吴裕雄--天生自然python机器学习:K-近邻算法介绍
k-近邻算法概述
简单地说,谷近邻算法采用测量不同特征值之间的距离方法进行分类。
优 点 :精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
它的工作原理是:存在一个样本数
据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据
与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的
特征进行比较,然后算法提取样本集中特征最相似数据(最 近 邻 )的分类标签。一般来说,我们
只选择样本数据集中前&个最相似的数据,这就是&-近邻算法中&的出处,通常*是不大于20的整数。
最 后 ,选择&个最相似数据中出现次数最多的分类,作为新数据的分类。
使用&-近邻算法分类爱情片和1动作片。有人曾经统计过
很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻_ 头数。假如有一部未看过
的电影,如何确定它是爱情片还是动作片呢?我们可以使用_ 来解决这个问题。

首先我们需要知道这个未知电影存在多少个打斗镜头和接吻镜头,图2-1中问号位置是该未
知电影出现的镜头数图形化展示,具体数字参见表2-1。

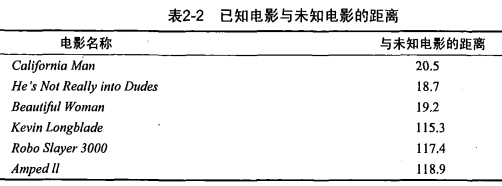
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到乂个距
离最近的电影。假定K近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部
电影全是爱情片,因此我们判定未知电影是爱情片。
k-近邻算法的一般流程
(1)收集数据:可以使用任何方法。
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式。
(3)分析数据:可以使用任何方法。
(4)训练算法:此步驟不适用于k近邻算法。
(5)测试算法:计算错误率。
(6)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行女-近邻算法判定输
入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
from numpy import *
import operator def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
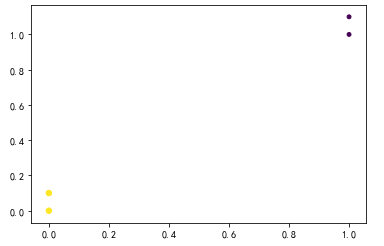
import matplotlib
import matplotlib.pyplot as plt from numpy import * def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels fig = plt.figure()
ax = fig.add_subplot(111)
datingDataMat,datingLabels = createDataSet()
ax.scatter(datingDataMat[:,0], datingDataMat[:,1],15.0*array([1,1,2,2]),15.0*array([1,1,2,2]))
plt.show()
从文本文件中解析数据
k-近邻算法将
每组数据划分到某个类中,其伪代码如下:
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的走个点;
(4)确定前灸个点所在类别的出现频率;
(5)返回前女个点出现频率最高的类别作为当前点的预测分类。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]

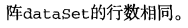
使用欧氏距离公式
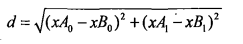
例如,点(0,0)与(1, 2)之间的距离计算为:
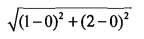
如果数据集存在4个特征值,则点(1,0, 0,1)与(7, 6, 9,4)之间的距离计算为:
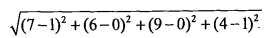
计算完所有点之间的距离后,可以对数据按照从小到大的次序排序。然后,确定前k个距离
最小元素所在的主要分类.使用这个分类器可以完成很多分类任务.
import operator
import matplotlib
import matplotlib.pyplot as plt from numpy import * def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] a = classify0([0,0],datingDataMat,datingLabels,3)
print('预测结果:',a)

如何测试分类器
分类器并不会得到百分百正确的结果,我们可以使用多种方法检测分类器的正确率。
此外分类器的性能也会受到多种因素的影响,如分类器设置和数据集等。不同的算法在不同数据
集上的表现可能完全不同。
为了测试分类器的效果,我们可以使用已知答案的数据,当然答案不能告诉分类器,检验分
类器给出的结果是否符合预期结果。通过大量的测试数据,我们可以得到分类器的错误率—— 分
类器给出错误结果的次数除以测试执行的总数。错误率是常用的评估方法,主要用于评估分类器
在某个数据集上的执行效果。完美分类器的错误率为0,最差分类器的错误率是1.0,在 这 种情 况
下 ,分类器根本就无法找到一个正确答案。
吴裕雄--天生自然python机器学习:K-近邻算法介绍的更多相关文章
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:KNN-近邻算法在手写识别系统上的应用
需要识别的数字已经使用图形处理软件,处理成具有相同的色 彩和大小® : 宽髙是32像 素 *32像素的黑白图像.尽管采用文本格式存储图像不能有效地利用内 存空间,但是为了方便理解,我们还是将图像转换为 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有 30%的值是缺失的.下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归 和随机梯度上升算法来预测 ...
- 吴裕雄--天生自然python机器学习:Logistic回归
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
随机推荐
- C++ 一个exe的两个运行实例之间共享数据
#pragma data_seg("Shared") volatile int iNum = 0; #pragma data_seg() #pragma comment(linke ...
- VC++ DLL 1 一点概念
1.在写代码的时候,我们可能会经常要用到一些封装好的函数或者类,这些可能是C/C++的标准库提供的,也可能是由别人开发的非标准库,这个时候就会涉及到动态链接库或者静态链接库的使用了. 举个例子,做图像 ...
- M内核迎来大BOSS,ARM发布Cortex-M55配NPU Ethos-U55 ,带来无与伦比的性能提升
说明: 全球顶级嵌入式会展Embedded Word2020这个月底就开了,各路厂家都将拿出看家本领. 先回顾下去年的消息: 1.去年年初的时候ARM发布Armv8.1-M架构,增加了Arm Heli ...
- LeetCode 543. Diameter of Binary Tree 二叉树的直径 (C++/Java)
题目: Given a binary tree, you need to compute the length of the diameter of the tree. The diameter of ...
- PAT Advanced 1102 Invert a Binary Tree (25) [树的遍历]
题目 The following is from Max Howell @twitter: Google: 90% of our engineers use the sofware you wrote ...
- 寒假day14
今天去医院看脸了,回来继续写论文.
- Linux--Shell基本运算符
参考:http://www.runoob.com/linux/linux-shell-basic-operators.html
- Feign整合测试
1.测试使用 (1)服务调用方引入依赖 <dependency> <groupId>org.springframework.cloud</groupId> < ...
- 深度学习常用的数据源(MNIST,CIFAR,VOC2007系列数据)
MINIST手写数据集 压缩包版: http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz http://yann.lecun.com/ ...
- php错误和异常的重定向
通过重定向错误或异常,我们可以更安全的显示错误信息,一般也用来记录错误和异常日志. 参数可以是全局函数名,也可以是类中的方法,非静态方法通过数组传递类名和方法名进去, 静态方法直接带命名空间和类名,看 ...