A Statistical View of Deep Learning (V): Generalisation and Regularisation
A Statistical View of Deep Learning (V): Generalisation and Regularisation
We now routinely build complex, highly-parameterised models in an effort to address the complexities of modern data sets. We design our models so that they have enough 'capacity', and this is now second nature to us using the layer-wise design principles of deep learning. But some problems continue to affect us, those that we encountered even in the low-data regime, the problem of overfitting and seeking better generalisation.
The classical description of deep feedforward networks in part I or of recurrent networks inpart IV established maximum likelihood as the the underlying estimation principle for these models. Maximum Likelihood (ML) [1] is an elegant, conceptually simple and easy to implement estimation framework. And it has several statistical advantages, including consistency and asymptotic efficiency. Deep learning has shown just how effective ML can be. But it is not without its disadvantages, the most prominent being a tendency for overfitting. Overfitting is the problem of all statistical sciences, and ways of dealing with this are abound. The general solution reduces to considering an estimation framework other than maximum likelihood — this penultimate post explores some of the available alternatives.
Regularisers and Priors
The principle technique for addressing overfitting in deep learning is by regularisation — adding additional penalties to our training objective that prevents the model parameters from becoming large and from fitting to the idiosyncrasies of the training data. This transforms our estimation framework from maximum likelihood into amaximum penalised likelihood, or more commonly maximum a posteriori (MAP) estimation (or a shrinkage estimator). For a deep model with loss function L(θ) and parameters θ, we instead use the modified loss that includes a regularisation function R:
λ is a regularisation coefficient that is a hyperparameter of the model. It is also commonly known that this formulation can be derived by considering a probabilistic model that instead of a penalty, introduces a prior probability distribution over the parameters. The loss function is the negative of the log joint probability distribution:
The table shows some common regularisers, of which the L1 and L2 penalties are used in deep learning. Most other regularisers in the probabilistic literature cannot be added as a simple penalty function, but are instead given by a hierarchical specification (and whose optimisation is also more involved, requiring some form of alternating optimisation). Amongst the most effective are the sparsity inducing penalties such as Automatic Relevance Determination, the Normal-Inverse Gaussian, the Horseshoe, and the general class of Gaussian scale-mixtures.
| Name | R(θ) | p(θ) |
|---|---|---|
| L2/Gaussian/Weight Decay | 1λ∥θ∥22 | N(θ|0;λ) |
| L1/Laplace/Lasso | 1λ∥θ∥1 | Lap(θ|0;λ) |
| p-norms | ∥θ∥p;p>0 | exp(−λ∥θ∥p) |
| Total variation | λ|Δθ|;Δθ=(θj−θj−1) | |
| Fused Lasso | α|θ|+β|Δθ| | |
| Cauchy | −∑ilog(θ2i+γ2) | 1πγγ2(θ−μ)2+γ2 |
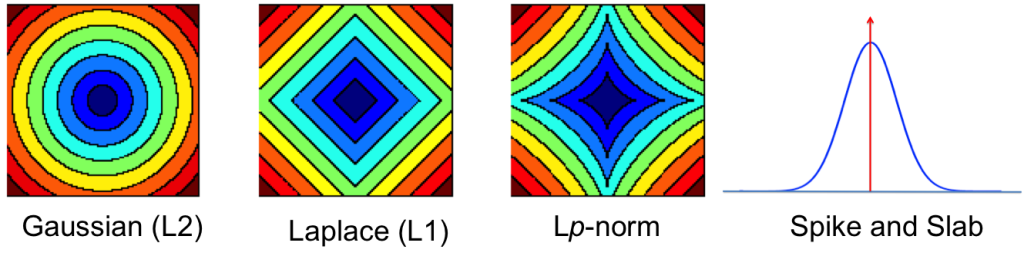
Contours showing the shrinkage effects of different priors.
