Pandas 基础(16) - Holidays
这节依然是关于时间方面的知识.
上一节学习了如何获取日期序列的函数, 以及通过一些基本的参数设置可以使时间序列跳过休息日等.
这一节, 将要深入学习这个点, 做更自定义的设计.
通过上一节的学习, 我们知道了如何获取一个时间段的序列, 那我们很容易就可以得到 2019年2月1日到2月28日的所有工作日的时间序列:
import pandas as pd
pd.date_range(start='2/1/2019', end='2/28/2019', freq='B')
输出:
DatetimeIndex(['2019-02-01', '2019-02-04', '2019-02-05', '2019-02-06',
'2019-02-07', '2019-02-08', '2019-02-11', '2019-02-12',
'2019-02-13', '2019-02-14', '2019-02-15', '2019-02-18',
'2019-02-19', '2019-02-20', '2019-02-21', '2019-02-22',
'2019-02-25', '2019-02-26', '2019-02-27', '2019-02-28'],
dtype='datetime64[ns]', freq='B')
那我们现在得到的就是 2019年2月的所有工作日, 但是其实在美国 2019年2月18日是华盛顿诞辰日 Washington's Birthday (President's Day), 也就是说这一天不能算成工作日, 所以 date_range()函数的第三个参数 freq 现有的几个选项值都无法满足这个需求, 而 Pandas 也提供了这种自定义的空间:
from pandas.tseries.holiday import USFederalHolidayCalendar
from pandas.tseries.offsets import CustomBusinessDay
usb = CustomBusinessDay(calendar = USFederalHolidayCalendar())
pd.date_range(start='2/1/2019', end='2/28/2019', freq=usb)
输出:
DatetimeIndex(['2019-02-01', '2019-02-04', '2019-02-05', '2019-02-06',
'2019-02-07', '2019-02-08', '2019-02-11', '2019-02-12',
'2019-02-13', '2019-02-14', '2019-02-15', '2019-02-19',
'2019-02-20', '2019-02-21', '2019-02-22', '2019-02-25',
'2019-02-26', '2019-02-27', '2019-02-28'],
dtype='datetime64[ns]', freq='C')
先来看输出结果, 果然 '2019-02-18' 被略过了. 其实, 代码中每个函数的名字取得都非常好, 基本就是见字知意了, 我这里就不赘述了(如果有不明白的可以留言).
但是特别说下这个函数 --- USFederalHolidayCalendar() 美国联邦假期日历函数, 得益于 Pandas 自带的这个函数, 我们很轻松地获取到了美国实际的工作日数据. 那么是不是其他国家也都有这个函数呢? 答案是否定的, 不过没关系, 我们可以根据这个函数的源码, 依葫芦画瓢, 自定义我们想要的任何日历. 下面是 Pandas 的 github 地址, 大家找到如下图的源码, 拷贝一下:
https://github.com/pandas-dev/pandas/blob/master/pandas/tseries/holiday.py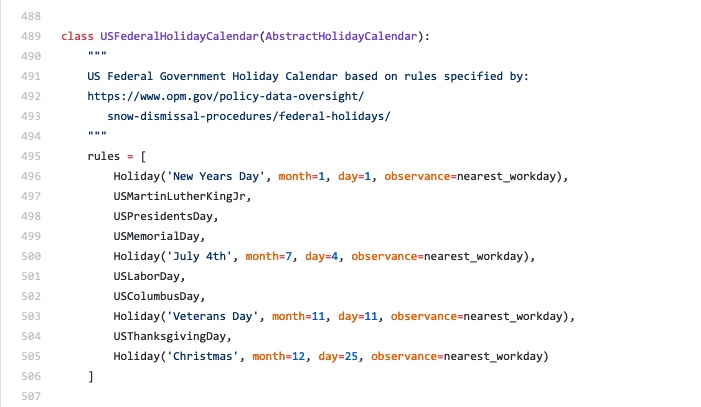
源码的代码很简单, 对假日的定义主要就是体现在 holiday() 函数里. 下面来实践一下, 比如我的生日是4月20日, 我要把这一天自定义到4月的休息日里:
from pandas.tseries.holiday import AbstractHolidayCalendar, nearest_workday, Holiday
class myBirthdayCalendar(AbstractHolidayCalendar):
rules = [
Holiday('Rachel"s Birthday', month=4, day=20)
]
myc = CustomBusinessDay(calendar = myBirthdayCalendar())
pd.date_range(start='4/1/2018', end='4/30/2018', freq=myc)
输出:
DatetimeIndex(['2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05',
'2018-04-06', '2018-04-09', '2018-04-10', '2018-04-11',
'2018-04-12', '2018-04-13', '2018-04-16', '2018-04-17',
'2018-04-18', '2018-04-19', '2018-04-23', '2018-04-24',
'2018-04-25', '2018-04-26', '2018-04-27', '2018-04-30'],
dtype='datetime64[ns]', freq='C')
另外, 大家在看 USFederalHolidayCalendar() 的源代码时, 应该已经注意到 holiday() 函数的第三个参数 observance=nearest_workday, 这个参数的意思就是说, 如果刚好节日的那天也是周六的话, 那么就把周五定为休息日, 如果刚好节日的那天也是周日的话, 就把下周一定为休息日, 也就是不能白过节的意思, 哈哈哈. 不知道我表达清楚了没有, 如果还是有点迷糊, 就动手时间一下, 对照日历看下就明白了. 我这里暂且把生日改为4月21日, 刚好那天是周六, 但是我加上这个参数 -- observance=nearest_workday:
from pandas.tseries.holiday import AbstractHolidayCalendar, nearest_workday, Holiday
class myBirthdayCalendar(AbstractHolidayCalendar):
rules = [
Holiday('Rachel"s Birthday', month=4, day=21, observance=nearest_workday)
]
myc = CustomBusinessDay(calendar = myBirthdayCalendar())
pd.date_range(start='4/1/2018', end='4/30/2018', freq=myc)
输出:
DatetimeIndex(['2018-04-02', '2018-04-03', '2018-04-04', '2018-04-05',
'2018-04-06', '2018-04-09', '2018-04-10', '2018-04-11',
'2018-04-12', '2018-04-13', '2018-04-16', '2018-04-17',
'2018-04-18', '2018-04-19', '2018-04-23', '2018-04-24',
'2018-04-25', '2018-04-26', '2018-04-27', '2018-04-30'],
dtype='datetime64[ns]', freq='C')
从输出可以看出, 2018-04-20 也被划为休息日了. OK, 继续......
