最小生成树的两种方法(Kruskal算法和Prim算法)
关于图的几个概念定义:
- 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图。
- 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图。
- 连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
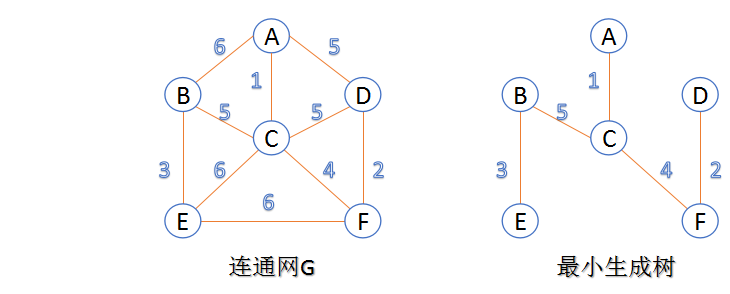
下面介绍两种求最小生成树算法
1.Kruskal算法
此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
- 把图中的所有边按代价从小到大排序;
- 把图中的n个顶点看成独立的n棵树组成的森林;
- 按权值从小到大选择边,所选的边连接的两个顶点ui,viui,vi,应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
- 重复(3),直到所有顶点都在一颗树内或者有n-1条边为止。
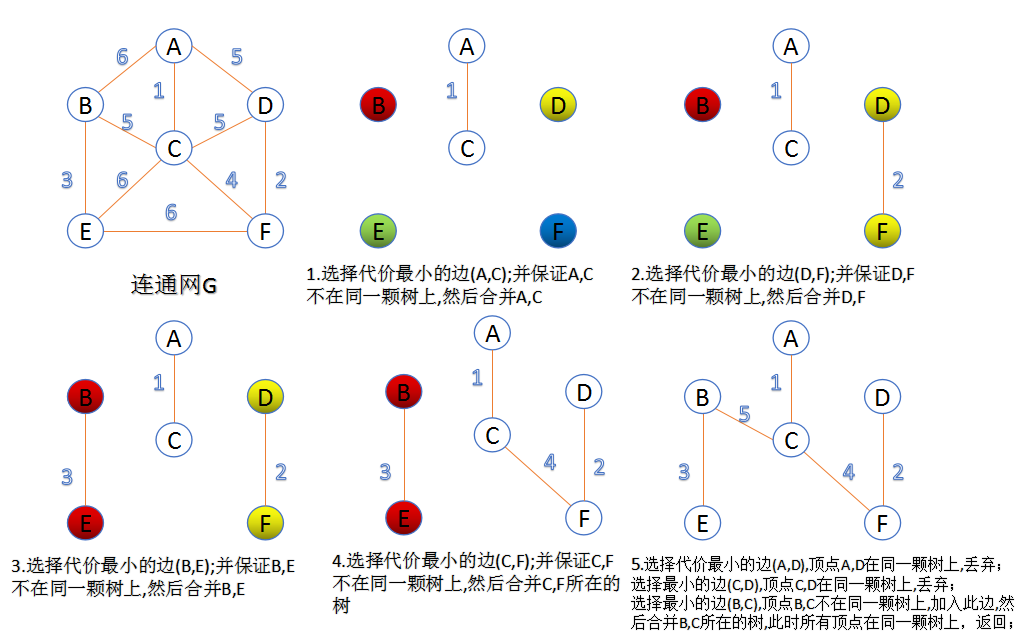
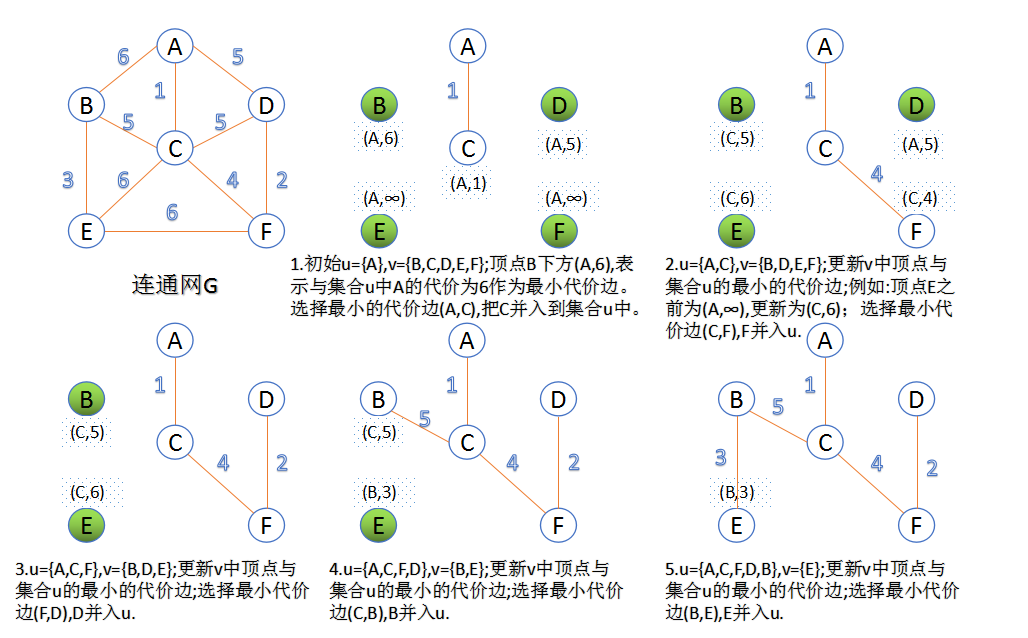
2. Prim算法
此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。
- 图的所有顶点集合为VV;初始令集合u={s},v=V−uu={s},v=V−u;
- 在两个集合u,vu,v能够组成的边中,选择一条代价最小的边(u0,v0)(u0,v0),加入到最小生成树中,并把v0v0并入到集合u中。
- 重复上述步骤,直到最小生成树有n-1条边或者n个顶点为止。
由于不断向集合u中加点,所以最小代价边必须同步更新;需要建立一个辅助数组closedge,用来维护集合v中每个顶点与集合u中最小代价边信息,:
struct
{
char vertexData //表示u中顶点信息
UINT lowestcost //最小代价
}closedge[vexCounts]
3. 完整代码
/************************************************************************
CSDN 勿在浮沙筑高台 http://blog.csdn.net/luoshixian099算法导论--最小生成树(Prim、Kruskal)2016年7月14日
************************************************************************/
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
#define INFINITE 0xFFFFFFFF
#define VertexData unsigned int //顶点数据
#define UINT unsigned int
#define vexCounts 6 //顶点数量
char vextex[] = { 'A', 'B', 'C', 'D', 'E', 'F' };
struct node
{
VertexData data;
unsigned int lowestcost;
}closedge[vexCounts]; //Prim算法中的辅助信息
typedef struct
{
VertexData u;
VertexData v;
unsigned int cost; //边的代价
}Arc; //原始图的边信息
void AdjMatrix(unsigned int adjMat[][vexCounts]) //邻接矩阵表示法
{
for (int i = 0; i < vexCounts; i++) //初始化邻接矩阵
for (int j = 0; j < vexCounts; j++)
