ubuntu18.04 基于Hadoop3.1.2集群的Hbase2.0.6集群搭建
前置条件: 之前已经搭好了带有HDFS, MapReduce,Yarn 的 Hadoop 集群
上传tar包并修改配置文件
解压tar包到指定目录
tar -zxvf hbase-2.0.6-bin.tar.hz -C /opt/ronnie
进入配置目录
vim hbase-env.sh 修改 hbase-env.sh文件
# 添加jdk路径
export JAVA_HOME=/usr/lib/jvm/jdk1.8
# 设置不使用自带的Zookeeper
export HBASE_MANAGES_ZK=false
vim hbase-site.xml 修改 hbase-site.xml 文件
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node03:2181,node04:2181,node05:2181</value>
</property>
</configuration>
vim regionservers 设置 regionserver
node01
node02
node03
node04
node05
将 Hadoop 的 core-site.xml 与 hdfs-site.xml 复制到 hbase 的 conf下, 以使hbase能识别nameservice
cp /opt/ronnie/hadoop-3.1.2/etc/hadoop/{core-site.xml,hdfs-site.xml} /opt/ronnie/hbase-2.0.6/conf/
vim backup-masters 创建备用HMaster文件
node02
将Hbase 目录发送到其他虚拟机:
scp -r hbase-2.0.6/ root@node02:`pwd`
scp -r hbase-2.0.6/ root@node03:`pwd`
scp -r hbase-2.0.6/ root@node04:`pwd`
scp -r hbase-2.0.6/ root@node05:`pwd`
vim ~/.bashrc 修改配置文件, 添加:
# Hbase
export HBASE_HOME=/opt/ronnie/hbase-2.0.6
export PATH=$HBASE_HOME/bin:$PATH
source ~/.bashrc 使配置文件生效
启动测试
在node03, node04, node05节点上启动Zookeeper: zkServer.sh start
启动hdfs: start-dfs.sh
启动yarn: start-yarn.sh
启动hbase: start-hbase.sh
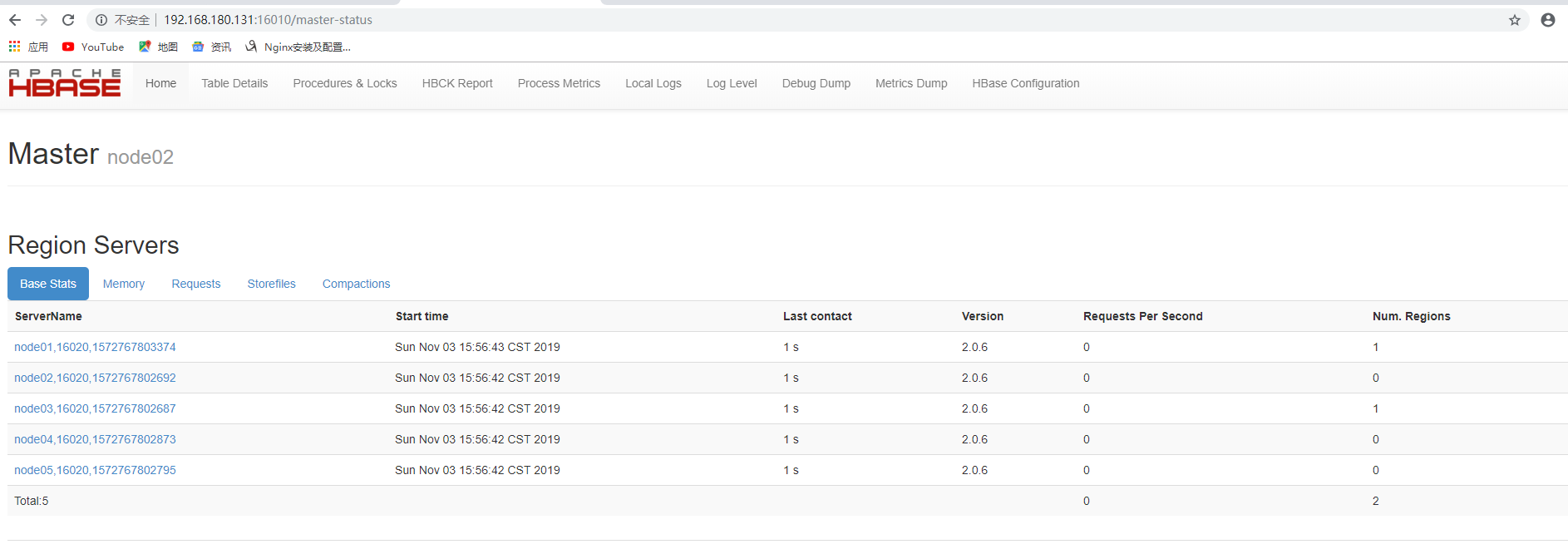
连接主节点的16010端口即可查看UI界面
ubuntu18.04 基于Hadoop3.1.2集群的Hbase2.0.6集群搭建的更多相关文章
- ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建 集群规划: hostname NameNode DataNode JournalNode Re ...
