Horizontal Pod Autoscaler(Pod水平自动伸缩)
Horizontal Pod Autoscaler 根据观察到的CPU利用率(或在支持自定义指标的情况下,根据其他一些应用程序提供的指标)自动伸缩 replication controller, deployment, replica set, stateful set 中的pod数量。注意,Horizontal Pod Autoscaling不适用于无法伸缩的对象,例如DaemonSets。
Horizontal Pod Autoscaler 被实现作为Kubernetes API资源和控制器。该资源决定控制器的行为。控制器会定期调整副本控制器或部署中副本的数量,以使观察到的平均CPU利用率与用户指定的目标相匹配。
1. Horizontal Pod Autoscaler 是如何工作的
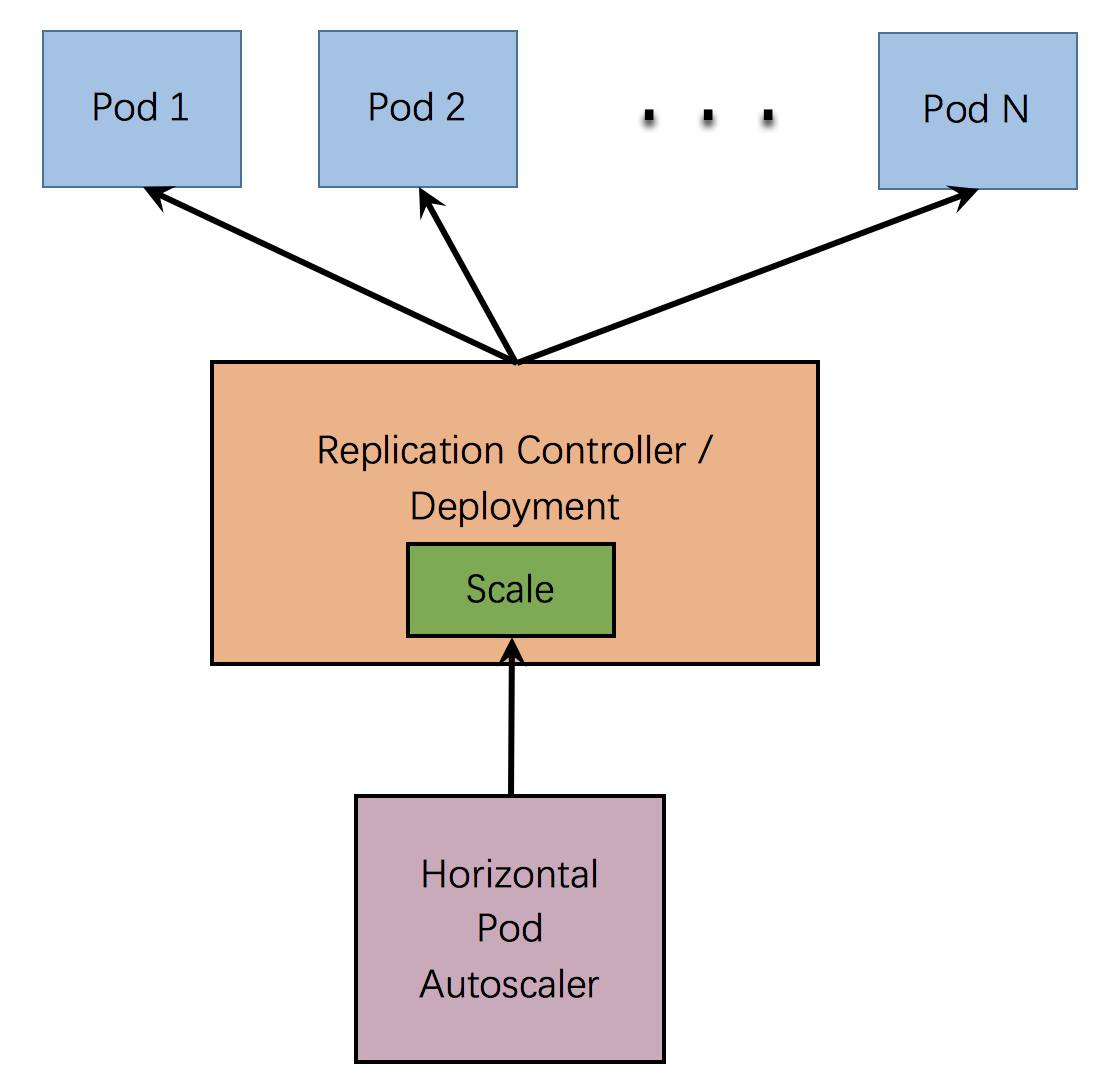
Horizontal Pod Autoscaler 实现为一个控制循环,其周期由--horizontal-pod-autoscaler-sync-period选项指定(默认15秒)。
在每个周期内,controller manager都会根据每个HorizontalPodAutoscaler定义的指定的指标去查询资源利用率。 controller manager从资源指标API(针对每个pod资源指标)或自定义指标API(针对所有其他指标)获取指标。
对于每个Pod资源指标(比如:CPU),控制器会从资源指标API中获取相应的指标。然后,如果设置了目标利用率值,则控制器计算利用率值作为容器上等效的资源请求百分比。如果设置了目标原始值,则直接使用原始指标值。然后,控制器将所有目标容器的利用率或原始值(取决于指定的目标类型)取平均值,并产生一个用于缩放所需副本数量的比率。
如果某些Pod的容器未设置相关资源请求,则不会定义Pod的CPU使用率,并且自动缩放器不会对该指标采取任何措施。
2. 算法细节
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
直译为:(当前指标值 ➗ 期望指标值) ✖️ 当前副本数 ,结果再向上取整,最终结果就是期望的副本数量
例如,假设当前指标值是200m ,期望指标值是100m,期望的副本数量就是双倍。因为,200.0 / 100.0 == 2.0
如果当前值是50m,则根据50.0 / 100.0 == 0.5,那么最终的副本数量就是当前副本数量的一半
如果该比率足够接近1.0,则会跳过伸缩
当targetAverageValue或者targetAverageUtilization被指定的时候,currentMetricValue取HorizontalPodAutoscaler伸缩目标中所有Pod的给定指标的平均值。
所有失败的和标记删除的Pod将被丢弃,即不参与指标计算
当基于CPU利用率来进行伸缩时,如果有尚未准备好的Pod(即它仍在初始化),那么该Pod将被放置到一边,即将被保留。
kubectl 也支持Horizontal Pod Autoscaler
# 查看autoscalers列表
kubectl get hpa
# 查看具体描述
kubectl describe hpa
# 删除autoscaler
kubectl delete hpa # 示例:以下命名将会为副本集foo创建一个autoscaler,并设置目标CPU利用率为80%,副本数在2~5之间
kubectl autoscale rs foo --min= --max= --cpu-percent=
3. 演示
Horizontal Pod Autoscaler automatically scales the number of pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization.
创建Dockerfile,并构建镜像
FROM java:8
COPY ./hello-world-0.0.1-SNAPSHOT.jar hello-world.jar
