Spark中Task数量的分析
本文主要说一下Spark中Task相关概念、RDD计算时Task的数量、Spark Streaming计算时Task的数量。
Task作为Spark作业执行的最小单位,Task的数量及运行快慢间接决定了作业运行的快慢。
开始
先说明一下Spark作业的几个核心概念:
Job(作业):Spark根据行动操作触发提交作业,以行动操作将我们的代码切分为多个Job。
Stage(调度阶段):每个Job中,又会根据宽依赖将Job划分为多个Stage(包括ShuffleMapStage和ResultStage)。
Task(任务):真正执行计算的部分。Stage相当于TaskSet,每个Stage内部包含了多个Task,将各个Task下发到各个Executor执行计算。
每个Task的处理逻辑完全一样,不同的是对应处理的数据。即:移动计算而不是移动数据。
Partition(分区):这个是针对RDD而言的,RDD内部维护了分区列表,表示数据在集群中存放的不同位置。
Job、Stage、Task的对应关系如下:
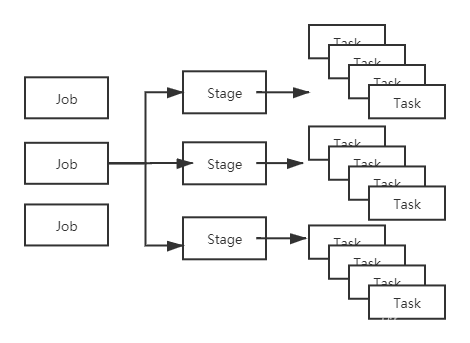
Task是真正干活的,所以说是它间接决定了Spark程序的快慢也不过分。
再看看Spark任务提交时的几个相关配置:
num-executors:配置执行任务的Executor的数量。
executor-cores:每个Executor的核的数量。此核非彼核,它不是机器的CPU核,可以理解为Executor的一个线程。
每个核同时只可以执行一个Task。
也就是说一个Spark应用同时执行的任务数 = 用于执行任务的Executor数 * 每个Executor的核数。
spark.executor.memory:每个Executor的内存大小。
spark.default.parallelism:RDD的默认分区数。
在我们没有指定这个参数的前提下,如果是shuffle操作,这个值默认是父RDD中分区数较大的那个值;如果是普通操作,这个值的默认大小取决于集群管理器(YARN, Local这些)。
以YARN为例,如果我们没有指定,它的大小就是所有用于执行任务的Executor核的总数。
spark.sql.shuffle.partitions:这个配置是针对于Spark SQL在shuffle时的默认分区数。默认值是200。只对Spark SQL起作用。
RDD计算时Task的数量
在基于RDD计算时,Task的数量 = RDD的分区数。
所以调整RDD分区的数量就可以变相的调整Task的数量。
所以当RDD计算跑的很慢时,可以通过适当的调整RDD分区数来实现提速。
看看Spark.parallelize生成RDD时的源码实现:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
// 这里的taskScheduler.defaultParallelism就是
// 取的配值中spark.default.parallelism的值。
def defaultParallelism: Int = {
assertNotStopped()
taskScheduler.defaultParallelism
}
可以发现通过Spark.parallelize创建的RDD分区,如果我们不指定分区数,那么分区数就是由配置的spark.default.parallelism来决定。
Spark读Hive、HDFS时的Task数量
这块之后补上来。。。
Spark Streaming流处理时的Task数量
Spark Streaming作为Spark中用于流处理的一员,它的原理就是运行一个接收器接收数据,然后将接收的数据按块进行存储,之后划分Job,执行Task处理数据。
ok,Spark Streaming最后也会转换成Task进行数据的处理,也就是Task运行速度也会影响它处理数据的速度。
Spark Streaming中Task的数量是由用来存储接收到数据的Block数来决定的。
那么只要控制Block的数量就可以控制Task的数量。
如下代码所示,Block是由一个定时器定时生成的。
// 块生成间隔时间
private val blockIntervalMs = conf.getTimeAsMs("spark.streaming.blockInterval", "200ms")
// 一个定时器,按块生成间隔时间定时根据接收到的数据生成块。
private val blockIntervalTimer = new RecurringTimer(clock, blockIntervalMs, updateCurrentBuffer, "BlockGenerator")
所以Block的数量 = 批处理间隔时间 / 块生成间隔时间。
块生成间隔时间是由配置spark.streaming.blockInterval决定的,默认是200ms,最小是50ms。
所以当Spark Streaming的Task数量成为性能的瓶颈时,可以通过调整参数来调整Task的数量。
总结
1、Task是Spark的最小执行单位,Executor每个核同时只能执行一个Task。
2、RDD计算时,Task数量与分区数对应;Spark Streaming中,Task数量由Block数决定。
3、根据分配的资源以及作业的运行情况,适当调整Task数量。
4、移动计算而不是移动数据。
end. 个人理解,如果偏差欢迎指正。
个人公众号:码农峰,定时推送行业资讯,持续发布原创技术文章,欢迎大家关注。
Spark中Task数量的分析的更多相关文章
- Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数
Spark中Task,Partition,RDD.节点数.Executor数.core数目的关系和Application,Driver,Job,Task,Stage理解 from:https://bl ...
