K邻近分类算法
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 28 17:16:19 2018 @author: zhen
"""
from sklearn.model_selection import train_test_split
import mglearn
import matplotlib.pyplot as plt
x, y = mglearn.datasets.make_forge()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0) # 生成训练和测试集数据 from sklearn.neighbors import KNeighborsClassifier
14 clf = KNeighborsClassifier(n_neighbors=3) # 调用K近邻分类算法
15
16 clf.fit(x_train, y_train) # 训练数据 print("Test set predictions:{}".format(clf.predict(x_test))) # 预测 print("Test set accuracy:{:.2f}".format(clf.score(x_test, y_test))) fig, axes = plt.subplots(1, 3, figsize=(10, 3)) # 使用matplotlib画图 for n_neighbors, ax in zip([1, 3, 9], axes):
# fit 方法返回对象本身,所以我们可以将实例化和拟合放在一行代码中
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(x, y)
mglearn.plots.plot_2d_separator(clf, x, fill=True, eps=0.5, ax=ax, alpha=0.4)
mglearn.discrete_scatter(x[:, 0], x[:, 1], y, ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
axes[0].legend(loc=3)
结果:

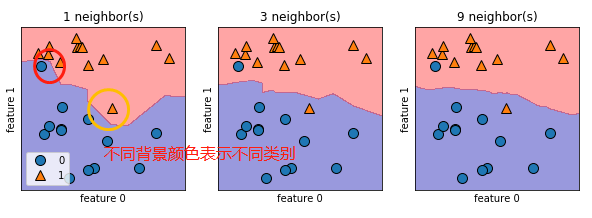
总结:从图中可以看出,使用单一邻居绘制的决策边界紧跟着训练数据,随着邻居的增多,决策边界也越来越平滑,更平滑的边界对应更简单的模型,换句话说,使用更少的邻居对应更高的模型复杂度。
K邻近分类算法的更多相关文章
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 监督学习-KNN最邻近分类算法
分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术建立分类模型,从而对没有分类的数据进行分类的分析方法. 分类问题的应用场景:用于将事物打上一 ...
- KNN邻近分类算法
K邻近(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:计算一个点A与其他所有点之间的距离,取出与该点最近的 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- 查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
代码: # -*- coding: utf-8 -*- """ Created on Thu Jul 12 09:36:49 2018 @author: zhen &qu ...
- K邻近回归算法
代码: # -*- coding: utf-8 -*- """ Created on Fri Jul 13 10:40:22 2018 @author: zhen &qu ...
- sklearn_k邻近分类
# K邻近分类#--------------------------------# coding:utf-8 import pandas as pd from sklearn.neighbors im ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
随机推荐
- Spring Boot自动配置原理、实战
Spring Boot自动配置原理 Spring Boot的自动配置注解是@EnableAutoConfiguration, 从上面的@Import的类可以找到下面自动加载自动配置的映射. org.s ...
- [提权]MS16-016提权EXP
MS16-016提权EXP[K8]Tested On Win7 x86Usage: ms16-016_win7.exe "whoami"by K8拉登哥哥 20160216 下载: ...
- [转]权限系统与RBAC模型概述[绝对经典]
转自:https://blog.csdn.net/yangwenxue_admin/article/details/73936803 0. 前言 一年前,我负责的一个项目中需要权限管理.当时凭着自己的 ...
- python计算数组中对象出现的次数并且按照字典输出
解决的问题如题,如果对Python不是很熟悉,解决的办法可能如下: test_array=[1,2,3,1,2,3]; def count_object1(array): result_obj={} ...
- Linux编程 6 (查看进程 ps 及输出风格)
一.查看进程命令ps 1.1 默认ps 命令 在默认情况下,ps命令只会显示运行在当前控制台下,属于当前用户的进程,在上图中,我们只运行了bash shell以及ps命令本身. 上图中显示了程序的进程 ...
- 从零开始学 Web 之 BOM(四)client系列
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- MongoDB-Oplog详解
MongoDB Oplog 详解 Oplog 概念 Oplog 是用于存储 MongoDB 数据库所有数据的操作记录的(实际只记录增删改和一些系统命令操作,查是不会记录的),有点类似于 mysql 的 ...
- java 访问剪切板(读取与设置)
设置文本到剪切板 public void setIntoClipboard(String data) { Clipboard clipboard = Toolkit.getDefaultToolkit ...
- 3张表实现RBAC
管理员表 CREATE TABLE cqh_admin ( id smallint unsigned not null auto_increment comment 'id', username va ...
- python 浅析模块,包及其相关用法
今天买了一本关于模块的书,说实话,模块真的太多了,小编许多也不知道,要是把模块全讲完,可能得出本书了,所以小编在自己有限的能力范围内在这里浅析一下自己的见解,同时讲讲几个常用的模块. 这里是2018. ...