经典MapReduce作业和Yarn上MapReduce作业运行机制
一、经典MapReduce的作业运行机制
如下图是经典MapReduce作业的工作原理:
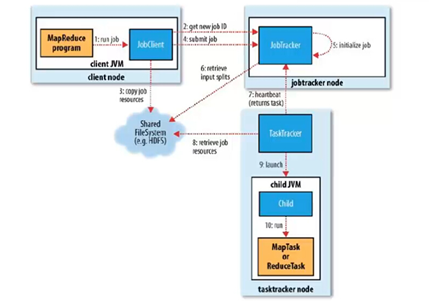
1.1 经典MapReduce作业的实体
经典MapReduce作业运行过程包含的实体:
- 客户端,提交MapReduce作业。
- JobTracker,协调作业的运行。JobTracker是一个Java应用程序,它的主类是JobTracker。
- TaskTracker,运行作业划分后的任务。TaskTracker是Java应用程序,它的主类是TaskTracker。
- 分布式文件系统(一般为HDFS),用来在其他实体间共享作业文件。
1.2 经典MapReduce作业的运行过程
1. 作业提交
- 客户端运行MapReduce作业(步骤1)
- 向JobTracker请求一个新的作业ID,通过调用JobTracker的getNewJobId()方法获取(步骤2)
- 将运行作业所需的资源(包括作业JAR文件、配置文件和计算所得的输入分片)复制到一个以ID命名的JobTracker的文件系统中(步骤3)
- 告知JobTracker作业准备执行,通过调用JobTracker的submitJob()方法实现(步骤4)
2. 作业初始化
- JobTracker收到对其submitJob()方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其进行初始化(步骤5)。初始化包括创建一个表示正在运行作业的对象,用于封装任务和记录信息,以便跟踪任务的状态和进程。
- 作业调度器从共享文件系统中获取客户端已经计算好的输入分片(步骤6)。为每个分片创建一个map任务,创建的reduce任务由Job的mapred.reduce.tasks属性决定,以及新建作业创建和作业清理的任务。
3. 任务分配
- TaskTracker定期向JobTracker发生“心跳(heartbeat)”,表名TaskTracker是否存活,同时保持两者之间的通信(步骤7)
- JobTracker为TaskTracker分配任务,对于map任务,jobtracker会考虑tasktracker的网络位置,选取一个距离其输入分片文件最近的tasktracker,对于reduce任务,jobtracker会从reduce任务列表中选取下一个来执行。
4. 任务执行
- 从HDFS中把作业的JAR文件复制到TaskTracker所在的文件系统,实现JAR文件本地化,同时,TaskTracker将应用程序所需的全部文件从分布式缓存复制到本地磁盘(步骤8),并且为任务新建一个本地工作目录,把JAR文件中的内容解压到这个文件夹下,然后新建一个TaskRunner实例运行该任务。
5. 进度和状态更新
- 任务在运行时,对其进度(progress,即任务完成百分比)的保持跟踪。
6. 作业完成
- 将作业的状态设置为“成功”,并且清空JobTracker作业的工作状态,也指示TaskTracker清空作业的工作状态(如删除中间输出)。
二、Yarn上MapReduce作业运行机制
如图为Yarn中MapReduce作业的工作原理:

2.1 Yarn上的MapReduce作业的实体
主要包括以下几个实体:
- 提交MapReduce作业的客户端
- ResourceManager,Yarn资源管理器,负责协调集群上计算资源的分配
- NodeManager,Yarn节点管理器,负责启动和监视集群中机器上的计算容器(container)
- MRAPPMaster,MapReduce应用程序MRAppMaster负责协调运行MapReduce作业的任务。它和MapReduce任务在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理
- 分布式文件系统,一般为HDFS,用来与其他实体间共享作业文件
2.2 Yarn中MapReduce作业的运行过程
1. 作业提交
- 客户端运行MapReduce作业(步骤1)
- 客户端向ResourceManager请求新的作业ID,ResourceManager收到请求后,返回一个ApplicationID(步骤2)
- 客户端检查作业的的输出说明,计算输入分片,并将作业运行所需的资源(包括作业jar文件、配置文件和分片信息)复制到HDFS(步骤3)
- 告知ResourceManager作业准备执行,并调用ResourceManager上的submitApplication( )方法提交作业(步骤4)
2. 作业初始化
- 资源管理器收到应用提交请求后,便将请求传递给调度器Scheduler,调度器分配一个容器,然后ResourceManager在NodeManager的管理下在容器中启动应用程序的master进程(步骤5(a)和5(b))
- 对作业进行初始化,创建对象以保持对作业进度的跟踪(步骤6)
- MRAppMaster接受来自共享文件系统HDFS的在客户端计算的输入分片(步骤7)
3. 任务分配
- MRAppMaster为作业中的所有map任务和reduce任务向ResourceManager请求容器(步骤8)
4. 任务执行
- 一旦ResourceManager的调度器为任务分配了容器,MRAppMaster就通过与NodeManager通信来启动容器(步骤9(a)和9(b))
- 任务在运行之前,需要将任务所需的资源本地化,包括作业的配置、JAR文件和所有来自分布式缓存的文件(步骤10)
- 运行map任务或reduce任务(步骤11)
5. 进度和状态更新
- 任务每三秒钟通过umbilical接口向ApplicationMaster汇报自己的进度和状态(包含计数器),方便ApplicationMaster随时掌握各个任务的运行状态。
6. 作业完成
- 作业完成后,ApplicationMaster和任务容器清理其工作状态,ApplicationMaster向ResourceManager注销并关闭自己。
【参考链接】
[1] Asu_PC, MR1和MR2的工作原理.