Invariant MAP Estimators
While these regularisers may prevent overfitting to some extent, the underlying estimator still has a number of disadvantages. One of these is that MAP estimators are not invariant to smooth reparameterisations of the model. MAP estimators reason only using the density of the posterior distribution on parameters and their solution thus depends arbitrarily on the units of measurement we use. The effect of this is that we get very different gradients depending on our units, with different scaling and behaviour that impacts our optimisation. The most general way of addressing this is to reason about the entiredistribution on parameters instead. Another approach is to design an invariant MAP estimator [2], where we instead maximise the modified probabilistic model:
where I(θ) is the Fisher information matrix. It is the introduction of the Fisher information that gives us the transformation invariance, although using this objective is not practically feasible (requiring up to 3rd order derivatives). But this is an important realisation that highlights an important property we seek in our estimators. Inspired by this, we can use the Fisher information in other ways to obtain invariant estimators (and better-behaved gradients). This builds the link to, and highlights the importance of the natural gradient in deep learning, and the intuition and use of the minimum message length from information theory [3].
Dropout: With and Without Inference
Since the L2 regularisation corresponds to a Gaussian prior assumption on the parameters, this induces a Gaussian distribution on the hidden variables of a deep network. It is thus equally valid to introduce regularisation on the hidden variables directly. This is what dropout [4], one of the major innovations in deep learning, uses to great effect. Dropoutalso moves a bit further away from MAP estimation and closer to a Bayesian statistical approach by using randomness and averaging to provide robustness.
Consider an arbitrary linear transformation layer of a deep network with link/activation function σ(⋅), input h, parameters W and the dimensionality of the hidden variable D. Rather than describing the computation as a warped linear transformation, dropout uses a modified probabilistic description. For i=1, ... D, we have two types of dropout:
In the Bernoulli case, we draw a 1/0 indicator for every variable in the hidden layer and include the variable in the computation if it is 1 and drop it out otherwise. The hidden units are now random and we typically call such variables latent variables. Dropout introduces sparsity into the latent variables, which in recent times has been the subject of intense focus in machine learning and an important way to regularise models. A feature of dropout is that it assumes that the the dropout (or sparsity probability) is always known and fixed for the training period. This makes it simple to use and has shown to provide an invaluable form of regularisation.
You can view the indicator variables z as a way of selecting which of the hidden features are important for computation of the current data point. It is natural to assume that the best subset of hidden features is different for every data point and that we should find and use the best subset during computation. This is the default viewpoint in probabilistic modelling, and when we make this assumption the dropout description above corresponds to an equally important tool in probabilistic modelling — that of models with spike-and-slab priors [5]. A corresponding spike-and-slab-based model, where the indicator variables are called the spikes and the hidden units, the slabs, would be:
We can apply spike-and-slab priors flexibly: it can be applied to individual hidden variables, to groups of variables, or to entire layers. In this formulation, we must now infer the sparsity probability p(z|y,h) — this is the hard problem dropout sought to avoid by assuming that the probability is always known. Nevertheless, there has been much work in the use of models with spike-and-slab priors and their inference, showing that these can be better than competing approaches [6]. But an efficient mechanism for large-scale computation remains elusive.
Summary
The search for more efficient parameter estimation and ways to overcome overfitting leads us to ask fundamental statistical questions about our models and of our chosen approaches for learning. The popular maximum likelihood estimation has the desirable consistency properties, but is prone to overfitting. To overcome this we moved to MAP estimation that help to some extent, but its limitations such as lack of transformation invariance leads to scale and gradient sensitivities that we can seek to ameliorate by incorporating the Fisher information into our models. We could also try other probabilistic regularisers whose unknown distribution we must average over. Dropout is one way of achieving this without dealing with the problem of inference, but were we to consider inference, we would happily use spike-and-slab priors. Ideally, we would combine all types of regularisation mechanisms, those that penalise both the weights and activations, assume they are random and that average over their unknown configuration. There are many diverse views on this issue; all point to the important research still to do.