{
adjMat[i][j] = INFINITE;
}
adjMat[0][1] = 6; adjMat[0][2] = 1; adjMat[0][3] = 5;
adjMat[1][0] = 6; adjMat[1][2] = 5; adjMat[1][4] = 3;
adjMat[2][0] = 1; adjMat[2][1] = 5; adjMat[2][3] = 5; adjMat[2][4] = 6; adjMat[2][5] = 4;
adjMat[3][0] = 5; adjMat[3][2] = 5; adjMat[3][5] = 2;
adjMat[4][1] = 3; adjMat[4][2] = 6; adjMat[4][5] = 6;
adjMat[5][2] = 4; adjMat[5][3] = 2; adjMat[5][4] = 6;
}
int Minmum(struct node * closedge) //返回最小代价边
{
unsigned int min = INFINITE;
int index = -1;
for (int i = 0; i < vexCounts;i++)
{
if (closedge[i].lowestcost < min && closedge[i].lowestcost !=0)
{
min = closedge[i].lowestcost;
index = i;
}
}
return index;
}
void MiniSpanTree_Prim(unsigned int adjMat[][vexCounts], VertexData s)
{
for (int i = 0; i < vexCounts;i++)
{
closedge[i].lowestcost = INFINITE;
}
closedge[s].data = s; //从顶点s开始
closedge[s].lowestcost = 0;
for (int i = 0; i < vexCounts;i++) //初始化辅助数组
{
if (i != s)
{
closedge[i].data = s;
closedge[i].lowestcost = adjMat[s][i];
}
}
for (int e = 1; e <= vexCounts -1; e++) //n-1条边时退出
{
int k = Minmum(closedge); //选择最小代价边
cout << vextex[closedge[k].data] << "--" << vextex[k] << endl;//加入到最小生成树
closedge[k].lowestcost = 0; //代价置为0
for (int i = 0; i < vexCounts;i++) //更新v中顶点最小代价边信息
{
if ( adjMat[k][i] < closedge[i].lowestcost)
{
closedge[i].data = k;
closedge[i].lowestcost = adjMat[k][i];
}
}
}
}
void ReadArc(unsigned int adjMat[][vexCounts],vector<Arc> &vertexArc) //保存图的边代价信息
{
Arc * temp = NULL;
for (unsigned int i = 0; i < vexCounts;i++)
{
for (unsigned int j = 0; j < i; j++)
{
if (adjMat[i][j]!=INFINITE)
{
temp = new Arc;
temp->u = i;
temp->v = j;
temp->cost = adjMat[i][j];
vertexArc.push_back(*temp);
}
}
}
}
bool compare(Arc A, Arc B)
{
