Hadoop组成架构
Hadoop是apache用来“处理海量数据存储和海量数据分析”的分布式系统基础架构,更广义的是指hadoop生态圈。
Hadoop的优势
高可靠性:hadoop底层维护多个数据副本,即使某个计算单元故障,也不会导致数据丢失。
高扩展性:天然支持分布式,可方便的扩展至几千个节点。
高容错性:能够自动将失败的任务重新分配。
高效性:在mapReduce的思想下,hadoop是并行工作处理任务的。
Hadoop1.x和Hadoop2.x的区别

MapReduce架构概述
Mapreduce实际上就是将计算过程分类两个阶段:map和reduce
1)map阶段:并行处理计算数据
2)reduce阶段:对map结果进行汇总
HDFS架构概述
1. Name Node(nn) 就像一本书的目录。存储文件的元数据:如文件名,文件目录结构,文件属性(创建时间、副本数、文件权限),以及每个文件的块列表和块所在的dataNode等。
2. Data Node(dn) 就像一本书的详细类容。在本地文件系统存储文件块数据,以及数据的校验。
3. Seconddary Name Node(2nn) 2NN并非是NameNode热备,他的作用是,辅助namenode工作,定期合并镜像文件和编辑日志,紧急情况下恢复NameNode。个人理解就是,2nn帮助namenode完成edits向fsimage的合并工作。
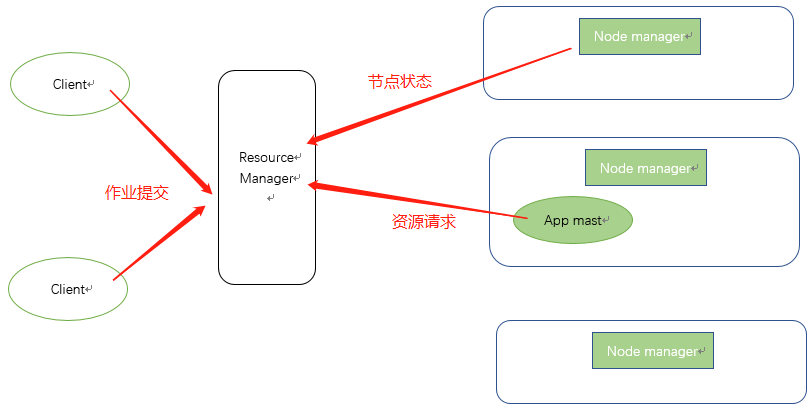
YARN架构概述
Yarn是管理内存调度和cpu资源分配的。
*NodeManager(NM):常驻进程,类似于团队里面的码农,主要作用如下:
1)管理单个节点的资源。(看禅道,完成自己每天的工作安排)
2)处理来自ResourceManager的命令。(完成技术经理分配的任务)
3)处理来自ApplicationMaster的命令。(完成项目组长分配的任务)
*ApplicationMaster(AM):是ResourceManager临时启用的一个节点,不是常驻进程,类似于一个技术小组长:
1)负责数据的切分,任务的监控与容错。(管理组内同事工作)
2)为应用程序申请资源分配给内部任务。(向领导为小组申请资源:人力、时间什么的)
*ResourceManager(RM) :常驻进程,一个集群只有一个,用来管理集群调度情况的,就像一个部门的技术经理一样,其作用如下:
1)处理客户端请求,进行资源分配与调度。(对接产品需求,分给手下的人)
2)监控nodeManager(管理团队成员每天的工作)
3)启动或监控applicationMaster(可能项目太小不想亲自动手,临时任命一个小组长)
*Container:非常驻进程,它是yarn中的资源抽象,他封装了某个节点上的多维度资源,入内存,CPU,磁盘网络等。Am就运行在这里面,Nm通过打开关闭Container开完成资源的调度。
Hadoop组成架构的更多相关文章
- Hadoop体系架构简介
今天跟一个朋友在讨论hadoop体系架构,从当下流行的Hadoop+HDFS+MapReduce+Hbase+Pig+Hive+Spark+Storm开始一直讲到HDFS的底层实现,MapReduce ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- 【Hadoop离线基础总结】Hadoop的架构模型
Hadoop的架构模型 1.x的版本架构模型介绍 架构图 HDFS分布式文件存储系统(典型的主从架构) NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用 ...
- Hadoop HDFS 架构设计
HDFS 简介 Hadoop Distributed File System,简称HDFS,是一个分布式文件系统. HDFS是高容错性的,可以部署在低成本的硬件之上,HDFS提供高吞吐量地对应用程序数 ...
- Hadoop系统架构
一.Hadoop系统架构图 Hadoop1.0与hadoop2.0架构对比图 YARN架构: ResourceManager –处理客户端请求 –启动/监控ApplicationMaster –监控N ...
- Hadoop 核心架构
Hadoop 由许多元素构成.其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件.HDFS(对于本文)的上一层是Ma ...
- Hadoop YARN架构设计要点
YARN是开源项目Hadoop的一个资源管理系统,最初设计是为了解决Hadoop中MapReduce计算框架中的资源管理问题,但是现在它已经是一个更加通用的资源管理系统,可以把MapReduce计算框 ...
- hadoop分布式系统架构详解
hadoop 简单来说就是用 java写的分布式 ,处理大数据的框架,主要思想是 “分组合并” 思想. 分组:比如 有一个大型数据,那么他就会将这个数据按照算法分成多份,每份存储在 从属主机上,并且在 ...
- hadoop体系架构
1.1 Hadoop 概念:hadoop是一个由Apache基金会所开发的分布式系统基础架构.是根据google发表的GFS(Google File System)论文产生过来的. ...
随机推荐
- HTTP服务器(1)
import socket def service_client(new_socket): """为这个客户端返回数据""" # 1. 接收 ...
- SpringBoot2.X 静态文件配置
Spring Boot 默认会挨个从 META/resources > resources > static > public 里面找是否存在相应的资源,如果有则直接返回. 默认配置 ...
- 尚硅谷Docker---1、docker杂记
尚硅谷Docker---1.docker杂记 一.总结 一句话总结: ~ php用的homestead就相当于docker,javaee一般都是用docker,php也可以用docker ~ dock ...
- HearthBuddy卡牌无法识别
界面上无法识别,提示是 [Unidentified card ID :DAL_010][Unidentified card ID :DAL_415] Unidentified card ID :HER ...
- Docker关键概念阐述
要了解Docker需要对其体系结构中的几个关键概念有所了解,主要包括image.container.service.swarm.stack等. 在介绍这几个概念时,会使用到一个测试环境,这个测试环境是 ...
- Django入门------常见问题
项目启动后仅本机可访问 1.修改 Django项目中的settings.py中的 ALLOWED_HOSTS 的值为 ['*']# 准许那些地址访问,* 表示任意地址ALLOWED_HOSTS = [ ...
- [ASP.NET应用到的时间处理函数]
第一种形式: System.DateTime.Now.ToString("D"); //2017年6月2日 System.DateTime.Now.ToString ...
- Javascript和JQuery获取浏览器窗口各种尺寸
原生JS 窗口尺寸: console.log('window.innerWidth = ' + window.innerWidth + '---window.innerHeight = ' + win ...
- js的window.onscroll事件兼容各大浏览器
为窗口添加滚动条事件其实非常的简单, window.onscroll=function(){}; 注意在获取滚动条距离的时候 谷歌不识别document.documentElement.scrollT ...
- python - linux下 no module named pip
有网络的情况下,linux系统提示无法使用pip命令: 有两种解决方式: 第一种: =============================== 敲命令:python -m ensurepip 得到 ...