Java爬虫爬取京东商品信息
以下内容转载于《https://www.cnblogs.com/zhuangbiing/p/9194994.html》,在此仅供学习借鉴只用。
Maven地址
<dependency>
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
网页分析:
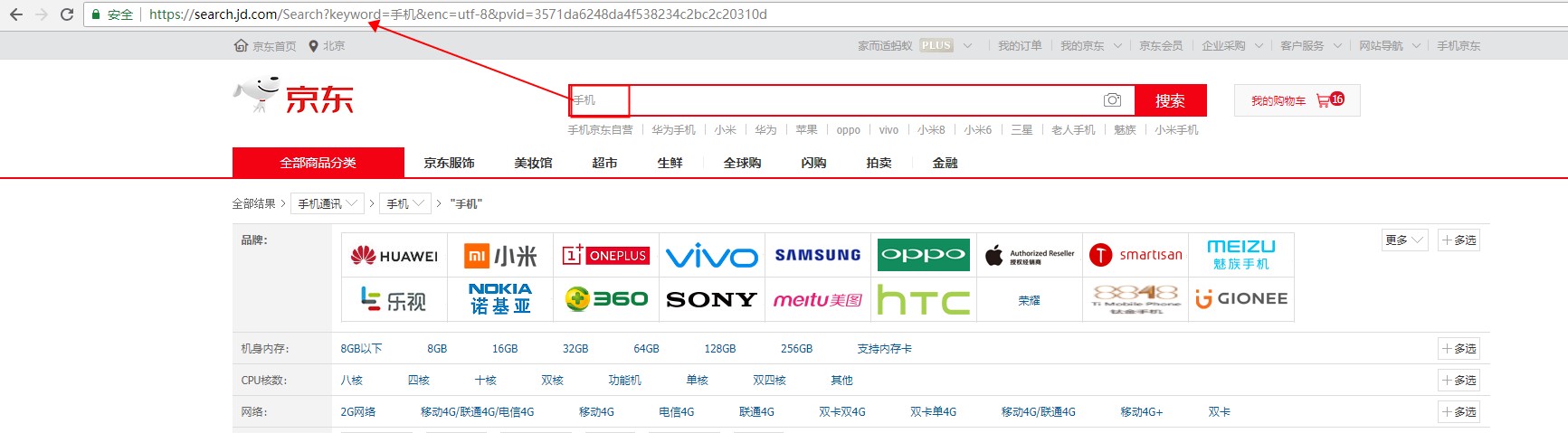
商品布局分析:
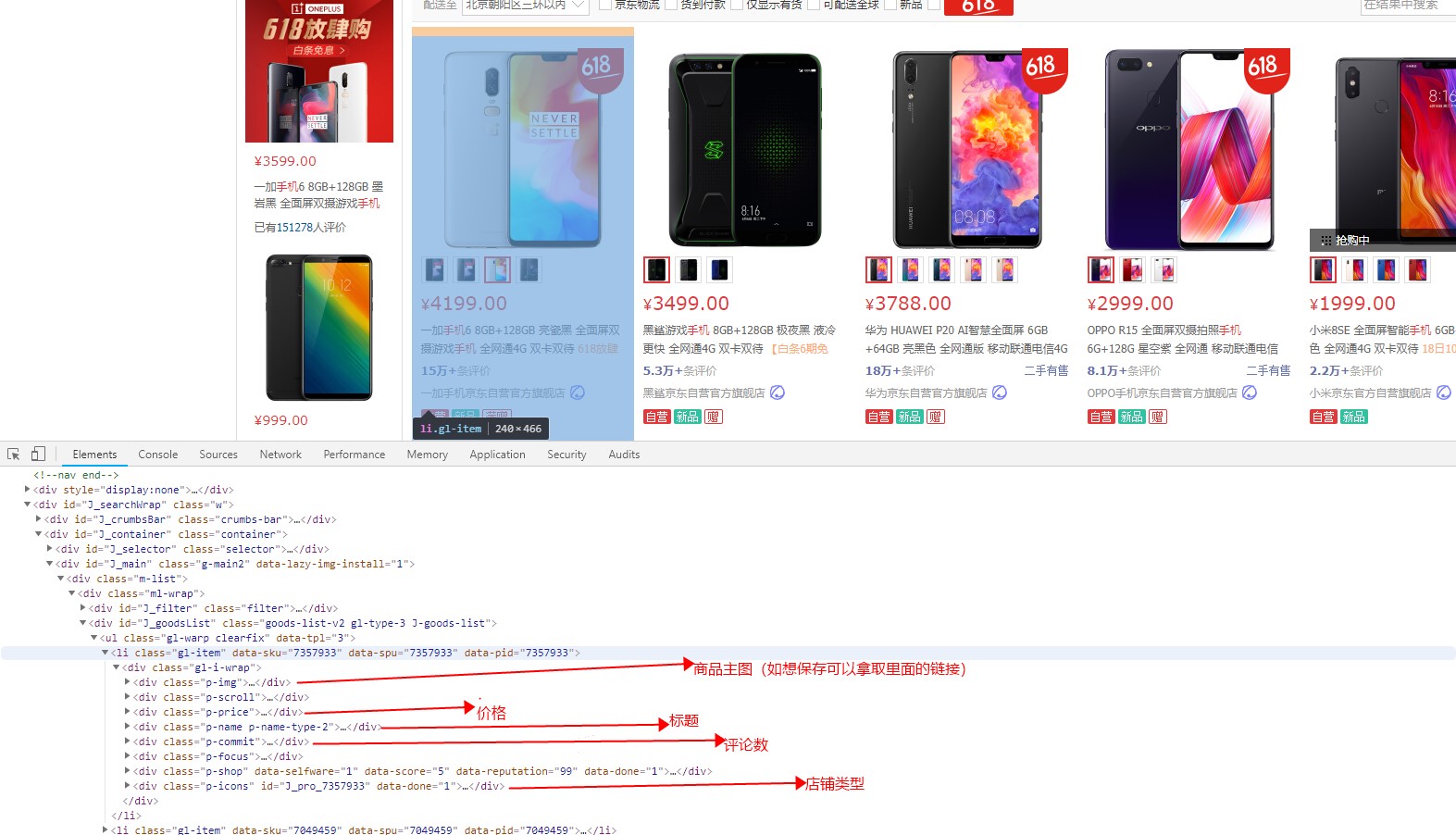
测试代码实例:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; /**
* 作者:小鱼
* 作者唯一QQ号:1132017151
*
* 简单测试类
* 包含内容:京东商品页查询
* 不包含京东商品排除个性化查询和后半部动态加载,如有想要了解,请联系作者
* */
public class Test { public static void main(String[] args) throws Exception {
String url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&psort=3&page=3";//第二页商品
//网址分析
/*keyword:关键词(京东搜索框输入的信息)
* enc:编码方式(可改动:默认UTF-8)
* psort=3 //搜索方式 默认按综合查询 不给psort值
* page=分业(不考虑动态加载时按照基数分业,每一页30条,这里就不演示动态加载)
* 注意:受京东商品个性化影响,准确率无法保障
* */
Document doc = Jsoup.connect(url).maxBodySize(0).get();
//doc获取整个页面的所有数据
Elements ulList = doc.select("ul[class='gl-warp clearfix']");
Elements liList = ulList.select("li[class='gl-item']");
//循环liList的数据
for (Element item : liList) {
//排除广告位置
if (!item.select("span[class='p-promo-flag']").text().trim().equals("广告")) {
//如果向存到数据库和文件里请自行更改
System.out.println(item.select("div[class='p-name p-name-type-2']").select("em").text());//打印商品标题到控制台
}
}
}
}
运行结果:

Java爬虫爬取京东商品信息的更多相关文章
- Python爬虫-爬取京东商品信息-按给定关键词
目的:按给定关键词爬取京东商品信息,并保存至mongodb. 字段:title.url.store.store_url.item_id.price.comments_count.comments 工具 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- 八个commit让你学会爬取京东商品信息
我发现现在不用标题党的套路还真不好吸引人,最近在做相关的事情,从而稍微总结出了一些文字.我一贯的想法吧,虽然才疏学浅,但是还是希望能帮助需要的人.博客园实在不适合这种章回体的文章.这里,我贴出正文的前 ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 正则爬取京东商品信息并打包成.exe可执行程序。