return A.cost < B.cost ? true : false;
}
bool FindTree(VertexData u, VertexData v,vector<vector<VertexData> > &Tree)
{
unsigned int index_u = INFINITE;
unsigned int index_v = INFINITE;
for (unsigned int i = 0; i < Tree.size();i++) //检查u,v分别属于哪颗树
{
if (find(Tree[i].begin(), Tree[i].end(), u) != Tree[i].end())
index_u = i;
if (find(Tree[i].begin(), Tree[i].end(), v) != Tree[i].end())
index_v = i;
}
if (index_u != index_v) //u,v不在一颗树上,合并两颗树
{
for (unsigned int i = 0; i < Tree[index_v].size();i++)
{
Tree[index_u].push_back(Tree[index_v][i]);
}
Tree[index_v].clear();
return true;
}
return false;
}
void MiniSpanTree_Kruskal(unsigned int adjMat[][vexCounts])
{
vector<Arc> vertexArc;
ReadArc(adjMat, vertexArc);//读取边信息
sort(vertexArc.begin(), vertexArc.end(), compare);//边按从小到大排序
vector<vector<VertexData> > Tree(vexCounts); //6棵独立树
for (unsigned int i = 0; i < vexCounts; i++)
{
Tree[i].push_back(i); //初始化6棵独立树的信息
}
for (unsigned int i = 0; i < vertexArc.size(); i++)//依次从小到大取最小代价边
{
VertexData u = vertexArc[i].u;
VertexData v = vertexArc[i].v;
if (FindTree(u, v, Tree))//检查此边的两个顶点是否在一颗树内
{
cout << vextex[u] << "---" << vextex[v] << endl;//把此边加入到最小生成树中
}
}
}
int main()
{
unsigned int adjMat[vexCounts][vexCounts] = { 0 };
AdjMatrix(adjMat); //邻接矩阵
cout << "Prim :" << endl;
MiniSpanTree_Prim(adjMat,0); //Prim算法,从顶点0开始.
cout << "-------------" << endl << "Kruskal:" << endl;
MiniSpanTree_Kruskal(adjMat);//Kruskal算法
return 0;
}
最小生成树的两种方法(Kruskal算法和Prim算法)的更多相关文章
- 最小生成树(次小生成树)(最小生成树不唯一) 模板:Kruskal算法和 Prim算法
Kruskal模板:按照边权排序,开始从最小边生成树 #include<algorithm> #include<stdio.h> #include<string.h> ...
- 求最小生成树——Kruskal算法和Prim算法
给定一个带权值的无向图,要求权值之和最小的生成树,常用的算法有Kruskal算法和Prim算法.这两个算法其实都是贪心思想的使用,但又能求出最优解.(代码借鉴http://blog.csdn.net/ ...
