搭建Hadoop2.6.0+Eclipse开发调试环境
上一篇在win7虚拟机下搭建了hadoop2.6.0伪分布式环境。为了开发调试方便,本文介绍在eclipse下搭建开发环境,连接和提交任务到hadoop集群。
1. 环境
Eclipse版本Luna 4.4.1
安装插件hadoop-eclipse-plugin-2.6.0.jar,下载后放到eclipse/plugins目录即可。
2. 配置插件
2.1 配置hadoop主目录
解压缩hadoop-2.6.0.tar.gz到C:\Downloads\hadoop-2.6.0,在eclipse的Windows->Preferences的Hadoop Map/Reduce中设置安装目录。

2.2 配置插件
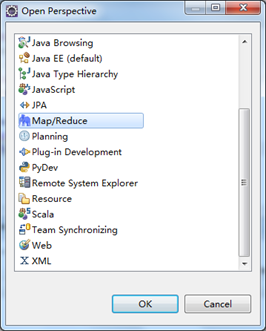
打开Windows->Open Perspective中的Map/Reduce,在此perspective下进行hadoop程序开发。

打开Windows->Show View中的Map/Reduce Locations,如下图右键选择New Hadoop location…新建hadoop连接。

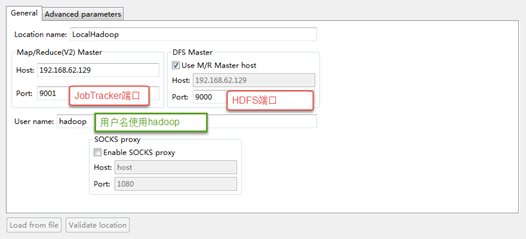
确认完成以后如下,eclipse会连接hadoop集群。

如果连接成功,在project explorer的DFS Locations下会展现hdfs集群中的文件。

3. 开发hadoop程序
3.1 程序开发
开发一个Sort示例,对输入整数进行排序。输入文件格式是每行一个整数。
package com.ccb; /**
* Created by hp on 2015-7-20.
*/ import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Sort { // 每行记录是一个整数。将Text文本转换为IntWritable类型,作为map的key
public static class Map extends Mapper<Object, Text, IntWritable, IntWritable> {
private static IntWritable data = new IntWritable(); // 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
} // reduce之前hadoop框架会进行shuffle和排序,因此直接输出key即可。
public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, Text> { //实现reduce函数
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable v : values) {
context.write(key, new Text(""));
}
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 指定JobTracker地址
conf.set("mapred.job.tracker", "192.168.62.129:9001");
if (args.length != 2) {
System.err.println("Usage: Data Sort <in> <out>");
System.exit(2);
}
System.out.println(args[0]);
System.out.println(args[1]); Job job = Job.getInstance(conf, "Data Sort");
job.setJarByClass(Sort.class); //设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class); //设置输出类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class); //设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3.2 配置文件
把log4j.properties和hadoop集群中的core-site.xml加入到classpath中。我的示例工程是maven组织,因此放到src/main/resources目录。
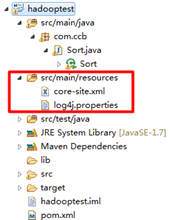
程序执行时会从core-site.xml中获取hdfs地址。
3.3 程序执行
右键选择Run As -> Run Configurations…,在参数中填好输入输出目录,执行Run即可。