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- 04基于python玩转人工智能最火框架之TensorFlow开发环境搭建
MOOC_VM.vdl.zip 解压之后,得到一个vdl文件.打开virtual box,新建选择类型linuxubuntu 64位. 选择继续,分配2g.使用已有的虚拟硬盘文件,点击选择我们下载的文 ...
- 基于Hadoop3.1.2集群的Hive3.1.2安装(有不少坑)
前置条件: 已经安装好了带有HDFS, MapReduce, Yarn 功能的 Hadoop集群 链接: ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布 ...
- ubuntu18.04 flink-1.9.0 Standalone集群搭建
集群规划 Master JobManager Standby JobManager Task Manager Zookeeper flink01 √ √ flink02 √ √ flink03 √ √ ...
- Ubuntu18.04 LTS 搭建Cassandra集群
环境需求 jdk8 root@node01:~# java -version java version "1.8.0_202" Java(TM) SE Runtime Enviro ...
- 在Ubuntu18.04下配置hadoop集群
服务器准备 启动hadoop最小集群的典型配置是3台服务器, 一台作为Master, NameNode, 两台作为Slave, DataNode. 操作系统使用的Ubuntu18.04 Server, ...
- kubeadm部署1.17.3[基于Ubuntu18.04]
基于 Ubuntu18.04 使用 kubeadm 部署Kubernetes 1.17.3 高可用集群 环境 所有节点初始化 # cat <<EOF>> /etc/hosts ...
- 部署Bookinfo示例程序详细过程和步骤(基于Kubernetes集群+Istio v1.0)
部署Bookinfo示例程序详细过程和步骤(基于Kubernetes集群+Istio v1.0) 部署Bookinfo示例程序 在下载的Istio安装包的samples目录中包含了示例应用程序. ...
随机推荐
- windows下安装redis并部署服务
下载地址: windows版本: https://github.com/MSOpenTech/redis/releases Linux版本: 官网下载: http://www.redis.cn/ gi ...
- Lesson 8 Trading standards
What makes trading between rich countires difficult? Chickens slautered in the United States, claim ...
- No qualifying bean of type 'org.springframework.ui.Model' available
原因:@Autowired 下面没有注入类
- 2_02_MSSQL课程_where查询和like模糊查询
1.where 条件过滤 常见的表达式过滤:比如: select * from 表 where Id>10; 多条件过滤: and or not (优先级:not > and > ...
- sdfsdsf
1 $('.advert-title').each(function(){ 2 var TXTlength = $(this).text().length; // 当前文本的长度 3 if(TXTle ...
- Ajax接收Json数据,调用template模板循环渲染页面的方法
一. 后台接口吐出JSON数据 后台php接口中,需要写三个部分: 1.1 开头header规定数据格式: header("content-type:application/json;cha ...
- 33 第一个只出现一次的字符+ASCII码
题目描述 在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置 思路:使用一个hashmap遍历一遍,统计每个字符出现的次数,然后再统 ...
- 使用 CAS 在 Tomcat 中实现单点登录 http://www.ibm.com/developerworks/cn/opensource/os-cn-cas/
developerWorks 中国 技术主题 Open source 文档库 使用 CAS 在 Tomcat 中实现单点登录 单点登录(Single Sign On , 简称 SSO )是目前比较流行 ...
- docker 日志清理
首先确认 docker 使用的存储引擎 docker info 如果使用 Logging Driver: json-file, 那么日志默认在 /var/lib/docker/contains/xxx ...
- 吴裕雄--天生自然JAVA数据库编程:CallableStatement接口
DELIMITER // DROP PROCEDURE myproc // -- 删除过程 CREATE PROCEDURE myproc(IN p1 int,INOUT p2 int,OUT p3 ...