『Scrapy』终端调用&选择器方法
Scrapy终端
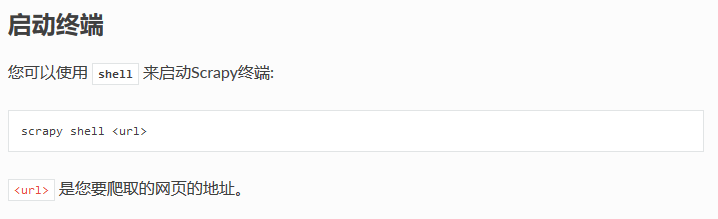
示例,输入如下命令后shell会进入Python(或IPython)交互式界面:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
有一点注意的是必须是双引号,单引号会报错。
之后会显示当前保存的数据结构以供查询,这和我们编写py脚本时的数据结构完全相同,可以直接使用相关方法,
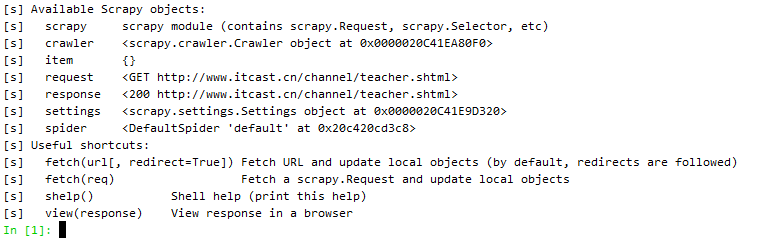
诸如:
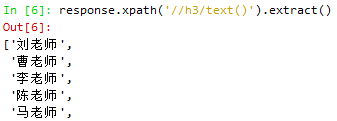
Scrapy Selectors

如下所示,
>>> response.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
>>> response.css('title::text')
[<Selector (text) xpath=//title/text()>]这两种方式提取的都是节点型数据,所以都可以使用.extract()或者.extract_first()方法提取data部分

以下面的源码为例进行提取示范:
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
提取标签属性,
>>> response.xpath('//base/@href').extract()
[u'http://example.com/']
>>> response.css('base::attr(href)').extract()
[u'http://example.com/']对提取目标路径的标签进行筛选,contains(@href, "image")表示href熟悉需要包含image字符,css同理,
response.xpath('//a[contains(@href, "image")]/@href').extract()
Out[1]: ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
response.xpath('//a[contains(@href, "image1")]/@href').extract()
Out[2]: ['image1.html']
response.css('a[href*=image]::attr(href)').extract()
Out[3]: ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
esponse.css('a[href*=image2]::attr(href)').extract()
Out[4]: ['image2.html']结合两者,
>>> response.xpath('//a[contains(@href, "image")]/img/@src').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']
>>> response.css('a[href*=image] img::attr(src)').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']内置了正则表达式re和re_first方法,
response.xpath('//a[contains(@href, "image")]/text()')
Out[8]:
[<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 1 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 2 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 3 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 4 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 5 '>]
response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:\s*(.*)')
Out[7]: ['My image 1 ', 'My image 2 ', 'My image 3 ', 'My image 4 ', 'My image 5 ']
response.xpath('//a[contains(@href, "image")]/text()').re_first(r'Name:\s*(.*)')
Out[9]: 'My image 1 '『Scrapy』终端调用&选择器方法的更多相关文章
- 『GoLang』结构体与方法
结构体 结构体类型 Go 通过结构体的形式支持用户自定义类型,或者叫定制类型. Go 语言结构体是实现自定义类型的一种重要数据类型. 结构体是复合类型(composite types),它由一系列属性 ...
- 『Java』接口的使用方法
以下三个文件存在于同一个包下: 定义接口Dome_Interface.java: package cn.xxmmqg.Interface; // 接口不能直接使用,必须有一个"实现类&quo ...
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- 『Scrapy』爬取腾讯招聘网站
分析爬取对象 初始网址, http://hr.tencent.com/position.php?@start=0&start=0#a (可选)由于含有多页数据,我们可以查看一下这些网址有什么相 ...
- 『Scrapy』全流程爬虫demo
建立好的爬虫工程如下: item.py 它用来存储解析后的响应文件: # -*- coding: utf-8 -*- # Define here the models for your scraped ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
- 『Python』Python 调用 ZoomEye API 批量获取目标网站IP
#### 20160712 更新 原API的访问方式是以 HTTP 的方式访问的,根据官网最新文档,现在已经修改成 HTTPS 方式,测试可以正常使用API了. 0x 00 前言 ZoomEye 的 ...
- 『Python』为什么调用函数会令引用计数+2
一.问题描述 Python中的垃圾回收是以引用计数为主,分代收集为辅,引用计数的缺陷是循环引用的问题.在Python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存. sys.g ...
- 『Java』StringBuilder类使用方法
String类存在的问题 String类的底层是一个被final修饰的byte[],不能改变. 为了解决以上问题,可以使用java.lang.StringBuilder类. StringBuilder ...
随机推荐
- Oracle查询session连接数和inactive以及 概要文件IDLE_TIME限制用户最大空闲连接时间
-----############oracle会话和进程################----------------查询会话总数select count(*) from v$session;--查 ...
- Mysql优化_内置profiling性能分析工具
如果要进行SQL的调优优化和排查,第一步是先让故障重现,但是这个并不是这一分钟有问题,下一秒就OK.一般的企业一般是DBA数据库工程师从监控里找到问题.DBA会告诉我们让我们来排查问题,那么可能很多种 ...
- Docker搭建RabbitMQ集群
Docker搭建RabbitMQ集群 Docker安装 见官网 RabbitMQ镜像下载及配置 见此博文 集群搭建 首先,我们需要启动运行RabbitMQ docker run -d --hostna ...
- SmartOS之以太网精简协议栈TinyIP
做物联网,没有以太网怎么能行!基于Enc28j60,我们团队独立实现了以太网精简协议栈TinyIP,目前支持ARP/ICMP/TCP/UDP/DHCP,还缺一个DNS就完整了.TinyIP内置一个数据 ...
- Hadoop错误日志
1.错误日志:Directory /tmp/hadoop-root/dfs/name is in an inconsistent state: storage directory does not e ...
- Python3基础 str split 用指定的字符将字符串分割
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- Python3基础 getatime getctime getmtime 文件的最近访问 + 属性修改 + 内容修改时间
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- 高通平台启动log概述(PBL log、sbl1 log、kernel log)【转】
本文转自:https://blog.csdn.net/RadianceBlau/article/details/78416776?utm_source=blogxgwz9 高通平台启动log概述(PB ...
- POJ 1222 EXTENDED LIGHTS OUT(高斯消元)题解
题意:5*6的格子,你翻一个地方,那么这个地方和上下左右的格子都会翻面,要求把所有为1的格子翻成0,输出一个5*6的矩阵,把要翻的赋值1,不翻的0,每个格子只翻1次 思路:poj 1222 高斯消元详 ...
- java 插件安装
Emmet插件 : https://www.cnblogs.com/lxjshuju/p/7136420.html 使用方法: 在JSP中使用快捷键 ctrl+e 同其他文件的TAB键