CMD java -jar hello-world.jar
在hello-world.jar中执行一些CPU密集型计算
运行镜像并暴露为服务
kubectl run hello-world-example \
--image=registry.cn-hangzhou.aliyuncs.com/chengjs/hello-world:2.0 \
--requests='cpu=200m' \
--limits='cpu=500m' \
--expose \
--port= \
--generator=run-pod/v1
创建 Horizontal Pod Autoscaler
HPA将增加和减少副本数量,以将所有Pod的平均CPU利用率维持在50%
kubectl autoscale deployment hello-world-example --cpu-percent= --min= --max=
检查autoscaler的当前状态
kubectl get hpa
增加负载
接下来,利用压测工具持续请求,以增加负载,再查看
kubectl get deployment hello-world-example
通过使用autoscaling/v2beta2版本,你可以定义更多的指标
首先,以autoscaling/v2beta2格式获取HorizontalPodAutoscaler的YAML
kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml
在编辑器中打开/tmp/hpa-v2.yaml文件,接下来对其进行修改
第一个可以替换的指标类型是Pod指标。这些指标在各个容器中平均在一起,并且和目标值进行比较,已确定副本数。例如:
type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
第二个可以替换的指标类型是对象指标。顾名思义,它描述的是Object,而不是Pod。例如:
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
修改后完整的/tmp/hpa-v2.yaml文件如下:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name:hello-world-example
namespace:default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hello-world-example
minReplicas:
maxReplicas:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
status:
observedGeneration:
lastScaleTime: <some-time>
currentReplicas:
desiredReplicas:
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization:
averageValue:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
current:
value: 10k
4. Docs
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
Horizontal Pod Autoscaler(Pod水平自动伸缩)的更多相关文章
- Kubernetes Pod水平自动伸缩(HPA)
HPA简介 HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController.Deployment 和 ReplicaS ...
- kubernetes之Pod水平自动伸缩(HPA)
https://k8smeetup.github.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/ Horizon ...