- 最小生成树之Kruskal算法和Prim算法
依据图的深度优先遍历和广度优先遍历,能够用最少的边连接全部的顶点,并且不会形成回路. 这样的连接全部顶点并且路径唯一的树型结构称为生成树或扩展树.实际中.希望产生的生成树的全部边的权值和最小,称之为最 ...
- Algorithm --> Kruskal算法和Prim算法
最小生成树之Kruskal算法和Prim算法 Kruskal多用于稀疏图,prim多用于稠密图. 根据图的深度优先遍历和广度优先遍历,可以用最少的边连接所有的顶点,而且不会形成回路.这种连接所有顶点并 ...
- 最小生成数kruskal算法和prim算法
定义 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图. 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图. 连通网:在 ...
- 贪心算法-最小生成树Kruskal算法和Prim算法
Kruskal算法: 不断地选择未被选中的边中权重最轻且不会形成环的一条. 简单的理解: 不停地循环,每一次都寻找两个顶点,这两个顶点不在同一个真子集里,且边上的权值最小. 把找到的这两个顶点联合起来 ...
- 两种方法实现Python二分查找算法
两种方法实现Python二分查找算法 一. ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 arr=[1,3,6,9,10,20,30] def findnumber( ...
- FIFO调度算法和LRU算法
一.理论 FIFO:先进先出调度算法 LRU:最近最久未使用调度算法 两者都是缓存调度算法,经常用作内存的页面置换算法. 打一个比方,帮助你理解.你有很多的书,比如说10000本.由于你的书实在太多了 ...
- Redis中持久化的两种方法详解
Redis提供了两种不同的持久化方法来将数据存储到硬盘里面.一种方法叫快照(snapshotting),它可以将存在于某一时刻的所有数据都写入硬盘里;另一种方法教只追加文件(append-only f ...
随机推荐
- GCD的常用代码块
一.队列 1.获取全局的并发队列 dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, ...
- springMVC是如何实现参数封装和自动返回Json的
HTTP 请求和响应是基于文本的,意味着浏览器和服务器通过交换原始文本进行通信.但是,使用 Spring,controller 类中的方法返回纯 ‘String’ 类型和域模型(或其他 Java 内建 ...
- C# Stream篇(三) -- TextWriter 和 StreamWriter---转载
C# Stream篇(三) -- TextWriter 和 StreamWriter TextWriter 和 StreamWriter 目录: 为何介绍TextWriter? TextWriter的 ...
- [POI 2014]PTA-Little Bird
Description 题库连接 给你 \(n\) 棵树,第 \(i\) 棵树的高度为 \(d_i\).有一只鸟从 1 号树出发,每次飞跃不能超过 \(k\) 的距离.若飞到下一棵树的高度大于等于这一 ...
- js图片瀑布流效果
要实现图片瀑布流效果,首先得准备几张图片. html的部分比较简单就是将图片加载到浏览器就可以了 代码如下(注意放的图片多一点要不然之后无法滑动鼠标就无法达到瀑布流效果): <!DOCTYPE ...
- smoj2806建筑物
题面 有R红色立方体,G绿色立方体和B蓝色立方体.每个立方体的边长是1.现在有一个N × N的木板,该板被划分成1×1个单元.现在要把所有的R+G+B个立方体都放在木板上.立方体必须放置在单元格内,单 ...
- PyCharm底部控制台console界面开启/取消自动换行
File --> Settings --> Editor --> General --> Console中 勾选右侧第一项Use soft wraps in console(选 ...
- Python学习笔记之正则表达式
本篇在写的时候大量参考了https://deerchao.cn/tutorials/regex/regex.htm的内容 一.什么是正则表达式 在编写处理字符串的程序或网页时,经常会有查找符合某些复杂 ...
- JAVA并发编程之线程安全性
1.一个对象是否是线程安全的,取决于它是否被多个线程访问.想要使得线程安全,需要通过同步机制来协同对对象可变状态的访问. 2.修复多线程访问可变状态变量出现的错误:1.程序间不共享状态变量 2.状态变 ...
- Linux下,Tomcat启动成功,发现ip:8080访问失败
Linux下,Tomcat启动成功,发现ip:8080访问失败 Chasel_H 2018.04.23 20:47* 字数 195 阅读 566评论 0喜欢 3 相信很多人都和我一样,在Linux环境 ...