编写爬虫程序的神器 - Groovy + Jsoup + Sublime
写过很多个爬虫小程序了,之前几次主要用C# + Html Agility Pack来完成工作。由于.NET BCL只提供了"底层"的HttpWebRequest和"中层"的WebClient,故对HTTP操作还是需要编写很多代码的。加上编写C#需要使用Visual Studio这个很"重"的工具,开发效率长期以来处于一种低下的状态。
最近项目里面接触到了一种神奇的语言Groovy -- 一种全面兼容Java语言且提供了大量额外语法功能的动态语言。加上网络上有开源的Jsoup项目 -- 一个轻量级的使用CSS选择器来解析HTML内容的类库,这样的组合编写爬虫简直如沐春风。
抓cnblogs首页新闻标题的脚本
Jsoup.connect("http://cnblogs.com").get().select("#post_list > div > div.post_item_body > h3 > a").each {
println it.text()
}
output

抓cnblogs首页新闻详细信息

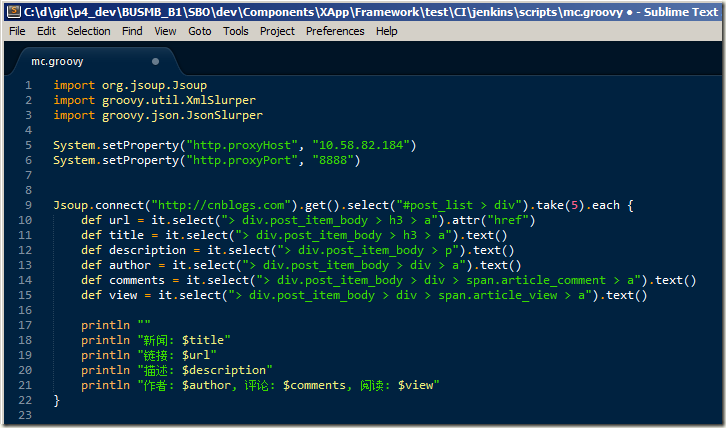
Jsoup.connect("http://cnblogs.com").get().select("#post_list > div").take(5).each {
def url = it.select("> div.post_item_body > h3 > a").attr("href")
def title = it.select("> div.post_item_body > h3 > a").text()
def description = it.select("> div.post_item_body > p").text()
def author = it.select("> div.post_item_body > div > a").text()
def comments = it.select("> div.post_item_body > div > span.article_comment > a").text()
def view = it.select("> div.post_item_body > div > span.article_view > a").text()
println ""
println "新闻: $title"
println "链接: $url"
println "描述: $description"
println "作者: $author, 评论: $comments, 阅读: $view"
}
output

怎么样,很方便是吧。是不是找到一种编写前端JavaScript和jQuery代码的感觉,那就对了!
这里说一个窍门,编写CSS选择器的时候可以借助Google Chrome浏览器的开发工具,如图:

再来看看Groovy是如何快速处理JSON和XML的。一句话:方便到家。
抓cnblogs的feeds
new XmlSlurper().parse("http://feed.cnblogs.com/blog/sitehome/rss").with { xml ->
def title = xml.title.text()
def subtitle = xml.subtitle.text()
def updated = xml.updated.text()
println "feeds"
println "title -> $title"
println "subtitle -> $subtitle"
println "updated -> $updated"
def entryList = xml.entry.take(3).collect {
def id = it.id.text()
def subject = it.title.text()
def summary = it.summary.text()
def author = it.author.name.text()
def published = it.published.text()
[id, subject, summary, author, published]
}.each {
println ""
println "article -> ${it[1]}"
println it[0]
println "author -> ${it[3]}"
}
}
output

抓msdn订阅的产品分类信息
new JsonSlurper().parse(new URL("http://msdn.microsoft.com/en-us/subscriptions/json/GetProductCategories?brand=MSDN&localeCode=en-us")).with { rs ->
println rs.collect{ it.Name }
}
output

再说一下代码编辑器。本方案由于使用Groovy这门动态语言,故可以选择一种轻量级的文本编辑器,这里要推荐Sublime。其中文翻译是“高大尚”的意思。从这个小小的文本编辑器所表现出来的丰富功能和极佳的用户体验来看,也确实对得起这个名字了。
优点:
- 轻量级(客户端6m)
- 支持各种语言的着色,包括Groovy
- 自定义主题包(颜色表)
- 列编辑
- 快速选择,扩展选择等
缺点:
- 不免费,不开源。好在试用版可以无限制使用,只是保存操作时偶尔弹出对话框
最后,分享一段抓取搜房网二手房信息的快速脚本
http://noria.codeplex.com/SourceControl/latest#miles/soufun/soufun.groovy
抓取整理后效果图