Some References
| [1] | Lucien Le Cam, Maximum likelihood: an introduction, International Statistical Review/Revue Internationale de Statistique, 1990 |
| [2] | Pierre Druilhet, Jean-Michel Marin, others, Invariant HPD credible sets and MAPestimators, Bayesian Analysis, 2007 |
| [3] | Ian H Jermyn, Invariant Bayesian estimation on manifolds, Annals of statistics, 2005 |
| [4] | Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov, Dropout: A simple way to prevent neural networks from overfitting, The Journal of Machine Learning Research, 2014 |
| [5] | Hemant Ishwaran, J Sunil Rao, Spike and slab variable selection: frequentist and Bayesian strategies, Annals of Statistics, 2005 |
| [6] | Shakir Mohamed, Zoubin Ghahramani, Katherine A Heller, Bayesian and L1 Approaches for Sparse Unsupervised Learning, Proceedings of the 29th International Conference on Machine Learning (ICML-12), 2012 |
A Statistical View of Deep Learning (V): Generalisation and Regularisation的更多相关文章
- A Statistical View of Deep Learning (III): Memory and Kernels
A Statistical View of Deep Learning (III): Memory and Kernels Memory, the ways in which we remember ...
- A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems
A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems Recurrent neural netw ...
- A Statistical View of Deep Learning (II): Auto-encoders and Free Energy
A Statistical View of Deep Learning (II): Auto-encoders and Free Energy With the success of discrimi ...
- A Statistical View of Deep Learning (I): Recursive GLMs
A Statistical View of Deep Learning (I): Recursive GLMs Deep learningand the use of deep neural netw ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- translation of 《deep learning》 Chapter 1 Introduction
原文: http://www.deeplearningbook.org/contents/intro.html Inventors have long dreamed of creating mach ...
- 深度学习基础 Probabilistic Graphical Models | Statistical and Algorithmic Foundations of Deep Learning
目录 Probabilistic Graphical Models Statistical and Algorithmic Foundations of Deep Learning 01 An ove ...
随机推荐
- android 43 SQLite数据库
SQLite数据库很小,占用内存只有几百K,安卓和IOS都是用的SQLite数据库. 页面: <LinearLayout xmlns:android="http://schemas.a ...
- etrace 跟踪程序函数动态执行流程
https://github.com/elcritch/etrace 窗口1: 监控窗口,执行监控程序,显示监控结果 [root@monitor example]# pwd /root/etrace- ...
- winserve2008下不能运行winXP下开发的应用程序→更改“兼容性”
winserve2008下不能运行winXP下开发的应用程序 对策:更该“兼容性”
- 快速记忆JavaScript中exec和match的使用
JS模式匹配中exec,match用得非常多,所以掌握其用法对我们进行字符串的处理帮助非常大 1.exec的定义其用法 exec与match主要的不同是,exec是正则表达式里面的方法. ...
- codevs 访问艺术馆
/* codevs 1163 访问艺术馆 红果果的树形dp*/ #include<iostream> #include<cstdio> #include<cstring& ...
- 10.18 noip模拟试题
分火腿 (hdogs.pas/.c/.cpp) 时间限制:1s:内存限制 64MB 题目描述: 小月言要过四岁生日了,她的妈妈为她准备了n根火腿,她想将这些火腿均分给m位小朋友,所以她可能需要切火腿. ...
- <input value="hidden">的作用
这样子上个页面的参数可以保存在这个页面,为下个页面获取参数做准备,在这个页面表单提交的时候下个页面可以获取参数
- .net 学习路线感想
从上到大学到现在工作,已经有六年多了,发现学习编程到以开发为工作也是一个挺长的过程的. 大学中,从c语言到java.C#到其他各种语言的学习,还有其他知识的学习如:数据库(oracle.sql Ser ...
- VS2010在WIN7 64位系统下架设网站及路由器配置
步骤一:安装IIS 打开[控制面板]-[程序和功能],在左侧进入[打开或关闭windows功能],按照下图选择Internet信息项目下的子选项并安装: 步骤二:配置应用程序池 打开[控制面板]-[管 ...
- Datum Form Goole Android
1. <TurboChargeYourUI-How to make your AndroidUI fast and efficient> 2. <The World of List ...