Spark环境搭建(下)——Spark安装
1. 下载Spark
1.1 官网下载Spark
http://spark.apache.org/downloads.html
打开上述链接,进入到下图,点击红框下载Spark-2.2.0-bin-hadoop2.7.tgz,如下图所示:

2. 安装Spark
Spark安装,分为:
- 准备,包括上传到主节点,解压缩并迁移到/opt/app/目录;
- Spark配置集群,配置/etc/profile、conf/slaves以及confg/spark-env.sh,共3个文件,配置完成需要向集群其他机器节点分发spark程序,
- 直接启动验证,通过jps和宿主机浏览器验证
- 启动spark-shell客户端,通过宿主机浏览器验证
2.1 上传并解压Spark安装包
1. 把spark-2.2.0-bin-hadoop2.7.tgz通过Xftp工具上传到主节点的/opt/uploads目录下
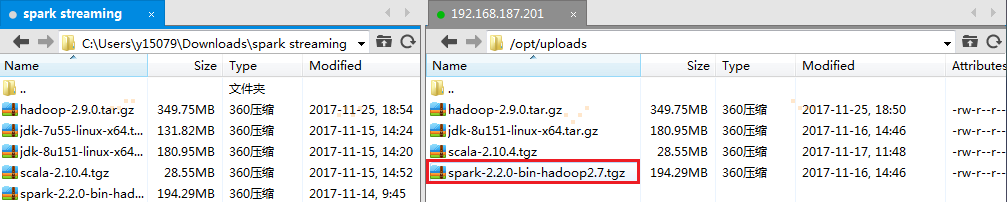
2. 在主节点上解压缩
# cd /opt/uploads/
# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz

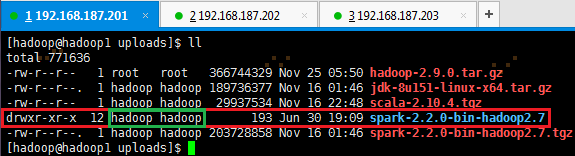
有时解压出来的文件夹,使用命令 ll 查看用户和用户组有可能不是hadoop时,即上图绿框显示,则需要使用如下命令更换为hadoop用户和用户组:
# sudo chown hadoop:hadoop spark-2.2.0-bin-hadoop2.7
3. 把spark-2.2.0-bin-hadoop2.7移到/opt/app/目录下
# mv spark-2.2.0-bin-hadoop2.7 /opt/app/
# cd /opt/app && ll

2.2 配置文件与分发程序
2.2.1 配置/etc/profile
1. 以hadoop用户打开配置文件/etc/profile
# sudo vi /etc/profile

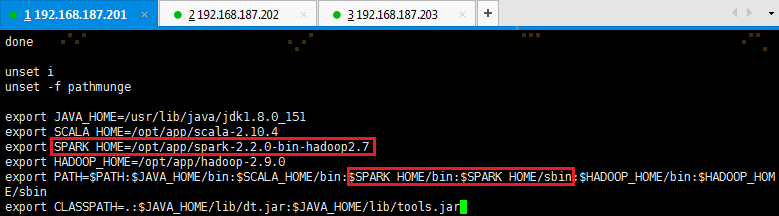
2. 定义SPARK_HOME并把spark路径加入到PATH参数中
export SPARK_HOME=/opt/app/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.2.2 配置conf/slaves
1. 打开配置文件conf/slaves,默认情况下没有slaves,需要使用cp命令复制slaves.template
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/conf 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7目录下,则使用该命令
# cp slaves.template slaves
# sudo vi slaves
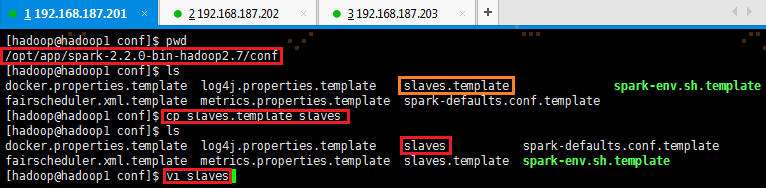
2. 加入slaves配置节点
hadoop1
hadoop2
hadoop3