- 基于Kubernetes的hpa实现pod实例数量的自动伸缩
Pod 是在 Kubernetes 体系中,承载用户业务负载的一种资源.Pod 们运行的好坏,是用户们最为关心的事情.在业务流量高峰时,手动快速扩展 Pod 的实例数量,算是玩转 Kubernetes ...
- kubernetes云平台管理实战:HPA水平自动伸缩(十一)
一.自动伸缩 1.启动 [root@k8s-master ~]# kubectl autoscale deployment nginx-deployment --max=8 --min=2 --cpu ...
- 通过一个实际例子理解Kubernetes里pod的自动scale - 水平自动伸缩
kubectl scale命令用于程序在负载加重或缩小时进行pod扩容或缩小,我们通过一些实际例子来观察scale命令到底能达到什么效果. 命令行创建一个deployment: kubectl run ...
- Kubernetes自动伸缩pod-HPA
在运维中,虽然能预先知道负载何时会飙升,或者如果负载的变化是较长时间内逐渐发生的,手动扩容也是可以接受的,但指望靠人工干预来处理突发而不可预测的流量增长,仍然不够理想. 幸运的是,Kubernetes ...
- [置顶]
Kubernetes1.7新特性:新增自动伸缩条件和参数
一.核心概念 Horizontal Pod Autoscaling,简称HPA,是Kubernetes中实现POD水平自动伸缩的功能.云计算具有水平弹性的特性,这个是云计算区别于传统IT技术架构的主要 ...
- Kubernetes 弹性伸缩HPA功能增强Advanced Horizontal Pod Autoscaler -介绍部署篇
背景 WHAT(做什么) Advanced Horizontal Pod Autoscaler(简称:AHPA)是kubernetes中HPA的功能增强. 在兼容原生HPA功能基础上,增加预测.执行模 ...
- 13.深入k8s:Pod 水平自动扩缩HPA及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 Pod 水平自动扩缩 Pod 水平自动扩缩工作原理 Pod 水平自动 ...
随机推荐
- ORM之炀,打造自已独特的开发框架CRL
ORM一直是长久不衰的话题,各种重复造轮子的过程一直在进行,轮子都一样是圆的,你的又有什么特点呢? CRL这个轮子造了好多年,功能也越来越标准完备,在开发过程中,解决了很多问题,先上一张脑图描述CRL ...
- 【一起学源码-微服务】Nexflix Eureka 源码十二:EurekaServer集群模式源码分析
前言 前情回顾 上一讲看了Eureka 注册中心的自我保护机制,以及里面提到的bug问题. 哈哈 转眼间都2020年了,这个系列的文章从12.17 一直写到现在,也是不容易哈,每天持续不断学习,输出博 ...
- 搭建nginx
Nginx ("engine x") 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器.Nginx是由Igor Sysoev为俄罗斯访问量第二的R ...
- 【php学习】图片处理三步走
前两天要对一张图片进行处理,其实很简单,就是在图片上加上字符串,一个图片而已,但是自己如同得了短暂性失忆似的,图片操作的函数一个都想不起来.所以就抽空整理了一下图片操作函数. 1. 创建画布 从文件中 ...
- ArcGIS Server 动态图层发布调用图解
目录 1 前言 1.1 简介 1.2 适用场景 2 动态图层 2.1 共享地图服务 2.2 动态工作空间添加 2.2.1 企业级数据库 2.2.2 shapefile文件夹 2.2.3 栅格文件夹 2 ...
- 致Java初学者
致Java初学者 精心整理资料点击获取 前言 能看到这篇文章的朋友,应该都或多或少的了解Java,也许你现在是个菜鸟还在成长的路上.再此期间你一定遇到了很多困惑疑虑,对未来的学习方向感到很迷惑.作 ...
- [论文翻译]Practical Diversified Recommendations on YouTube with Determinantal Point Processes
目录 ABSTRACT(摘要) 1 INTRODUCTION(简介) 2 RELATED WORK 2.1 Diversification to Facilitate Exploration(对应多样 ...
- 【开源】后台权限管理系统升级到aspnetcore3.1
*:first-child { margin-top: 0 !important; } .markdown-body>*:last-child { margin-bottom: 0 !impor ...
- 史上最详细的VMware 安装CentOS 7
1.点击"创建新的虚拟机": ![file](https://img2018.cnblogs.com/blog/209997/202001/209997-2020011723572 ...
- MySql数据主从同步配置
由于需要配置MySQL的主从同步配置,现将配置过程记录下,已被以后不时之需 MySql数据主从同步 1.1. 同步介绍 Mysql的 主从同步 是一个异步的复制过程,从一个 Master复制到另一 ...