【Flink】使用之前,先简单了解一下Flink吧!
Flink简单介绍
概述
在使用Flink之前,我们需要大概知道Flink是什么?
首先,从Flink的官网可以有一个简单的了解:Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
这里了解过大数据的可以看到几个熟悉的词,分布式处理、内存计算,首先分布式处理是大数据集群最常见的,也是必备的处理方式,其次,内存计算也不难让人想到现在很火的Spark,至少通过这个词肯定可以联想到Flink处理任务的速度一定也很快。
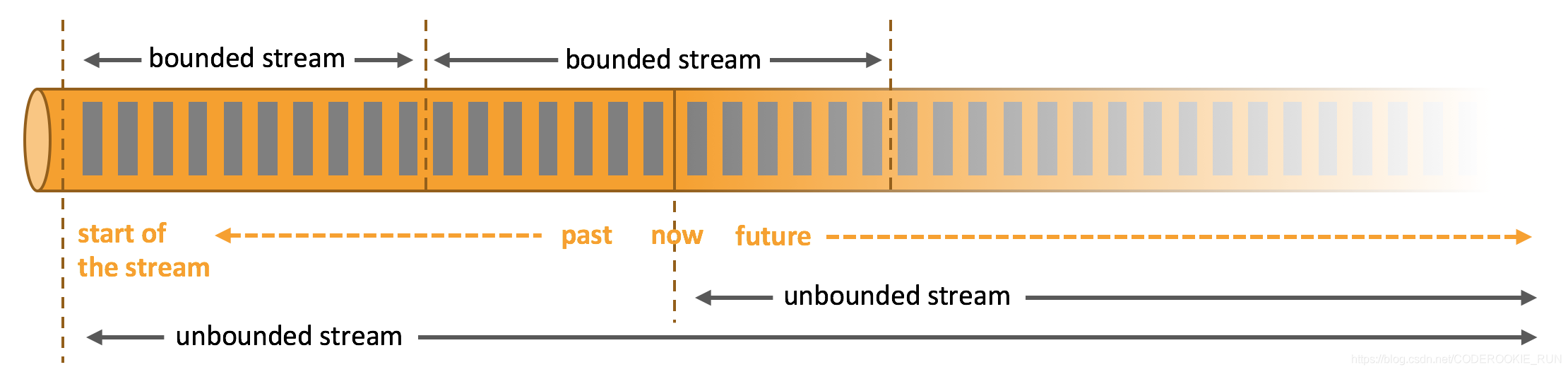
那么,什么是无边界和有边界数据流呢?
无边界数据流和有边界数据流
- 无边界数据流 | Unbounded Stream
官方的定义:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。 - 有边界数据流 | Bounded Stream
官方的定义:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
技术栈核心组成
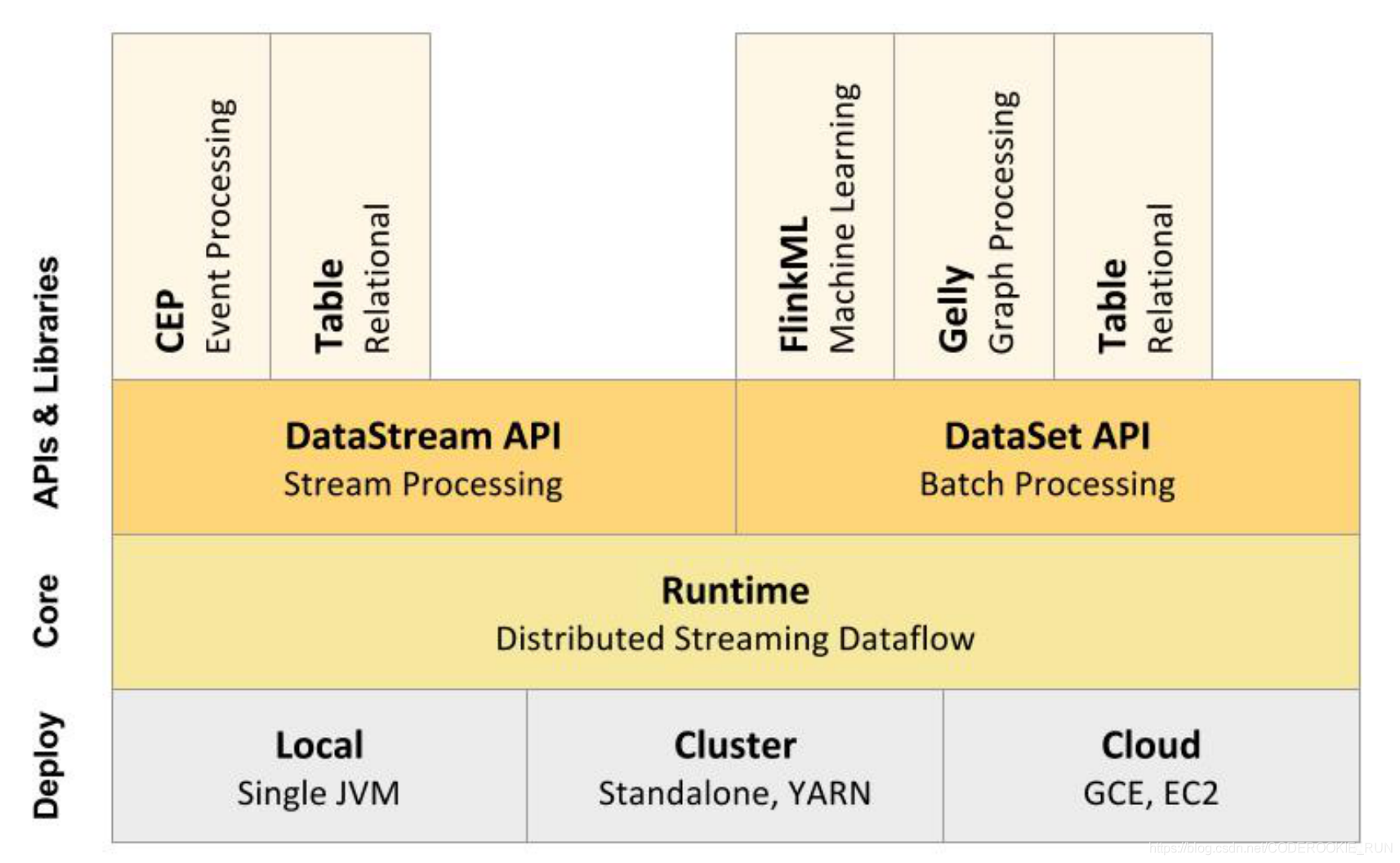
从上图可以看出,底层是Flink的集群部署选择,不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。
核心计算架构是Runtime执行引擎,它是一个分布式系统,能够接 受数据流程序并在一台或多台机器上以容错方式执行。
DataStream API用于流处理,DataSet API用于批处理。
- 流处理特性
1.支持高吞吐、低延迟、高性能的流处理
2.支持带有事件时间的窗口(Window)操作
3.支持有状态计算的 Exactly-once 语义
4.支持高度灵活的窗口(Window)操作,支持基于 time、count、session,以及 data-driven 的窗口操作
5.支持具有 Backpressure 功能的持续流模型
6.支持基于轻量级分布式快照(Snapshot)实现的容错