[2] Tom Wbite, 《Hadoop权威指南》
经典MapReduce作业和Yarn上MapReduce作业运行机制的更多相关文章
- MapReduce框架在Yarn上的具体解释
MapReduce任务解析 在YARN上一个MapReduce任务叫做一个Job. 一个Job的主程序在MapReduce框架上实现的应用名称叫MRAppMaster. MapReduce任务的Tim ...
- 第2节 mapreduce深入学习:11、maptask运行机制(多看几遍)
mapTask运行机制详解以及mapTask的并行度在mapTask当中,一个文件的切片大小使用默认值是128M,就是跟我们一个block块对应大小一样 MapTask运行的整个过程 背下来1.Tex ...
- 第2节 mapreduce深入学习:12、reducetask运行机制(多看几遍)
ReduceTask的运行的整个过程 背下来1.启动线程到mapTask那里去拷贝数据,拉取属于每一个reducetask自己内部的数据2.数据的合并,拉取过来的数据进行合并,合并的过程,有可能在内存 ...
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)
我们知道,如果想要在Yarn上运行MapReduce作业,仅需实现一个ApplicationMaster组件即可,而MRAppMaster正是MapReduce在Yarn上ApplicationMas ...
- Hadoop学习笔记(四):Yarn和MapReduce
1. 先关闭掉所有的防火墙(master和所有slave) 2. 配置yarn-site.xml文件(配置所有机器,此时没有启动hadoop服务) 3. 启Yarn,输入要命令start-yarn.s ...
- Yarn上运行spark-1.6.0
目录 目录 1 1. 约定 1 2. 安装Scala 1 2.1. 下载 2 2.2. 安装 2 2.3. 设置环境变量 2 3. 安装Spark 2 3.1. 下载 2 3.2. 安装 2 3.3. ...
- 运行在YARN上的MapReduce应用程序(以MapReduce为例)
client作用:提交一个应用程序查看一个应用程序的运行状态(通过application master) 第一步:提交MR程序到ResourceManager,ResourceManager为这个应用 ...
- 大数据技术 - MapReduce 作业的运行机制
前几章我们介绍了 Hadoop 的 MapReduce 和 HDFS 两大组件,内容比较基础,看完后可以写简单的 MR 应用程序,也能够用命令行或 Java API 操作 HDFS.但要对 Hadoo ...
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(二)
本文继<Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)>,接着讲述MapReduce作业在MRAppMaster上处理总流程,继上篇讲到作业初始化之后的作 ...
随机推荐
- ACM-ICPC 2019南昌网络赛F题 Megumi With String
ACM-ICPC 南昌网络赛F题 Megumi With String 题目描述 给一个长度为\(l\)的字符串\(S\),和关于\(x\)的\(k\)次多项式\(G[x]\).当一个字符串\(str ...
- IDEA设置CodeGlance颜色
CodeGlance是IDEA的mini地图插件, 默认情况下, 其颜色和编辑框的颜色基本一致, 而安装CodeGlance就是为了方便滚动框的上下拖拉, 颜色一致的话会将这种CodeGlance比拖 ...
- C#信号量(Semaphore,SemaphoreSlim)
Object->MarshalByRefObject->WaitHandle->Semaphore 1.作用: 多线程环境下,可以控制线程的并发数量来限制对资源的访问 2.举例: S ...
- Windows 刷新系统图标缓存
rem 关闭Windows外壳程序explorer taskkill /f /im explorer.exe rem 清理系统图标缓存数据库 attrib -h -s -r "%userpr ...
- Maven 配置问题 - could not find resource mybatis-config.xml
需要在pom中加入以下代码 <build> <resources> <resource> <directory>src/main/resources&l ...
- WebUI自动化之Java语言讲解
Java学习网站: default是兜底逻辑,以上条件都不符合时,如何处理. break是终止循环,continue是终止本次循环:
- 如何复制word的图文到ueditor中自动上传?
官网地址http://ueditor.baidu.com Git 地址 https://github.com/fex-team/ueditor 参考博客地址 http://blog.ncmem.com ...
- LA 6972 Domination
6972 Domination Edward is the headmaster of Marjar University. He is enthusiastic about chess and of ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句Criteria基本用法
Criteria进行数据查询与HQL和SQL的区别是Criteria完全是面向对象的方式在进行数据查询,将不再看到有sql语句的痕迹,使用Criteria 查询数据包括以下步骤: 1. 通过sessi ...
- 【CF671D】 Roads in Yusland(对偶问题,左偏树)
传送门 洛谷翻译 CodeForces Solution emmm,先引入一个对偶问题的概念 \(max(c^Tx|Ax \leq b)=min(b^Ty|A^Ty \ge c)\) 考虑这个式子的现 ...