执行日志:
hdfs://192.168.62.129:9000/user/vm/sort_in
hdfs://192.168.62.129:9000/user/vm/sort_out
// :: INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
// :: INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
// :: WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
// :: WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1592166400_0001
// :: INFO mapreduce.Job: The url to track the job: http://localhost:8080/
// :: INFO mapreduce.Job: Running job: job_local1592166400_0001
// :: INFO mapred.LocalJobRunner: OutputCommitter set in config null
// :: INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
// :: INFO mapred.LocalJobRunner: Waiting for map tasks
// :: INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_m_000000_0
// :: INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
// :: INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4c90dbc4
// :: INFO mapred.MapTask: Processing split: hdfs://192.168.62.129:9000/user/vm/sort_in/file1:0+25
// :: INFO mapred.MapTask: (EQUATOR) kvi ()
// :: INFO mapred.MapTask: mapreduce.task.io.sort.mb:
// :: INFO mapred.MapTask: soft limit at
// :: INFO mapred.MapTask: bufstart = ; bufvoid =
// :: INFO mapred.MapTask: kvstart = ; length =
// :: INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
// :: INFO mapred.LocalJobRunner:
// :: INFO mapred.MapTask: Starting flush of map output
// :: INFO mapred.MapTask: Spilling map output
// :: INFO mapred.MapTask: bufstart = ; bufend = ; bufvoid =
// :: INFO mapred.MapTask: kvstart = (); kvend = (); length = /
// :: INFO mapred.MapTask: Finished spill
// :: INFO mapred.Task: Task:attempt_local1592166400_0001_m_000000_0 is done. And is in the process of committing
// :: INFO mapred.LocalJobRunner: map
// :: INFO mapred.Task: Task 'attempt_local1592166400_0001_m_000000_0' done.
// :: INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_m_000000_0
// :: INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_m_000001_0
// :: INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
// :: INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@69e4d7d
// :: INFO mapred.MapTask: Processing split: hdfs://192.168.62.129:9000/user/vm/sort_in/file2:0+15
// :: INFO mapred.MapTask: (EQUATOR) kvi ()
// :: INFO mapred.MapTask: mapreduce.task.io.sort.mb:
// :: INFO mapred.MapTask: soft limit at
// :: INFO mapred.MapTask: bufstart = ; bufvoid =
// :: INFO mapred.MapTask: kvstart = ; length =
// :: INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
// :: INFO mapred.LocalJobRunner:
// :: INFO mapred.MapTask: Starting flush of map output
// :: INFO mapred.MapTask: Spilling map output
// :: INFO mapred.MapTask: bufstart = ; bufend = ; bufvoid =
// :: INFO mapred.MapTask: kvstart = (); kvend = (); length = /
// :: INFO mapred.MapTask: Finished spill
// :: INFO mapred.Task: Task:attempt_local1592166400_0001_m_000001_0 is done. And is in the process of committing
// :: INFO mapred.LocalJobRunner: map
// :: INFO mapred.Task: Task 'attempt_local1592166400_0001_m_000001_0' done.
// :: INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_m_000001_0
// :: INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_m_000002_0
// :: INFO mapreduce.Job: Job job_local1592166400_0001 running in uber mode : false
// :: INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4e931efa
// :: INFO mapred.MapTask: Processing split: hdfs://192.168.62.129:9000/user/vm/sort_in/file3:0+8
// :: INFO mapred.MapTask: (EQUATOR) kvi ()
// :: INFO mapred.MapTask: mapreduce.task.io.sort.mb:
// :: INFO mapred.MapTask: soft limit at
// :: INFO mapred.MapTask: bufstart = ; bufvoid =
// :: INFO mapred.MapTask: kvstart = ; length =
// :: INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
// :: INFO mapred.LocalJobRunner:
// :: INFO mapred.MapTask: Starting flush of map output
// :: INFO mapred.MapTask: Spilling map output
// :: INFO mapred.MapTask: bufstart = ; bufend = ; bufvoid =
// :: INFO mapred.MapTask: kvstart = (); kvend = (); length = /
// :: INFO mapred.MapTask: Finished spill
// :: INFO mapred.Task: Task:attempt_local1592166400_0001_m_000002_0 is done. And is in the process of committing
