Spark环境搭建(下)——Spark安装
1. 下载Spark
1.1 官网下载Spark
http://spark.apache.org/downloads.html
打开上述链接,进入到下图,点击红框下载Spark-2.2.0-bin-hadoop2.7.tgz,如下图所示:

2. 安装Spark
Spark安装,分为:
- 准备,包括上传到主节点,解压缩并迁移到/opt/app/目录;
- Spark配置集群,配置/etc/profile、conf/slaves以及confg/spark-env.sh,共3个文件,配置完成需要向集群其他机器节点分发spark程序,
- 直接启动验证,通过jps和宿主机浏览器验证
- 启动spark-shell客户端,通过宿主机浏览器验证
2.1 上传并解压Spark安装包
1. 把spark-2.2.0-bin-hadoop2.7.tgz通过Xftp工具上传到主节点的/opt/uploads目录下
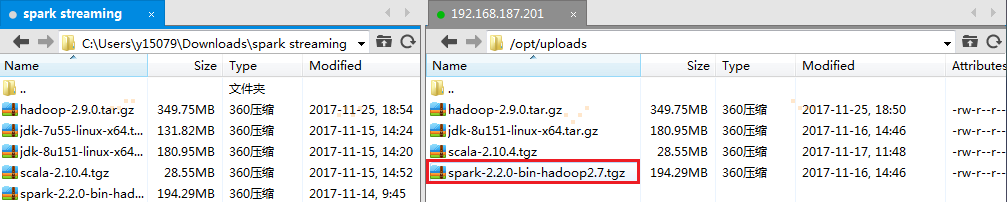
2. 在主节点上解压缩
# cd /opt/uploads/
# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz

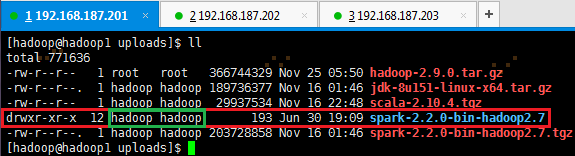
有时解压出来的文件夹,使用命令 ll 查看用户和用户组有可能不是hadoop时,即上图绿框显示,则需要使用如下命令更换为hadoop用户和用户组:
# sudo chown hadoop:hadoop spark-2.2.0-bin-hadoop2.7
3. 把spark-2.2.0-bin-hadoop2.7移到/opt/app/目录下
# mv spark-2.2.0-bin-hadoop2.7 /opt/app/
# cd /opt/app && ll

2.2 配置文件与分发程序
2.2.1 配置/etc/profile
1. 以hadoop用户打开配置文件/etc/profile
# sudo vi /etc/profile

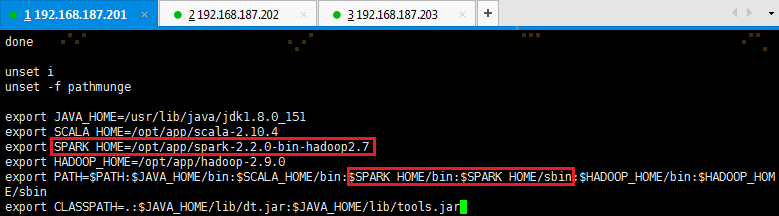
2. 定义SPARK_HOME并把spark路径加入到PATH参数中
export SPARK_HOME=/opt/app/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
2.2.2 配置conf/slaves
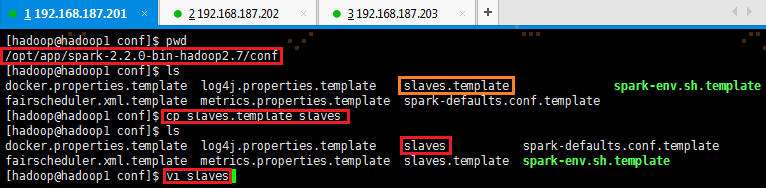
1. 打开配置文件conf/slaves,默认情况下没有slaves,需要使用cp命令复制slaves.template
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/conf 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7目录下,则使用该命令
# cp slaves.template slaves
# sudo vi slaves
2. 加入slaves配置节点
hadoop1
hadoop2
hadoop3