7.一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
8.Flink 在 JVM 内部实现了自己的内存管理
9.支持迭代计算
10.支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存 - 批处理特性
1.有界、持久、大量
2.适合需要访问全套记录才能完成的计算工作,一般用于离线统计
Flink和Spark有一点最明显的不同,就是 Spark应对批处理和流处理采用了不同的技术框架,批处理由SparkSQL实现,流处理由Spark Streaming实现。Flink则可以做到同时实现批处理和流处理, 它的解决办法就是将批处理(即处理有限的静态数据)视作是一种特殊的流处理。
Flink支持的拓展库涉及机器学习(FlinkML)、复杂事件处理(CEP)、图计算(Gelly) 和分别针对流处理与批处理的 Table API。
架构体系
重要角色
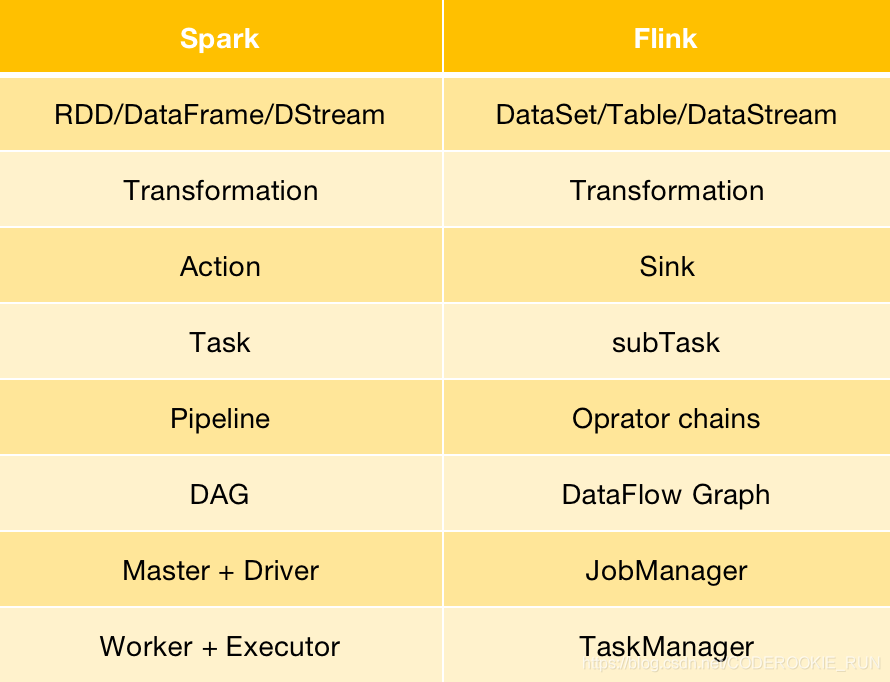
- JobManager
可以认为是Spark中的Master,用于调度task,协调检查点,协调失败时的恢复等。至少要存在一个Master处理器,高可用模式下会存在多个Master,一个是leader,剩下的是standby。 - TaskManager
可以认为是Spark中的Worker,用于执行一个dataflow中的task或者特殊的subtask、数据缓冲和data stream的交换。至少要存在一个Worker处理器。
Flink与Spark架构概念转换
【Flink】使用之前,先简单了解一下Flink吧!的更多相关文章
- Flink on Yarn三部曲之三:提交Flink任务
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 「Flink」使用Java lambda表达式实现Flink WordCount
本篇我们将使用Java语言来实现Flink的单词统计. 代码开发 环境准备 导入Flink 1.9 pom依赖 <dependencies> <dependency> < ...