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: import requests import re # 请求头 head ...
- 正则爬取京东商品信息并打包成.exe可执行程序
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
随机推荐
- SVN搭建以及客户端使用
第1章 CentOS下搭建SVN服务器 1.1 SVN简介 SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS.CVS,它采用了分支管理系统,它的设计目标就是取代CVS. ...
- python的索引与切片和元祖
'''索引: 1.索引从0开始 2.末尾元素为 -1 3.能被for循环,有序的数据集合 切片: 1.顾头不顾尾 2.a = "123abcdfg" print(a[0::2]) ...
- golang高并发
golang 为什么能做到高并发 goroutine是go并行的关键,goroutine说到底就是携程,但是他比线程更小,几十个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这 ...
- Mysql 5.6主从同步配置
主从同步,本质是利用数据库日志,将主库数据复制一份到从库,本质上是使用了数据复制技术. 本文概要 主库的基本配置 从库的基本配置 完全同步的步骤 注意事项 工作原理 1. 主库的基本配置 做两件事:启 ...
- POI导出Excel不弹出保存提示_通过ajax异步请求(post)到后台通过POI导出Excel
实现导出excel的思路是:前端通过ajax的post请求,到后台处理数据,然后把流文件响应到客户端,供客户端下载 文件下载方法如下: public static boolean downloadLo ...
- [SC] OpenSCManager 失败 5:拒绝访问
问题:[SC] OpenSCManager 失败 5: 网查这个错误信息指拒绝访问 权限不足 1.解决: 以管理员身份运行cmd,即可 查询这个提示是指什么错误时,看网上有很多文章写用下面这种方法, ...
- Acwing-164-可达性统计(拓扑排序, 位运算统计)
链接: https://www.acwing.com/problem/content/166/ 题意: 给定一张N个点M条边的有向无环图,分别统计从每个点出发能够到达的点的数量. 思路: 先拓扑排序求 ...
- maven的概念-02
1.仓库 仓库分为两类: 1) 本地仓库 ->当前电脑上的maven仓库: 本地仓库的默认目录: ${user.home}/.m2/repository ...
- JavaMail应用--通过javamail API实现在代码中发送邮件功能
JavaMail应用 在日常开发中,可能会引用到发邮件功能,例如在持续集成中,自动化测试运行完毕,自动将测试结果以报表的形式发送邮件给相关人.那么在Java中如何实现发邮件呢? 在java EE ...
- 富文本编辑器粘贴复制Word
tinymce是很优秀的一款富文本编辑器,可以去官网下载.https://www.tiny.cloud 这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用. http ...