行文至此,希望对爬虫感兴趣的朋友们有所帮助。
网络转载于:http://www.cnblogs.com/stainboy/p/make-crawler-with-groovy-and-jsoup.html
编写爬虫程序的神器 - Groovy + Jsoup + Sublime的更多相关文章
- 编写爬虫程序的神器 - Groovy + Jsoup + Sublime(转)
写过很多个爬虫小程序了,之前几次主要用C# + Html Agility Pack来完成工作.由于.NET FCL只提供了"底层"的HttpWebRequest和"中层& ...
- 自动编写Python程序的神器,Python 之父都发声力挺!
就在不久前,kite——那个能够自己编写python代码的AI,Python 之父 Guido van Rossum 使用之后,也发出了「really love」感叹,向大家墙裂推荐了这一高效工具 ...
- 使用Scrapy编写爬虫程序中遇到的问题及解决方案记录
1.创建与域名不一致的Request时,请求会报错 解决方法:创建时Request时加上参数dont_filter=True 2.当遇到爬取失败(对方反爬检测或网络问题等)时,重试,做法为在解析res ...
- Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来.写这个程序的主要目的是抓取海投网的宣讲会信息(公司.时间.地点)并在移动端显示,这样就可以随时随地的浏览在学 ...
- 为编写网络爬虫程序安装Python3.5
1. 下载Python3.5.1安装包1.1 进入python官网,点击menu->downloads,网址:https://www.python.org/downloads/ 1.2 根据系统 ...
- 【C/C++】用C语言编写爬虫—爬虫程序优化要点
写一个网络爬虫 用C语言来写一个网络爬虫,来获取一个网站上感兴趣的信息,抓取自己需要的一切. #include<cspider/spider.h>/* 自定义的解析函数,d为获取到的h ...
- python爬虫__第一个爬虫程序
前言 机缘巧合,最近在学习机器学习实战, 本来要用python来做实验和开发环境 得到一个需求,要爬取大众点评中的一些商户信息, 于是开启了我的第一个爬虫的编写,里面有好多心酸,主要是第一次. 我的文 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- webmagic学习-使用注解编写爬虫
写在前面: 官方文档:http://webmagic.io/docs/zh/posts/ch5-annotation/README.html WebMagic支持使用独有的注解风格编写一个爬虫,引入w ...
随机推荐
- Phpstorm常用设置
Phpstorm更换主题和字体 1.File -- settings -- Editor -- Colors And Fonts: 2.在右侧窗口中选择Scheme name : 选择一个自己喜欢的主 ...
- c# 继承,多态,new /overrid 区别, 引用父类的方法
好久没碰c#了,偶尔需要制作点小工具.为了一个灵活的架构设计,需要对继承/多态有比较深刻的理解. 不料忘得差不多了,好吧,再来回忆下.直接上代码了,如下: using System; using Sy ...
- Python之property装饰器
参考: http://www.cnblogs.com/lovemo1314/archive/2011/05/03/2035600.html http://joy2everyone.iteye.com/ ...
- 【转】Oracle数据库中Sequence的用法
在Oracle数据库中,sequence等同于序列号,每次取的时候sequence会自动增加,一般会作用于需要按序列号排序的地方. 1.Create Sequence (注释:你需要有CREATE S ...
- poj1185
状态压缩dp #include <cstdio> #include <cstring> #include <cstdlib> #include <iostre ...
- mysql5.6 timestamp
1.timestamp 默认值 CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 在创建新记录和修改现有记录的时候都对这个数据列刷新 CURRENT_TIME ...
- codeforces A. Vasily the Bear and Triangle 解题报告
题目链接:http://codeforces.com/problemset/problem/336/A 好简单的一条数学题,是8月9日的.比赛中没有做出来,今天看,从pupil变成Newbie了,那个 ...
- JS控制DIV隐藏显示
转载自:http://blog.sina.com.cn/s/blog_6c3a67be0100ldbe.html JS控制DIV隐藏显示 一,需求描述: 现在有3个DIV块,3个超链接,需要点击一个链 ...
- osgEarth例子
#include <osgViewer/Viewer>#include <osgViewer/ViewerEventHandlers>#include <osgGA/St ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...