- Flink数据流图的生成----简单执行计划的生成
Flink的数据流图的生成主要分为简单执行计划-->StreamGraph的生成-->JobGraph的生成-->ExecutionGraph的生成-->物理执行图.其中前三个 ...
- Flink源码阅读(一)——Flink on Yarn的Per-job模式源码简析
一.前言 个人感觉学习Flink其实最不应该错过的博文是Flink社区的博文系列,里面的文章是不会让人失望的.强烈安利:https://ververica.cn/developers-resource ...
- Flink学习之路(一)Flink简介
一.什么是Flink? Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能. 二.Flink特点 1.现有的开源计算方案,会把流处 ...
- Flink整合面向用户的数据流SDKs/API(Flink关于弃用Dataset API的论述)
动机 Flink提供了三种主要的sdk/API来编写程序:Table API/SQL.DataStream API和DataSet API.我们认为这个API太多了,建议弃用DataSet API,而 ...
- Flink应用案例:How Trackunit leverages Flink to process real-time data from industrial IoT devices
January 22, 2019Use Cases, Apache Flink Lasse Nedergaard Recently there has been significant dis ...
- Flink源码学习笔记(3)了解Flink HA功能的实现
使用Flink HA功能维护JobManager中组件的生命周期,可以有效的避免因为JobManager 进程失败导致任务无法恢复的情况. 接下来分享下 Flink HA功能的实现 大纲 基于Zook ...
- flink入门:01 构建简单运行程序
1. mac平台安装flink(默认最新版) brew install apache-flink 安装结果: Version 1.7.1, commit ID: 89eafb4 2. jdk版本,我尝 ...
随机推荐
- 绕过CDN查找真实 IP 姿势总结
返回域名解析对应多个 IP 地址,网站可能部署CDN业务,我们就需要bypass CDN,去查找真正的服务器ip地址 0x01.域名搜集 由于成本问题,可能某些厂商并不会将所有的子域名都部署 CDN, ...
- [一起读源码]走进C#并发队列ConcurrentQueue的内部世界 — .NET Core篇
在上一篇<走进C#并发队列ConcurrentQueue的内部世界>中解析了Framework下的ConcurrentQueue实现原理,经过抛砖引玉,得到了一众大佬的指点,找到了.NET ...
- 带你走进神一样的Elasticsearch索引机制
更多精彩内容请看我的个人博客 前言 相比于大多数人熟悉的MySQL数据库的索引,Elasticsearch的索引机制是完全不同于MySQL的B+Tree结构.索引会被压缩放入内存用于加速搜索过程,这一 ...
- 控件:DataGridView列类型
DataGridView的列的类型提供有多种,包括有: (1)DataGridViewTextBoxColumn(文本列,默认的情况下就是这种) (2)DataGridViewComboBoxColu ...
- Daily Scrum 12/17/2015
Process: Zhaoyang:完成了相册图片的异步加载. Yandong&Dong: 对Azure的体系架构进行学习和相应的编程. Fuchen: 对Oxford计划中的NLP接 ...
- E. Max Gcd
单点时限: 2.0 sec 内存限制: 512 MB 一个数组a,现在你需要删除某一项使得它们的gcd最大,求出这个最大值. 输入格式 第一行输入一个正整数n,表示数组的大小,接下来一行n个数,第i个 ...
- 14. 最长公共前缀----LeetCode
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- python进入adb shell交互模式
import subprocess #方法一:进入某个环境执行语句(adb shell),注意shell内部命令需要带\n,执行完后一定记得执行exit命令退出,否则会阻塞 obj = subproc ...
- git .gitignore不生效
原因是.gitignore只能忽略那些原来没有被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的. 解决方法: 1.先把规则写好,然后把规则对应的文件删了,然后 ...
- zabbix自动监控钉钉报警
钉钉报警 一:设置钉钉机器人 二:zabbix服务器server端配置 1.修改zabbix_server.conf文件 [root@server ~]# vim /usr/local/zabbix ...