// :: INFO mapred.LocalJobRunner: map
// :: INFO mapred.Task: Task 'attempt_local1592166400_0001_m_000002_0' done.
// :: INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_m_000002_0
// :: INFO mapred.LocalJobRunner: map task executor complete.
// :: INFO mapred.LocalJobRunner: Waiting for reduce tasks
// :: INFO mapred.LocalJobRunner: Starting task: attempt_local1592166400_0001_r_000000_0
// :: INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
// :: INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@
// :: INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@2129404b
// :: INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=, maxSingleShuffleLimit=, mergeThreshold=, ioSortFactor=, memToMemMergeOutputsThreshold=
// :: INFO reduce.EventFetcher: attempt_local1592166400_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
// :: INFO reduce.LocalFetcher: localfetcher# about to shuffle output of map attempt_local1592166400_0001_m_000002_0 decomp: len: to MEMORY
// :: INFO reduce.InMemoryMapOutput: Read bytes from map-output for attempt_local1592166400_0001_m_000002_0
// :: INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: , inMemoryMapOutputs.size() -> , commitMemory -> , usedMemory ->
// :: INFO reduce.LocalFetcher: localfetcher# about to shuffle output of map attempt_local1592166400_0001_m_000000_0 decomp: len: to MEMORY
// :: INFO reduce.InMemoryMapOutput: Read bytes from map-output for attempt_local1592166400_0001_m_000000_0
// :: INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: , inMemoryMapOutputs.size() -> , commitMemory -> , usedMemory ->
// :: INFO reduce.LocalFetcher: localfetcher# about to shuffle output of map attempt_local1592166400_0001_m_000001_0 decomp: len: to MEMORY
// :: INFO reduce.InMemoryMapOutput: Read bytes from map-output for attempt_local1592166400_0001_m_000001_0
// :: INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: , inMemoryMapOutputs.size() -> , commitMemory -> , usedMemory ->
// :: INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
// :: INFO mapred.LocalJobRunner: / copied.
// :: INFO reduce.MergeManagerImpl: finalMerge called with in-memory map-outputs and on-disk map-outputs
// :: INFO mapred.Merger: Merging sorted segments
// :: INFO mapred.Merger: Down to the last merge-pass, with segments left of total size: bytes
// :: INFO reduce.MergeManagerImpl: Merged segments, bytes to disk to satisfy reduce memory limit
// :: INFO reduce.MergeManagerImpl: Merging files, bytes from disk
// :: INFO reduce.MergeManagerImpl: Merging segments, bytes from memory into reduce
// :: INFO mapred.Merger: Merging sorted segments
// :: INFO mapred.Merger: Down to the last merge-pass, with segments left of total size: bytes
// :: INFO mapred.LocalJobRunner: / copied.
// :: INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
// :: INFO mapred.Task: Task:attempt_local1592166400_0001_r_000000_0 is done. And is in the process of committing
// :: INFO mapred.LocalJobRunner: / copied.
// :: INFO mapred.Task: Task attempt_local1592166400_0001_r_000000_0 is allowed to commit now
// :: INFO output.FileOutputCommitter: Saved output of task 'attempt_local1592166400_0001_r_000000_0' to hdfs://192.168.62.129:9000/user/vm/sort_out/_temporary/0/task_local1592166400_0001_r_000000
// :: INFO mapred.LocalJobRunner: reduce > reduce
// :: INFO mapred.Task: Task 'attempt_local1592166400_0001_r_000000_0' done.
// :: INFO mapred.LocalJobRunner: Finishing task: attempt_local1592166400_0001_r_000000_0
// :: INFO mapred.LocalJobRunner: reduce task executor complete.
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_local1592166400_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
4. 可能出现的问题
4.1 权限问题,无法访问HDFS
修改集群hdfs-site.xml配置,关闭hadoop集群的权限校验。
|
<property> <name>dfs.permissions</name> <value>false</value> </property> |
4.2 出现NullPointerException异常
在环境变量中配置%HADOOP_HOME%为C:\Download\hadoop-2.6.0\
下载winutils.exe和hadoop.dll到C:\Download\hadoop-2.6.0\bin
注意:网上很多资料说的是下载hadoop-common-2.2.0-bin-master.zip,但很多不支持hadoop2.6.0版本。需要下载支持hadoop2.6.0版本的程序。
4.3 程序执行失败
需要执行Run on Hadoop,而不是Java Application。

