Hadoop MapReduce基本原理
一、什么是:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
源于Google MapReduce论文(04年)。
MapReduce的核心是:分而治之,并行处理;以及其调度和处理数据的自动化。
Hadoop中MR的主要内容:
hadoop序列化writable接口,数据类型
应用开发 (debug 单元测试)解决基本数据处理,作业调优
工作机制 作业提交流程,作业调度,shuffle与排序
MR类型 输入输出类型
特性:二次排序(全排、部分排),join
压缩算法
二、基本流程:
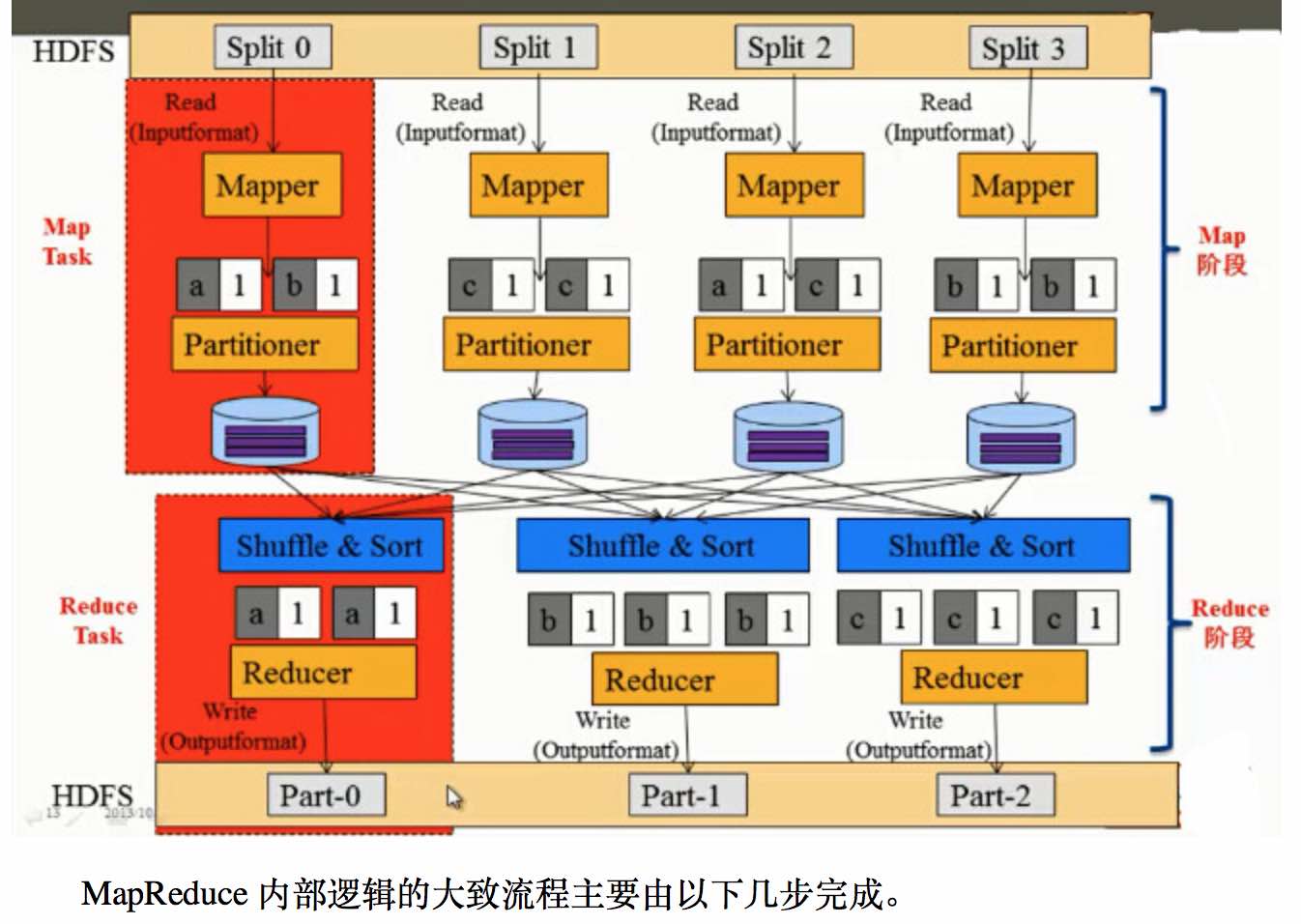
1、MR中主要是Map和Reduce两个阶段,其中基本流程是:
1、mr的数据处理单位是一个split,一个split对应一个map任务,处理时会有多个map任务同时运行;当map从HDFS上读取一个split时,这里会有“移动计算,不移动数据”的机制来减少网络的数据传输,使得效率能最大化;
2、获取到split时,默认会以TextInputFormat的格式读入,文件中的字符位置的偏移量作为 key,以及每一行的数据作为 value;
3、之后则进入map函数中进行处理,这个阶段可以获取需要的数据并加以处理,并以key value的形式写出,作为后面reduce函数的输入;
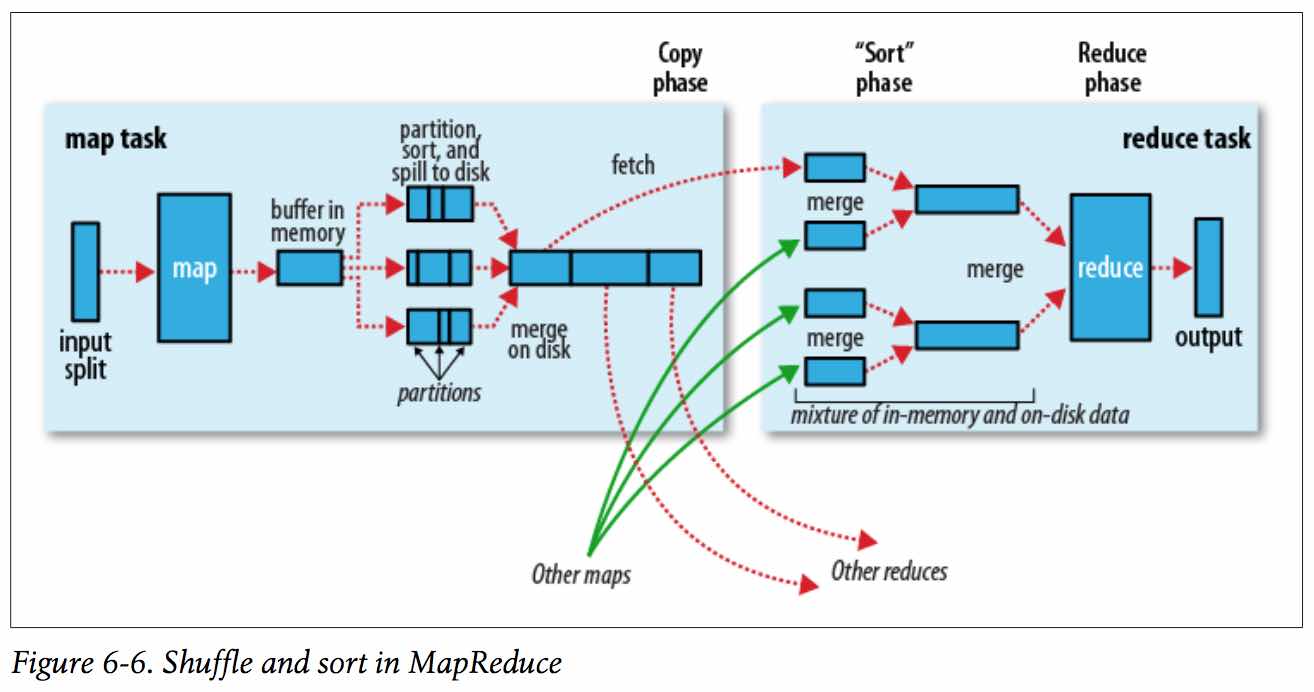
4、map到reduce之间会有一个shuffle的过程,大致过程是把不同key利用partitioner分散到各个reduce节点上去;
5、在reduce上会先通过 比较排序(前面shuffl会有预排序) 进行文件的归并,之后进入reduce函数,在每个reduce函数中key是唯一的,对应的value则是一个 Iterable接口类型,通过Iterable可以遍历所有当前key对应的所有value;
6、之后在reduce中对数据进行处理后,利用OutputFormat对处理后的key value保存到HDFS上即完成了整个流程。
注:一个split的大小计算:max( minimumSize, min( maximumSize, blockSize ));
通常 blockSize 在 minimumSize和maximumSize之间,所以一般分片大小就是块大小。
2、流程图:
3、编程中可定制的类:
InputFormat —> Mapper —> Partitioner (HashPartitioner) —> Combiner —> Reducer —> OutputFormat
4、shuffle过程:map输出 到 reduce获取数据的过程。
三、优缺点:
优点:
Hadoop MapReduce基本原理的更多相关文章
- 从分治算法到 Hadoop MapReduce
从分治算法说起 要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 .其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再 ...