2.2.3 配置conf/spark-env.sh
1. 以hadoop用户,使用如下命令,打开配置文件spark-env.sh
# cd /opt/app/spark-2.2.0-bin-hadoop2.7 如果不在/opt/app/spark-2.2.0-bin-hadoop2.7目录下,则使用该命令
# cp spark-env.sh.template spark-env.sh
# vi spark-env.sh

2. 加入如下环境配置内容,设置hadoop1为Master节点:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_151
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=900M
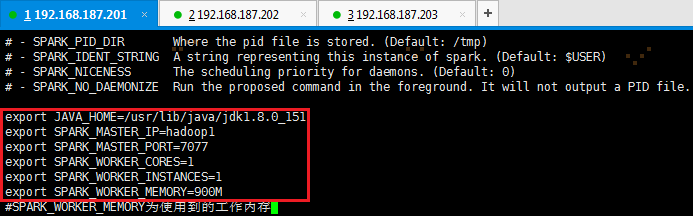
【注意】:SPARK_WORKER_MEMORY为计算时使用的内存,设置的值越低,计算越慢,反之亦然。
2.2.4 向各节点分发Spark程序
1. 进入hadoop1机器/opt/app/目录,使用如下命令把spark文件夹复制到hadoop2和hadoop3机器
# cd /opt/app
# scp -r spark-2.2.0-bin-hadoop2.7 hadoop@hadoop2:/opt/app/
# scp -r spark-2.2.0-bin-hadoop2.7 hadoop@hadoop3:/opt/app/


2. 在从节点查看是否复制成功

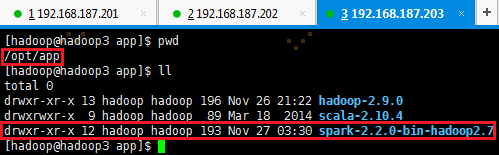
2.3 启动Spark
1. 启动Spark
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/sbin
# ./start-all.sh
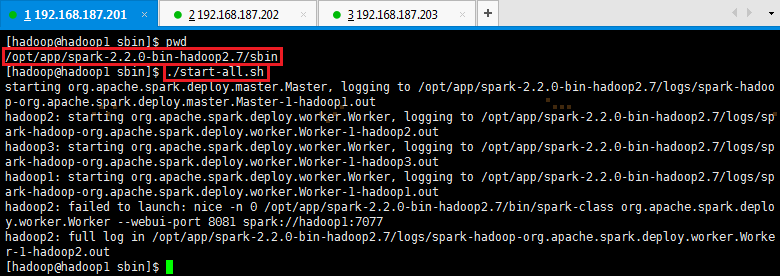
2. 验证启动
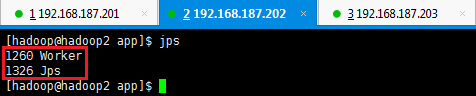
此时在hadoop1上面运行的进程有:Worker和Master
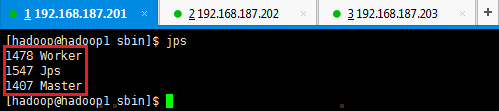
此时在hadoop2和hadoop3上面运行的进程有Worker

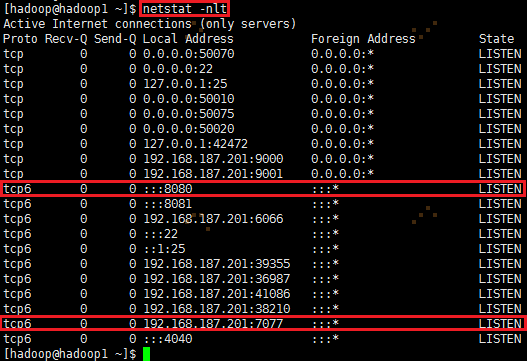
通过netstat -nlt 命令查看hadoop1节点网络情况
在浏览器中输入http://hadoop1:8080,即可以进入Spark集群状态页面(直接访问有问题,看下述步骤)
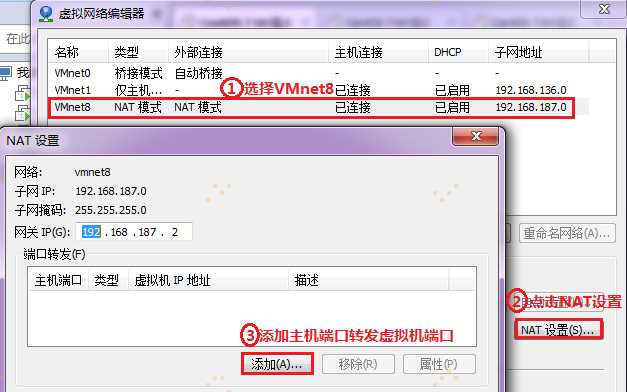
【注意】:在宿主机浏览器上,直接访问(192.168.187.201)hadoop1:8080,会报错。要想通过宿主机浏览器,访问(192.168.187.201)hadoop1:8080,因为VMware网络连接的方式是NAT,需要把宿主机端口与访问的虚拟机端口进行关联配置,通过访问宿主机端口来达到访问虚拟机端口的目的,如图所示:
首先,点击VMware的菜单栏编辑里面的虚拟网络编辑器:
然后,进行下述操作:
接着跳转到映射传入端口窗口,如下:

最后完成,如下。
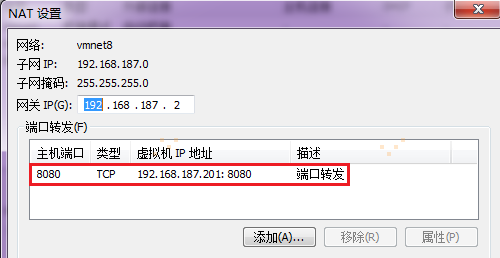
验证,在宿主机浏览器上输入localhost:8080,映射到hadoop1:8080,即可访问Spark集群状态
2.4 验证客户端连接
1. 进入hadoop1节点,进入spark的bin目录,使用spark-shell连接集群
# cd /opt/app/spark-2.2.0-bin-hadoop2.7/bin
# spark-shell --master spark://hadoop1:7077 --executor-memory 600m
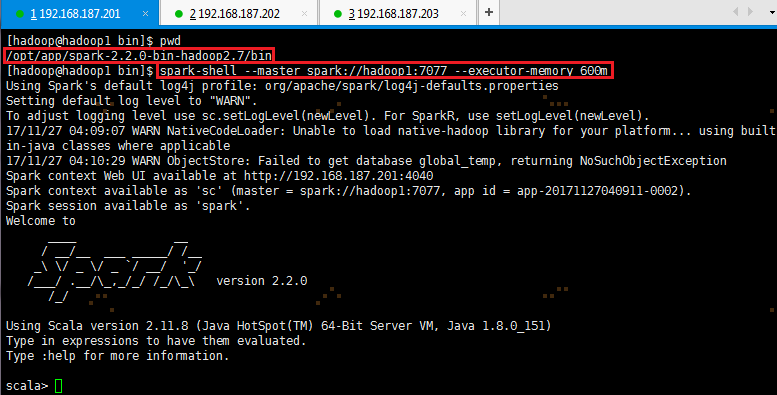
在命令中只指定了内存大小并没有指定核数,所以该客户端将占用该集群所有核并在每个节点分配600M内存
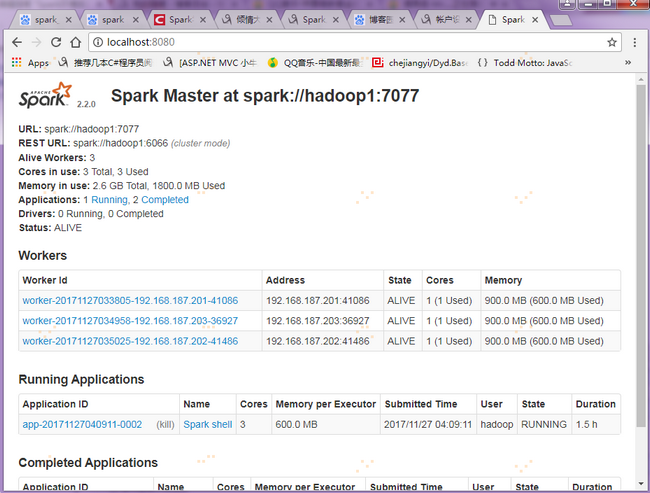
2. 查看Spark集群状态,通过上一步骤【注意】的IP端口映射设置,在宿主机浏览器输入localhost:8080,可以会直接映射到(192.168.187.201)hadoop1:8080上,如图:

