基于.NET Standard的分布式自增ID算法--美团点评LeafSegment
概述
前一篇文章讲述了最流行的分布式ID生成算法snowflake,本篇文章根据美团点评分布式ID生成系统文章,介绍另一种相对更容易理解和编写的分布式ID生成方式。
实现原理
Leaf这个名字是来自德国哲学家、数学家莱布尼茨的一句话:
There are no two identical leaves in the world
"世界上没有两片相同的树叶"
设置数据表主键自增是最简单的方案,缺点也很明显:
强依赖数据库,无法提供高可用
ID生成强依赖单台服务,无法横向扩展
很容易想到,如果我的应用每次申请一批id,插入数据时顺序取一个使用,即将耗尽时再去获取一批新的id,如此即可在一定程度上减弱与数据库的关系,同时将单台扩展延伸为获取id的步长。
负责发放ID的服务既可以使用MySQL服务,也可以使用Redis等服务。
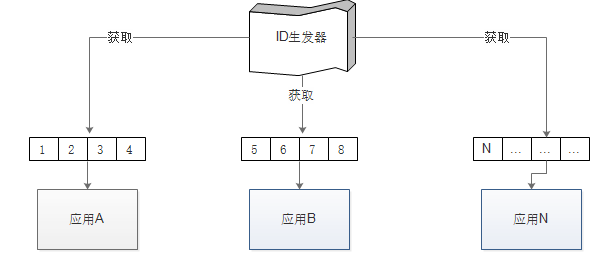
基于MySQL实现
首先我们建立一张数据库表
DROP TABLE IF EXISTS `leafsegment`;
CREATE TABLE `leafsegment` (
`biz_tag` varchar(255) NULL DEFAULT NULL,
`max_id` bigint(20) NULL DEFAULT 0,
`step` int(11) NULL DEFAULT 5000,
`desc` varchar(255) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT now()
); -- 添加一条初始化数据
INSERT INTO `leafsegment` VALUES ('test', 0, 5000, '测试', '2018-12-06 23:32:11');
数据库表如下图
![]()

biz_tag:业务标记,不同业务使用不同的值,可以最大限度地利用ID
max_id:当前已经被申请走的最大Id
step:每次申请Id的步长
desc:业务内容描述
update_time:最新一次申请时间
应用如何获取一批有效ID呢?
Begin
UPDATE leafsegment SET max_id=max_id+step,update_time=now() WHERE biz_tag='test'
SELECT biz_tag, max_id, step FROM leafsegment WHERE biz_tag='test'
Commit
在一个事务周期内完成max_id的更新,和最新数据的获取,天然解决了资源竞争问题。
而后,我们就可以在应用中将[max_id-step+1,max_id]闭区间的所有值作为ID来使用了。
基于Redis实现
Redis的实现更为简单,基本原理是利用了Redis的IncrBy命令实现原子加N,具体实现流程无须赘述。
代码实现
首先我们定义一个传递Step(步长)和MaxId(最大值)的DTO
/// <summary>
/// 数据单元
/// </summary>
public class DataVal
{
/// <summary>
/// 当前最大Id
/// </summary>
public long MaxId { get; set; } = 1;
/// <summary>
/// 当前步长
/// </summary>
public int Step { get; set; } = 1000;
}
这个类仅负责将ID生发器的数据传入核心类LeafSegment中。核心类的具体实现如下代码:
/// <summary>
/// 美团的Leaf Segment 方案
/// </summary>
public class LeafSegment
{
private long _currentStep = long.MaxValue >> 1;
private readonly Func<DataVal> _idGetAction;
private readonly ConcurrentQueue<long> _data = new ConcurrentQueue<long>();
private readonly AutoResetEvent _autoReset = new AutoResetEvent(false); /// <summary>
/// 美团的Leaf Segment 方案
/// </summary>
/// <param name="idGetAction">Id生成策略</param>
/// <param name="prefill">是否立即初始化数据</param>
public LeafSegment(Func<DataVal> idGetAction,bool prefill=false)
{
_idGetAction = idGetAction;
if (prefill)
{
FillData();
}
Loop();
} /// <summary>
/// 获取下一个Id
/// </summary>
/// <returns></returns>
public long NextId()
{
_autoReset.Set();
if (_data.TryDequeue(out var result))
{
return result;
} throw new Exception("Resource not enough");
} private void Loop()
{
(new Thread(_ =>
{
while (true)
{
_autoReset.WaitOne();
FillData();
}
}) {IsBackground = true}).Start(); } private void FillData()
{
//数量小于步长一半时触发拉新
while (_data.Count < (_currentStep >> 1))
{