- python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍 59888745@qq.com 大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽), 把用户的交易 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货
文章为作者原创,未经许可,禁止转载. -Sun Yat-sen University 冯兴伟 一. 项目简介: 电子商务的发展以及电商平台的多样化,类似于京东和天猫这种拥有过亿用户的在线购 ...
- Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simpleMapReduce program for Hadoop in thePython prog ...
随机推荐
- 【单调队列+尺取】HDU 3530 Subsequence
acm.hdu.edu.cn/showproblem.php?pid=3530 [题意] 给定一个长度为n的序列,问这个序列满足最大值和最小值的差在[m,k]的范围内的最长子区间是多长? [思路] 对 ...
- 什么是JNI?
JNI是Java Native Interface的缩写,它提供了若干的API实现了Java和其他语言的通信(主要是C和C++)
- 洛谷 [P3224] 永无乡
Treap 的合并 首先感谢 @Capella 的DeBug 其次,这是由一个 & 号引发的血案 注意对于所有修改操作都要 & Treap的合并, 启发式合并,对于每一个节点都 ins ...
- 标准C程序设计七---12
Linux应用 编程深入 语言编程 标准C程序设计七---经典C11程序设计 以下内容为阅读: <标准C程序设计>(第7版) 作者 ...
- db2数据备份与恢复
备份:先关掉所有tomcat运行:db2cmd db2Stop force db2Start DB2 FORCE APPLICATIONS ALL DB2 BACKUP DATABASE histes ...
- 关于FileZilla Server的安装问题
网上很多FileZilla Server教程到最后一步在本机上测试访问成功就没了,实际上还是不完整的,一般情况下外网还是访问不了,外网访问同样很重要. 可能有点童鞋会说安装的时候防火墙提示的时候我也点 ...
- hzwer与逆序对
codevs——4163 hzwer与逆序对 貌似这个题和上个题是一样的((⊙o⊙)…) 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 黄金 Gold 题解 题目 ...
- mybatis注解@selectKey对于db2数据库的使用
在新增时返回当前新增的主键. 数据库:DB2 用的是mybatis的@selectKey 代码: @InsertProvider(type = Test.class,method="inse ...
- js dom 的常用属性和方法
1.对象集合: (1).all[]; (2).images[]; (3).anchors[]; (4).forms[]; (5).links[]; ...
- How to resolve 'Potential Leak' issue
-1 down vote favorite I am using the 'analyze' tool in xcode to check for potential leakages in my a ...