3. Spark测试
3.1 使用Spark-shell测试
3.2 使用Spark-submit测试
Spark环境搭建(下)——Spark安装的更多相关文章
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- LNMP环境搭建:Nginx安装、测试与域名配置
Nginx作为一款优秀的Web Server软件同时也是一款优秀的负载均衡或前端反向代理.缓存服务软件 2.编译安装Nginx (1)安装Nginx依赖函数库pcre pcre为“perl兼容正则表达 ...
- Tesseract环境搭建及编译安装
Tesseract环境搭建及编译安装 Tesseract源码都是C++源码:对于不咋会C++的人来说,这真是...虽然说语言有相通性,但是...哎!!!!! 分享出来,也希望对大家有所帮助. 环境:w ...
- Python环境搭建和pycharm安装
Python环境搭建和pycharm安装 本人安装环境为Windows10系统,下载的Python版本为3.4社区版本,可参考 1.下载Python3.4版本 官网:https://www.pytho ...
- LNMP环境搭建之php安装,wordpress博客搭建
LNMP环境搭建之php安装,wordpress博客搭建 一.介绍: 1.什么是CGI CGI全称是"通用网关接口"(Common Gateway Interface),HTTP服 ...
- windows下大数据开发环境搭建(4)——Spark环境搭建
一.所需环境 · Java 8 · Python 2.6+ · Scala · Hadoop 2.7+ 二.Spark下载与解压 http://spark.apache.org/downloads.h ...
- spark在windows下的安装
Windows下最简的开发环境搭建这里的spark开发环境, 不是为apache spark开源项目贡献代码, 而是指基于spark的大数据项目开发. Spark提供了2个交互式shell, 一个 ...
- 学习Spark——环境搭建(Mac版)
大数据情结 还记得上次跳槽期间,与很多猎头都有聊过,其中有一个猎头告诉我,整个IT跳槽都比较频繁,但是相对来说,做大数据的比较"懒"一些,不太愿意动.后来在一篇文中中也证实了这一观 ...
随机推荐
- python 将文件夹内的图片转换成PDF
import os import stringfrom PIL import Imagefrom reportlab.lib.pagesizes import A4, landscapefrom re ...
- 关于sleep函数的一些问题和资料
//================================================================================================ 2 ...
- windows下查看端口占用情况及关闭相应的进程
经常,我们在启动应用的时候发现系统需要的端口被别的程序占用,如何知道谁占有了我们需要的端口,很多人都比较头疼,下面就介绍一种非常简单的方法. 例如:需要查看9001端口被谁占用,并将其进程强制关闭 在 ...
- Eclipse配置tomcat程序发布到哪里去了?
今天帮同事调一个问题,明明可以main函数执行的,他非要固执的使用tomcat执行,依他.但是发布到tomcat之后我想去看看发布后的目录,所以就打开了tomcat中的webapps目录,可是并没有发 ...
- struts2 使用filter解决中文乱码问题
1.编写fliter的代码 import java.io.IOException;import javax.servlet.Filter;import javax.servlet.FilterChai ...
- 我知道你不知道的负Margin
现如今,负margin技术的应用可谓越来越广,任一个大型站点惊鸿一瞥之下都会有其身影所在.个人认为负margin技术是学习css路上必不可缺少的课题之一,许多高级应用及疑难杂症修复都可以使用负marg ...
- Django中Q查询及Q()对象
问题 一般我们在Django程序中查询数据库操作都是在QuerySet里进行进行,例如下面代码: >>> q1 = Entry.objects.filter(headline__st ...
- java log4j基本配置及日志级别配置详解
java log4j日志级别配置详解 1.1 前言 说出来真是丢脸,最近被公司派到客户公司面试外包开发岗位,本来准备了什么redis.rabbitMQ.SSM框架的相关面试题以及自己做过的一些项目回顾 ...
- Effective Java 第三版——15. 使类和成员的可访问性最小化
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- spring中使用Hibernate中的getCurrentSession报出:createQuery is not valid without active transaction
1.错误信息 HTTP Status 500 - createQuery is not valid without active transaction type Exception report m ...