4. Scrapy框架
Scrapy 框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求
Scrapy架构图(绿线是数据流向):
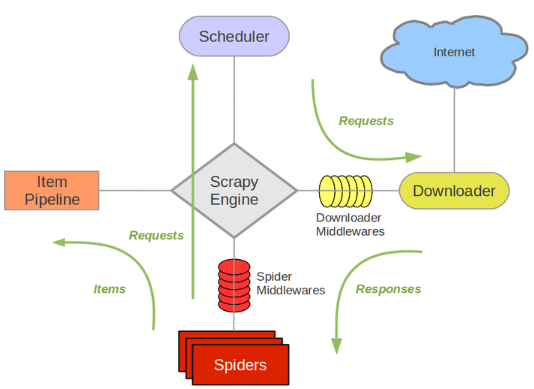
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道文件):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
4. Scrapy框架的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- 知识点整理-mysql的顺序I/O和随机I/O
假设有这样一张表: CREATE TABLE `person_info` ( `id` ) NOT NULL AUTO_INCREMENT, `name` varchar() NOT NULL, `b ...
- 微信小程序 — 自定义picker选择器弹窗内容+textarea穿透bug
微信小程序中定义好的几种picker选择器,不管是日期选择器还是地区选择器,或是其他的都只有定死的样式和内容. 但是大多数开发程序的情况下还是需要自己写样式的,或是内容的. 例如: 代码如下: < ...
- GRU网络
1.GRU(Gated Recurrent Unit) 为了克服RNN无法远距离依赖而提出了LSTM,而GRU是LSTM的一个变体,GRU保持LSTM效果的同时,又使结构变得简单. 2.GRU结构 G ...
- 【计算机视觉】深度相机(八)--OpenNI及与Kinect for windows SDK的比较
OpenNI(开放自然交互)是一个多语言,跨平台的框架,它定义了编写应用程序,并利用其自然交互的API.OpenNI API由一组可用来编写通用自然交互应用的接口组成.OpenNI的主要目的是要形成一 ...
- ffmpeg学习笔记-多线程音视频解码
之前的视频解码仍然存在问题,那就是是在主线程中去完成解码的,会造成线程阻塞,这里将其改为多线程解码,使其主线程不被阻塞 前面介绍了音视频的主线程解码,那样会阻塞主线程,在前面学习了多线程以后,就可以对 ...
- apue-ubuntu环境搭建
目录 apue环境搭建 title: apue环境搭建 date: 2019/11/19 19:25:18 toc: true --- apue环境搭建 下载编译 wget http://www.ap ...
- RxJava基本使用
更多文章请点击链接:http://77blogs.com/?p=162 转载请标明出处:https://www.cnblogs.com/tangZH/p/12088300.html,http://77 ...
- 正确理解使用Vue里的nextTick方法
最近,在项目中要使用Swiper做一个移动端轮播插件.需要先异步动态加载数据后,然后使用v-for渲染节点,再执行插件的滑动轮播行为.解决这个问题,我们通过在组件中使用vm.$nextTick来解决这 ...
- Intellj IDEA快捷键入门 之 Ctrl+Space(空格)
Intellj IDEA快捷键入门 之 Ctrl+Space(空格) 时间:2019/11/28 系统:Win10系统 背景: Win10系统下,想把ctrl+space(空格)切换输入法取消, 以防 ...
- LG P2285 [模板]负环(spfa判负环)
题目描述 寻找一个从顶点1所能到达的负环,负环定义为:一个边权之和为负的环. 输入格式 第一行一个正整数T表示数据组数,对于每组数据: 第一行两个正整数N M,表示图有N个顶点,M条边 接下来M行,每 ...