var tmp = _idGetAction.Invoke();
_currentStep = tmp.Step;
for (var i = tmp.MaxId - tmp.Step + 1; i <= tmp.MaxId; i++)
{
_data.Enqueue(i);
}
}
}
}
此处需要注意的是LeafSegment构造函数的第一个入参IdGetAction是一个返回DataVal的回调函数,因此外部实现中可以在该回调函数中返回所需ID序列;
第二个参数prefill,该参数控制实例化LeafSegment对象时,是否同步调用获取ID区段,如该值为false,将会由启动的线程稍后补充数据。
完整实现、使用Demo以及benchmark测试请参见源代码:https://github.com/sampsonye/nice
基于.NET Standard的分布式自增ID算法--美团点评LeafSegment的更多相关文章
- 基于.NET Standard的分布式自增ID算法--Snowflake
概述 本篇文章主要讲述分布式ID生成算法中最出名的Snowflake算法.搞.NET开发的,数据库主键最常见的就是int类型的自增主键和GUID类型的uniqueidentifier. 那么为何还要引 ...
- 基于.NET Standard的分布式自增ID算法--Snowflake代码实现
概述 上篇文章介绍了3种常见的Id生成算法,本篇主要介绍如何使用C#实现Snowflake. 基础字段 /// <summary> /// 工作节点Id(长度为5位) /// </s ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- Twitter分布式自增ID算法snowflake原理解析
以JAVA为例 Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个 ...
- Twitter分布式自增ID算法snowflake原理解析(Long类型)
Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个Long类型的6 ...
- 分布式自增ID算法-Snowflake详解
1.Snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并 ...
- Twitter的分布式自增ID算法snowflake
snowflake 分布式场景下获取自增id git:https://github.com/twitter/snowflake 解读: http://www.cnblogs.com/relucent/ ...
- 一秒可生成500万ID的分布式自增ID算法—雪花算法 (Snowflake,Delphi 版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
- Twitter的分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
随机推荐
- pt-osc原理、限制、及与原生online-ddl比较
1. pt-osc工作过程 创建一个和要执行 alter 操作的表一样的新的空表结构(是alter之前的结构) 在新表执行alter table 语句(速度应该很快) 在原表中创建触发器3个触发器分别 ...
- 清空数据库错误:因为该表正由 FOREIGN KEY 约束引用 解决办法
如下解决了五个问题 1. 清空数据 2. 有外键也可以, 因为是逆向删除, 从最后一张表删除. 且使用的是delete, 因为truncate不能对有外键的表 3. 种子问题, 如果表存在种子重设为0 ...
- Servlet_Struts2
百度云链接:https://pan.baidu.com/s/1TNkQ8KN2t1xJFcf_CnTXDQ 密码:i3w8 修改中...
- chmod chown llinux文件及目录的权限介绍
linux 文件或目录的读.写.执行权限说明: chmod :设置文件或目录权限. u:所有者 g:所在组 o:其他组 a:所有人(u.g.o的总和) chmod -R 文件1/文件2….. ...
- spring mvc 接收 put参数
web.xml中: <!-- 用户put提交参数 --> <filter> <filter-name>HttpMethodFilter</filter-nam ...
- 在servlet中用spring @Autowire注入Bean
在servlet中新增init方法: public void init(ServletConfig config) { super.init(config); SpringBeanAutowiring ...
- ArcGIS Earth1.9最新版安装和使用教程
1.下载ArcGIS Earth 官网下载地址:https://www.esri.com/en-us/arcgis/products/arcgis-earth 在这个网页的最下面填上信息,就可以下载了 ...
- 1.Redis安装(Linux环境)
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.Redis安装 使用的最新版本为 3.2.9,下载并安装: wget http://download.re ...
- Redis系列二:reids介绍
一.什么是redis.redis有哪些特性.redis有哪些应用场景.redis的版本 1. 什么是redis redis是一种基于键值对(key-value)数据库,其中value可以为string ...
- HTML5调用百度地图API获取当前位置并直接导航目的地的方法
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <meta charset="UTF-8&quo ...