python——简单爬虫
因为要学习python,所以看到一些网站有很多文章。
如:http://python.jobbole.com/all-posts/
目标:
将某个网站脚本编程-》python模块这个分类下所有的文章标题和网址提取(就相当于一个目录索引了)
在目录中找东西总好过一页页点击网页上的下一页吧。
为什么用python来实现呢,因为实在太简单易用了。在不考虑效率的情况下是大大方便了我等小白
我感觉我用爬虫得几个原因:
自从百度的site、intitle、inurl等这类搜索命令失效之后搜索关键内容的灵活度降低了,找不到想要的内容
技术博客里面有很多文章分类,可是一个分类下的文章遗憾的就是没有目录,难道要一页一页地打开网页查找么
不过不试不知道,一个简单的爬虫也牵扯了挺多东西的,总结一下
1、正则表达式,为了一行代码,把正则表达式的东西又加深学习了一遍了,无分组捕获、命名捕获、零宽断言、贪婪模式等等以前没有听过的东东。具体自己去了解吧!
2、urllib的使用,简单的使用也会有问题,看错误如下
IOError: ('http protocol error', 0, 'got a bad status line', None)
http://blog.csdn.net/yueguanghaidao/article/details/11994229 中有解释是因为http://www.website.com/需要在域名后加"/",不然会报"IOError: ('http protocol error', 0, 'got a bad status line', None)”。我第一次抓取的网页有这个错误,加了“/”访问网页直接返回404。我换成urllib2就有错误“httplib.BadStatusLine”
后来发现IOERROR是因为那个坑爹的网页本来就有问题,前一刻访问好好的,程序没写完就变成了足彩网站了。我可以理解为网站管理员休假了么。
3、中文编码问题,成功抓取了可是显示了一片看不明白的东东。看了下encode(),decode()毫无头绪,我怎么知道用什么来解码啊
>>> print fi
['python chardet\xc4\xa3\xbf\xe9\xc5\xd0\xb6\xcf\xd7\xd6\xb7\xfb\xb1\xe0\xc2\xeb'
引用一段:出自http://www.linuxidc.com/Linux/2014-11/109853.htm
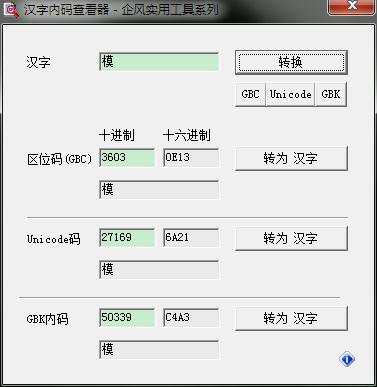
可以发现C4A3的编码是GBK,哈哈,别介意我作弊,然后成功解码。
#coding=utf-8
import urllib2
import re
import time
pattern_site_title=re.compile(r'(?<=<a class="archive-title" target="_blank" href=")(.*)(?="\stitle="(.*)">)')
for page in range(1,10):
url='http://python.jobbole.com/all-posts/page/%d/'%page
try:
url_open=urllib2.urlopen(url)
except:
exit()
print "urlopen error!" result=pattern_site_title.findall(url_open.read())
print "--------------------------------------------------------------"
for i in range(0,len(result)):
print "%s %s"%result[i]
time.sleep(3)
url_open.close()
正则表达式是个值得研究的地方,怎样才能匹配到自己需要的内容。简单的几行程序,实现了需要的功能。有更多的需要还可以在这基础上扩展。噢~~python真是个好东西
python——简单爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
随机推荐
- java中File类的常用方法总结
java中File类的常用方法 创建: createNewFile()在指定的路径创建一个空文件,成功返回true,如果已经存在就不创建,然后返回false. mkdir() 在指定的位置创建一个此抽 ...
- Java计算计算活了多少天
Java计算计算活了多少天 思路: 1.输入你的出现日期: 2.利用日期转换,将字符串转换成date类型 3.然后将date时间换成毫秒时间 4.然后获取当前毫秒时间: 5.最后计算出来到这个时间多少 ...
- Parallax Mapping
[Parallax Mapping] Parallax mapping belongs to the family of displacement mapping techniques that di ...
- Bootstrap Tooltip
[Bootstrap Tooltip] 1.设置Tooltip: 1)data-toggle="tooltip" 2)data-placement="top", ...
- 大数据入门到精通5--spark 的 RDD 的 reduce方法使用
培训系列5--spark 的 RDD 的 reduce方法使用 1.spark-shell环境下准备数据 val collegesRdd= sc.textFile("/user/hdfs/C ...
- redis主从复制踩到的那些坑
一.报错:* MASTER <-> SLAVE sync started # Error condition on socket for SYNC: No route to host解决: ...
- php苹果内购订单验证
/** * 21000 App Store不能读取你提供的JSON对象 * 21002 receipt-data域的数据有问题 * 21003 receipt无法通过验证 * 21004 提供的sha ...
- poj1308(并查集)
题目链接:http://poj.org/problem;jsessionid=436A34AE4BE856FB2DF9B264DCA9AA4E?id=1308 题意:给定一些边让你判断是否构成数. 思 ...
- word2vec详解与实战
有那么一句话 不懂word2vec,就别说自己是研究人工智能->机器学习->自然语言处理(NLP)->文本挖掘的 所以接下来我就从头至尾的详细讲解一下word2vec这个东西. 简要 ...
- HDU-1069.MonkeyandBanana(LIS)
本题大意:给出n个长方体,每种长方体不限量,让你求出如何摆放长方体使得最后得到的总高最大,摆设要求为,底层的长严格大于下层的长,底层的宽严格大于下层的宽. 本题思路:一开始没有啥思路...首先应该想到 ...