- 【原】 Spark中Task的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Stage的提交 http://www.cnblogs.com/yourarebest/p/5356769.html Spark中 ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- 【原】Spark中Master源码分析(一)
Master作为集群的Manager,对于集群的健壮运行发挥着十分重要的作用.下面,我们一起了解一下Master是听从Client(Leader)的号召,如何管理好Worker的吧. 1.家当(静态属 ...
- Spark中决策树源码分析
1.Example 使用Spark MLlib中决策树分类器API,训练出一个决策树模型,使用Python开发. """ Decision Tree Classifica ...
- 【原】Spark中Client源码分析(一)
在Spark Standalone中我们所谓的Client,它的任务其实是由AppClient和DriverClient共同完成的.AppClient是一个允许app(Client)和Spark集群通 ...
随机推荐
- webfrom 控件
服务器基本控件: button: text属性 linkbutton:text属性,它是一个超链接模样的普通button hyperlink: navigateurl:链接地址,相当于<a> ...
- SQL Server Driver for PHP之sqlsrv相关函数
SQL Server Driver for PHP 包含以下函数: 函数 说明 sqlsrv_begin_transaction 开始事务. sqlsrv_cancel 取消语句:并放弃相应语句的所有 ...
- Mongo学习记录
引子 最近做项目利用mongo记录的日志做数据统计.着了非关系型数据库的迷,于是乎买了本<MongoDB实战>学习了一番.记录一下学习笔记,共享之. 准备 我在自己的Linux服务器上装了 ...
- P4327 彼得潘框架
题意翻译 “彼得·潘框架”是一种装饰文字,每一个字母都是由一个菱形框架.一个彼得·潘框架看起来像这样 (x是字母,#是框架): ..#.. .#.#. #.X.# .#.#. ..#.. 然而,只是一 ...
- nginx简单安装
虚拟机首先要求ping www.baidu.com 下载: 解压: 创建用户: [root@nginx ~]# useradd -M -s /sbin/nologin nginx-M 不创建加目录 ...
- Perl:只是把“^”作为匹配的单字:只是匹配每一行的开头 $lines =~ s/^/file_4_ex_ch7.txt: /gm;
Perl:只是把“^”作为匹配的单字:只是匹配每一行的开头 $lines =~ s/^/file_4_ex_ch7.txt: /gm;
- [LC] 796. Rotate String
We are given two strings, A and B. A shift on A consists of taking string A and moving the leftmost ...
- 吴裕雄--天生自然C语言开发:函数指针
#include <stdio.h> int max(int x, int y) { return x > y ? x : y; } int main(void) { /* p 是函 ...
- 堆排Heap Sort
1. #define LeftChild(i) (2*(i)+1) void PercDown(vector<int>&num, int i, int n) { int child ...
- 104)PHP,目录树状输出
使用特定数量的缩进达到树状目的! 核心问题,计算需要缩进的数量! 缩进级别,与递归调用深度保持一致.每当执行一级递归操作,所找到的文件的缩进级别+; 语法实现: 增加一个参数,表示当前函数调用的深度级 ...