建xxx.properties的时候不知道按到了哪里,结果让它编程了纯文本模式,重命名这个文件或者删掉,重新创建这个同名文件,换一个项目,始终是文本文件类型,就估计不是项目问题,是intell ...
- selenium的其他操作
# author=zyqfrom selenium import webdriverimport timedriver=webdriver.Chrome()driver.get('http://ui. ...
- Curve 曲线 工具
最近研究了曲线绘制的工具,主要是2D方程的绘制.综合了许多工具,完成了一下两个脚本. 绘制的工具: using UnityEngine; using System.Collections; using ...
- ABP框架(asp.net core 2.X+Vue)模板项目学习之路(一)
前言: 第一次接触ABP的项目是在2018年6月份,但是当时没有深入具体的研究,而今天因为工作的需要,需要学习.了解这个框架,在时隔半年之后,今天重新下载了这个项目,虽然在园子里有很多前辈们写的这类的 ...