搭建Hadoop2.6.0+Eclipse开发调试环境的更多相关文章
- 搭建Hadoop2.6.0+Eclipse开发调试环境(以及log4j.properties的配置)
上一篇在win7虚拟机下搭建了hadoop2.6.0伪分布式环境.为了开发调试方便,本文介绍在eclipse下搭建开发环境,连接和提交任务到hadoop集群. 1. 环境 Eclipse版本Luna ...
- 搭建Hadoop2.5.2+Eclipse开发调试环境
一.简介 为了开发调试方便,本文介绍在Eclipse下搭建开发环境,连接和提交任务到Hadoop集群. 二.安装前准备: 1)Eclipse:Luna 4.4.1 2)eclipse插件:hadoop ...
- ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
本文进行操作的虚拟机是在伪分布式配置的基础上进行的,具体配置本文不再赘述,请参考本人博文:ubuntu14.04搭建Hadoop2.9.0伪分布式环境 本文主要参考 给力星的博文——Hadoop集群安 ...
- windows下用eclipse+goclipse插件+gdb搭建go语言开发调试环境
windows下用eclipse+goclipse插件+gdb搭建go语言开发调试环境 http://rongmayisheng.com/post/windows%E4%B8%8B%E7%94%A ...
- Solr4.8.0源码分析(4)之Eclipse Solr调试环境搭建
Solr4.8.0源码分析(4)之Eclipse Solr调试环境搭建 由于公司里的Solr调试都是用远程jpda进行的,但是家里只有一台电脑所以不能jpda进行调试,这是因为jpda的端口冲突.所以 ...
- 在Win7虚拟机下搭建Hadoop2.6.0+Spark1.4.0单机环境
Hadoop的安装和配置可以参考我之前的文章:在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境. 本篇介绍如何在Hadoop2.6.0基础上搭建spark1.4.0单机环境. 1. 软件准备 ...
- 搭建Hadoop2.6.0+Spark1.1.0集群环境
前几篇文章主要介绍了单机模式的hadoop和spark的安装和配置,方便开发和调试.本文主要介绍,真正集群环境下hadoop和spark的安装和使用. 1. 环境准备 集群有三台机器: master: ...
- PHP开发调试环境配置(基于wampserver+Eclipse for PHP Developers )
1 软件准 WampServer 下载地址:http://www.wampserver.com/en/#download-wrapper 我下的是 里面包含了搭建PHP必须的4个软件: 1. ...
- 配置Windows 2008 R2 64位 Odoo 8.0 源码PyCharm开发调试环境
安装过程中,需要互联网连接下载python依赖库: 1.安装: Windows Server 2008 R2 x64标准版 2.安装: Python 2.7.10 amd64 到C:\Python27 ...
随机推荐
- newInstance和new的区别(good)
从JVM 的角度看,我们使用关键字new创建一个类的时候,这个类可以没有被加载.但是使用newInstance()方法的时候,就必须保证:1.这个 类已经加载:2.这个类已经连接了.而完成上面两个步骤 ...
- 学习安卓开发过程中遇到关于R.Java文件的问题
在学习安卓开发过程时,遇到R.java生成问题,总结几个方法解决. 1.首先必须做的就是检查代码的正确性,存在错误的代码,不编译生成R.java 2.右键点项目,选择 Android Tools -& ...
- WPF MVVM 如何在ViewModel中操作View中的控件事件
(在学习Wpf的时候,做一个小例子,想在TextBox改变后,检验合法性,并弹出提示.在找了很多贴后,发现这个小例子,抄袭过来,仅供参考. 最后也找到了适合自己例子的办法:在出发TextChanged ...
- tp3.2博客详情页面查询上一篇下一篇
- Grunt压缩图片和JS
今天我们来说一下用Grunt来压缩图片和JS吧! 首先要安装插件: 这是压缩图片的; npm install --save-dev gulp-imagemin 这是压缩JS的: npm install ...
- HTML 5入门知识(一)
了解HTML 5 HTML5 并非仅仅用来表示web内容,它的使命是将web带入一个成熟的应用平台,在这个平台上,视频.音频.图像.动画,以及与电脑的交互都被标准化. HTML 5概述 HTML 5实 ...
- 2018年哔哩哔哩bilibili前端开发工程师在线笔试1
##基础编程能力考查(共1题) 给定一个数组,其中有n(1<n<10000)个整数,检查是否能通过修改不多余一个元素就能让数组从小到大排列. 例1: 输入:[4,2,3] 输出:true ...
- Selenium2学习(十)-- iframe定位
前言 有很多小伙伴在拿163作为登录案例的时候,发现不管怎么定位都无法定位到,到底是什么鬼呢,本篇详细介绍iframe相关的切换 以http://mail.163.com/登录页面10为案例,详细介绍 ...
- Vaadin学习笔记——Page、UI和View在用法上的区别
前言 在Vaadin技术框架中会出现三种不同的类,用于架构Web应用.它们分别是:Page.UI.View.本文将对这三者从使用角度进行比较,试图分析三者的异同.本文完全原创,我可不是在强调版权,我只 ...
- IOS 即时通讯的框架 配置环境
一.了解XMPP 协议(标准)XMPP 即时通讯协议SGIP 短信网关协议 这手机发短信 移动支付和网页支付 0x23232[0,1] 0x23232 0x23232 0x23232 只有协议,必须会 ...