大多数国家的工作日都是从周一到周五, 但是也有不一样的, 比如埃及的工作日就是从周日到周四, 所以, 我们又要自定义了:
b = CustomBusinessDay(weekmask='Sun Mon Tue Wed Thu')
pd.date_range(start='4/1/2018', end='4/30/2018', freq=b)
输出:
DatetimeIndex(['2018-04-01', '2018-04-02', '2018-04-03', '2018-04-04',
'2018-04-05', '2018-04-08', '2018-04-09', '2018-04-10',
'2018-04-11', '2018-04-12', '2018-04-15', '2018-04-16',
'2018-04-17', '2018-04-18', '2018-04-19', '2018-04-22',
'2018-04-23', '2018-04-24', '2018-04-25', '2018-04-26',
'2018-04-29', '2018-04-30'],
dtype='datetime64[ns]', freq='C')
那比方说, 其中的某一天或者几天又是法定节假日呢? 简单:
b = CustomBusinessDay(weekmask='Sun Mon Tue Wed Thu', holidays=['2018-04-15'])
pd.date_range(start='4/1/2018', end='4/30/2018', freq=b)
输出:
DatetimeIndex(['2018-04-01', '2018-04-02', '2018-04-03', '2018-04-04',
'2018-04-05', '2018-04-08', '2018-04-09', '2018-04-10',
'2018-04-11', '2018-04-12', '2018-04-16', '2018-04-17',
'2018-04-18', '2018-04-19', '2018-04-22', '2018-04-23',
'2018-04-24', '2018-04-25', '2018-04-26', '2018-04-29',
'2018-04-30'],
dtype='datetime64[ns]', freq='C')
综上, 我们可以看到 Pandas 真的非常强大, 它有各种各样的参数, 通过不同的设置, 取值, 可谓是花样玩转数据分析.
Pandas 基础(16) - Holidays的更多相关文章
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- [.net 面向对象编程基础] (16) 接口
[.net 面向对象编程基础] (16) 接口 关于“接口”一词,跟我们平常看到的电脑的硬件“接口”意义上是差不多的.拿一台电脑来说,我们从外面,可以看到他的USB接口,COM接口等,那么这些接口的目 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
随机推荐
- ADB——模拟手机按键输入
基本命令 adb 模拟按键输入的命令主要通过 input 进行 Usage: input [<source>] <command> [<arg>...] The s ...
- Asp.net Web Api开发(第四篇)Help Page配置和扩展
https://blog.csdn.net/sqqyq/article/details/52708613
- win10家庭版删除文件提示没有权限最简单的方式
1.cmd 2.右键-以管理员身份运行(重要) 3.输入:net user administrator /active:yes,开启超级管理员账号 4.win+r键打开运行对话框,输入 netplwi ...
- Python super初始化理解过程
# -*- coding:utf-8 -*-<br data-filtered="filtered"> class A(object): def __init__(se ...
- windows10上安装mysql(详细步骤)
2016年09月06日 08:09:34 阅读数:46198 环境:windwos 10(1511) 64bit.mysql 5.7.14 时间:2016年9月5日 一.下载mysql 1. 在浏览器 ...
- Vue父子组件及非父子组件如何通信
1.父组件传递数据给子组件 父组件数据如何传递给子组件呢?可以通过props属性来实现 父组件: 子组件通过props来接收数据: 方式1: 方式2 : 方式3: 这样呢,就实现了父组件向子组件传递数 ...
- Java -- 基于JDK1.8的ArrayList源码分析
1,前言 很久没有写博客了,很想念大家,18年都快过完了,才开始写第一篇,争取后面每周写点,权当是记录,因为最近在看JDK的Collection,而且ArrayList源码这一块也经常被面试官问道,所 ...
- spring boot中使用@Async实现异步调用任务
本篇文章主要介绍了spring boot中使用@Async实现异步调用任务,小编觉得挺不错的,现在分享给大家,也给大家做个参考.一起跟随小编过来看看吧 什么是“异步调用”? “异步调用”对应的是“同步 ...
- Python练习:爬取图片
贴吧地址 https://tieba.baidu.com/p/5272413637?red_tag=0606091703 程序如下import urllib.requestimport re def ...
- 《高性能Mysql》解读---Mysql的事务和多版本并发
1.base:ACID属性,并发控制 2.MySql事务的隔离级别有哪些,含义是什么? 3.锁知多少,读锁,写锁,排他锁,共享锁,间隙锁,乐观锁,悲观锁. 4.Mysql的事务与锁有什么关联?MySq ...