2.2.3 配置conf/spark-env.sh
1. 以hadoop用户,使用如下命令,打开配置文件spark-env.sh
# cd /opt/app/spark-2.2.0-bin-hadoop2.7 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7目录下,则使用该命令
# cp spark-env.sh.template spark-env.sh
# vi spark-env.sh

2. 加入如下环境配置内容,设置hadoop1为Master节点:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_151
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=900M
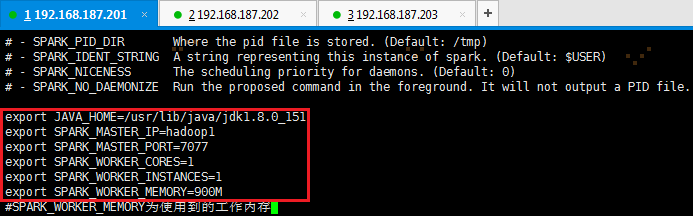
【注意】:SPARK_WORKER_MEMORY为计算时使用的内存,设置的值越低,计算越慢,反之亦然。
2.2.4 向各节点分发Spark程序
1. 进入hadoop1机器/opt/app/目录,使用如下命令把spark文件夹复制到hadoop2和hadoop3机器
# cd /opt/app
# scp -r spark-2.2.0-bin-hadoop2.7 hadoop@hadoop2:/opt/app/
# scp -r spark-2.2.0-bin-hadoop2.7 hadoop@hadoop3:/opt/app/


2. 在从节点查看是否复制成功

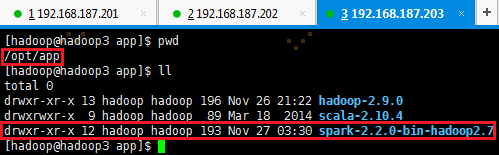
2.3 启动Spark
1. 启动Spark
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/sbin
# ./start-all.sh
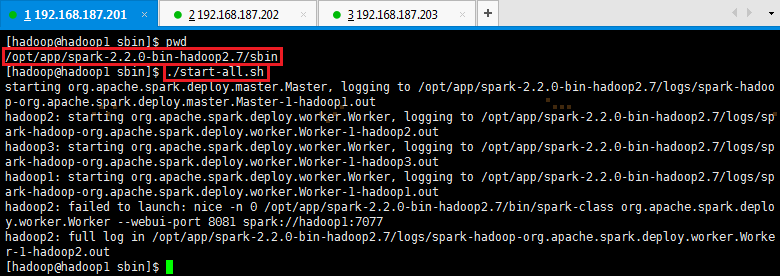
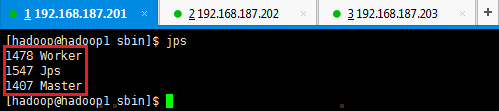
2. 验证启动
此时在hadoop1上面运行的进程有:Worker和Master
此时在hadoop2和hadoop3上面运行的进程有Worker

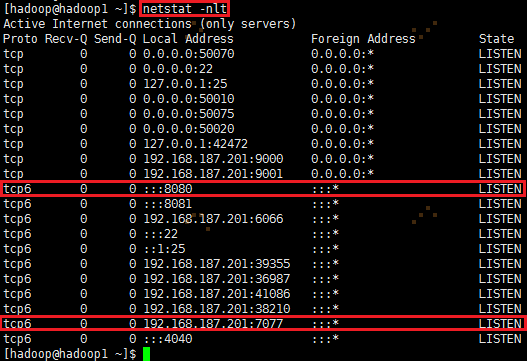
通过netstat -nlt 命令查看hadoop1节点网络情况
在浏览器中输入http://hadoop1:8080,即可以进入Spark集群状态页面(直接访问有问题,看下述步骤)
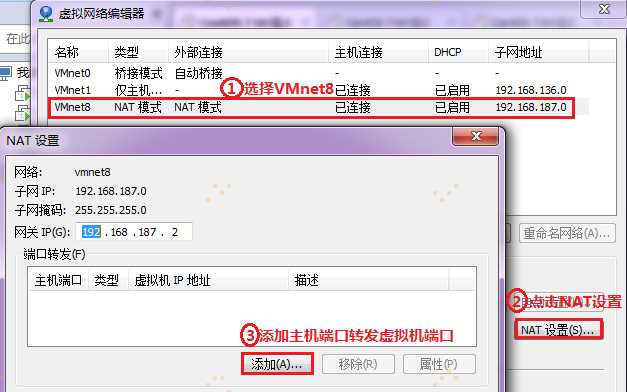
【注意】:在宿主机浏览器上,直接访问(192.168.187.201)hadoop1:8080,会报错。要想通过宿主机浏览器,访问(192.168.187.201)hadoop1:8080,因为VMware网络连接的方式是NAT,需要把宿主机端口与访问的虚拟机端口进行关联配置,通过访问宿主机端口来达到访问虚拟机端口的目的,如图所示:
首先,点击VMware的菜单栏编辑里面的虚拟网络编辑器:
然后,进行下述操作:
接着跳转到映射传入端口窗口,如下:

最后完成,如下。
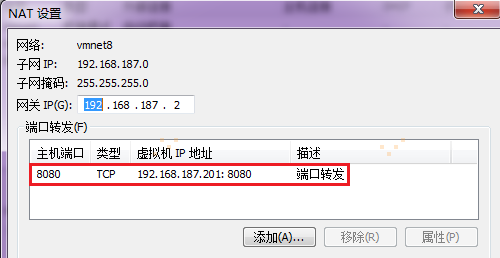
验证,在宿主机浏览器上输入localhost:8080,映射到hadoop1:8080,即可访问Spark集群状态
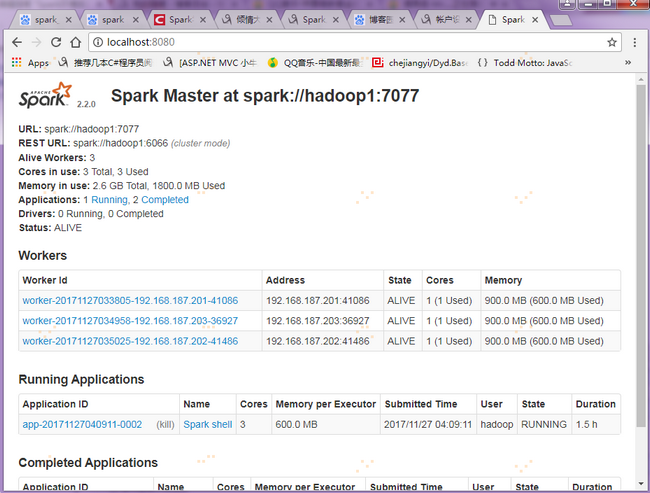
2.4 验证客户端连接
1. 进入hadoop1节点,进入spark的bin目录,使用spark-shell连接集群
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/bin
# spark-shell --master spark://hadoop1:7077 --executor-memory 600m
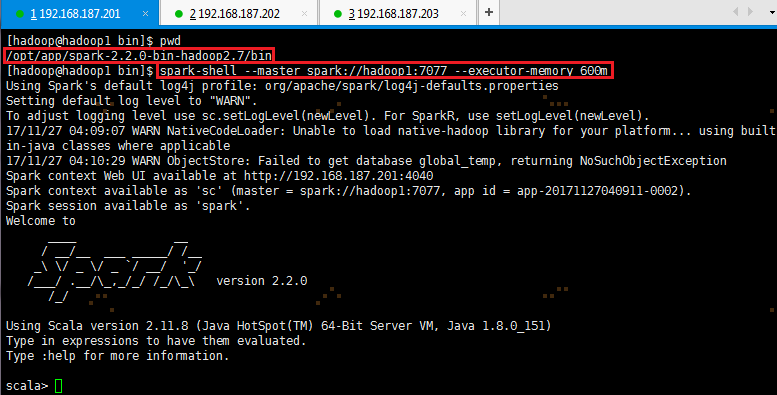
在命令中只指定了内存大小并没有指定核数,所以该客户端将占用该集群所有核并在每个节点分配600M内存
2. 查看Spark集群状态,通过上一步骤【注意】的IP端口映射设置,在宿主机浏览器输入localhost:8080,可以会直接映射到(192.168.187.201)hadoop1:8080上,如图:

3. Spark测试
3.1 使用Spark-shell测试
3.2 使用Spark-submit测试
Spark环境搭建(下)——Spark安装的更多相关文章
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- LNMP环境搭建:Nginx安装、测试与域名配置
Nginx作为一款优秀的Web Server软件同时也是一款优秀的负载均衡或前端反向代理.缓存服务软件 2.编译安装Nginx (1)安装Nginx依赖函数库pcre pcre为“perl兼容正则表达 ...
- Tesseract环境搭建及编译安装
Tesseract环境搭建及编译安装 Tesseract源码都是C++源码:对于不咋会C++的人来说,这真是...虽然说语言有相通性,但是...哎!!!!! 分享出来,也希望对大家有所帮助. 环境:w ...
- Python环境搭建和pycharm安装
Python环境搭建和pycharm安装 本人安装环境为Windows10系统,下载的Python版本为3.4社区版本,可参考 1.下载Python3.4版本 官网:https://www.pytho ...
- LNMP环境搭建之php安装,wordpress博客搭建
LNMP环境搭建之php安装,wordpress博客搭建 一.介绍: 1.什么是CGI CGI全称是"通用网关接口"(Common Gateway Interface),HTTP服 ...
- windows下大数据开发环境搭建(4)——Spark环境搭建
一.所需环境 · Java 8 · Python 2.6+ · Scala · Hadoop 2.7+ 二.Spark下载与解压 http://spark.apache.org/downloads.h ...
- spark在windows下的安装
Windows下最简的开发环境搭建这里的spark开发环境, 不是为apache spark开源项目贡献代码, 而是指基于spark的大数据项目开发. Spark提供了2个交互式shell, 一个 ...
- 学习Spark——环境搭建(Mac版)
大数据情结 还记得上次跳槽期间,与很多猎头都有聊过,其中有一个猎头告诉我,整个IT跳槽都比较频繁,但是相对来说,做大数据的比较"懒"一些,不太愿意动.后来在一篇文中中也证实了这一观 ...
随机推荐
- vue2 vue-rout
vue 2.0的路由比起1.0简单了许多,分为以下几个步骤: 1.创建路由块和视图块: to里面是要切换的路径名称 <div id="app"> <div> ...
- 模板引擎(smarty)知识点总结三
阔别了几个月,小杨又来分享php知识.话不多说,言归正传,今天继续带来smarty的知识点. -----------------smarty assign append 详解 对于这两个的区别和联系 ...
- VS 2017 Web项目需要安装Sql Server 2012 Express LocalDB问题
最近在做mvc5的练习 ,结果到了数据库连接这一阶段就出现了问题,开始我以为<add name="MovieDBContext" connectionString=" ...
- css div 细边框
.item{ max-width:48%; float:left; padding:2px; border-top:1px solid #000; border-left:1px solid #000 ...
- 测试库的接收到的数据是否完整(jrtplib为列)
最近使用jrtplib来接收RTP包,然后解码播放 发现解码出来的是绿屏,马赛克 于是开始排查 首先直接用wireshark抓进来的包,转为可以被vlc播放的文件 操作如下 http://blog.c ...
- 【HTTP协议】
一.简介 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议 ...
- checkbox 全选或取消
Html: 点击label 也能 check <div class="checkbox"> <input class ...
- VMware仅主机模式虚拟机无法ping通物理机
问题描述 在VMware Workstation中新建了一个虚拟机CentOS7,网络适配器选择的是"仅主机模式",结果,物理机ping不通虚拟机,虚拟机也ping不通物理机. 原 ...
- [ERROR] Terminal initialization failed; falling back to unsupported java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
1:出现此种错误应该是jar版本包冲突了,启动hive的时候,由于hive依赖hadoop,启动hive,会将hadoop的配置以及jar包等等导入到hive中,导致jar包版本冲突,下面贴一下错误, ...
- Python 内嵌函数运用(探究模块)
Python库参考 http://python.org/doc/lib 1. 使用dir #查看 函数的所有特性(以及模块的所有函数.类.变量等.) 一些以下划线开始,暗示(约定俗成) ...