一致性hash-java实现treemap版
把不同号段的数据储存在不同的机器上,以用来分散压力。假如我们有一百万个QQ号,十台机器,,如何划分呢?
最简单粗暴的方法是用QQ号直接对10求余,结果为0-9 分别对应上面的十台机器。比如QQ号为 23900 的用户在编号为0的机器 23901的用户在编号为1的机器,以此类推。那么问题来了,现在QQ用户急剧上升 由一百万涨到了五百万,显然10台机器已经无能为力
了,于是我们扩充到25台。这个时候我们发现以前的数据全乱了。完蛋!只能跑路了……
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
所以在保证合理分散的情况下,我们还是是可拓展的。这就是一致性hash,一致性hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,当有数据过来按顺时针找到离他最近的一个点,这个点,就是我要的节点机器。如下图:
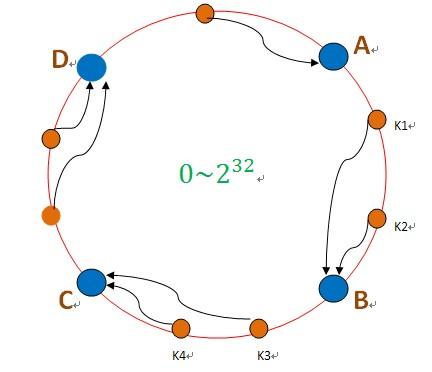 hash("192.168.128.670") ---->A //根据服务器IP hash出去生成节点
hash("192.168.128.670") ---->A //根据服务器IP hash出去生成节点
hash("192.168.148.670") ---->C //根据服务器IP hash出去生成节点
hash("81288812") ----> k1 //根据QQ号 hash出去生成值 ----->顺时针找到机器
hash("8121243812") ----> k4 //根据QQ号 hash出去生成值 ----->顺时针找到机器
这样当有新的机器加进来,旧的机器去掉,影响的也是一小部分的数据。这样看似比较完美了,,但假如其中一个节点B数据激增,挂了,所有数据会倒到C--->C也扛不住了---->所有数据会倒到D ……以此类推,最终全挂了!整个世界清静了!!!
显然,这种方式因为数据的不平均导致服务挂了。所以我们的一致性hash还需要具有平衡性。
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
为解决平衡性,一致性hash引入了虚拟节点”的概念。“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。这样我们如果有25台服务器,每台虚拟成10个,就有250个虚拟节点。这样就保证了每个节点的负载不会太大,压力均摊,有事大家一起扛!!!
hash("192.168.128.670#36kr01") ---->A //根据服务器IP hash出去生成节点
hash("192.168.128.670#36kr02") ---->B //根据服务器IP hash出去生成节点
hash("192.168.128.670#36kr03") ---->B //根据服务器IP hash出去生成节点
……
final 虚拟节点+murmurhash成了我们的解决方案:
class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
private TreeMap<Long, S> nodes; // 虚拟节点
private List<S> shards; // 真实机器节点
private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
public Shard(List<S> shards) {
super();
this.shards = shards;
init();
}
private void init() { // 初始化一致性hash环
nodes = new TreeMap<Long, S>();
for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
final S shardInfo = shards.get(i);
for (int n = 0; n < NODE_NUM; n++)
// 一个真实机器节点关联NODE_NUM个虚拟节点
nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
}
public S getShardInfo(String key) {
SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
if (tail.size() == 0) {
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
}
/**
* MurMurHash算法,是非加密HASH算法,性能很高,
* 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
* 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
* http://murmurhash.googlepages.com/
*/
private Long hash(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(
ByteOrder.LITTLE_ENDIAN);
// for big-endian version, do this first:
// finish.position(8-buf.remaining());
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}
一致性hash-java实现treemap版的更多相关文章
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- Java实现一致性Hash算法深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中”一致性Hash算法”部分,对于为什么要使用一致性Hash算法和一致性Hash算法的算法原 ...
- Java 一致性Hash算法的学习
目前我们很多时候都是在做分布式系统,但是我们需把客户端的请求均匀的分布到N个服务器中,一般我们可以考虑通过Object的HashCodeHash%N,通过取余,将客户端的请求分布到不同的的服务端.但是 ...
- 一致性hash算法及java实现
一致性hash算法是分布式中一个常用且好用的分片算法.或者数据库分库分表算法.现在的互联网服务架构中,为避免单点故障.提升处理效率.横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产 ...
- 一致性hash(整理版)
简单解释: 简单解释一致性hash的原理:网上通篇都是用服务器做的举例,我这里也如此,主要是便于理解. 通常:有N个客户端请求服务器,假设有M台web服务器,通常为了均衡访问会进行N%M的取模,然后分 ...
- 对一致性Hash算法及java实现(转)
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 对一致性Hash算法,Java代码实现的深入研究(转)
转载:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读 ...
- 【策略】一致性Hash算法(Hash环)的java代码实现
[一]一致性hash算法,基本实现分布平衡. package org.ehking.quartz.curator; import java.util.SortedMap; import java.ut ...
- 【转载】对一致性Hash算法,Java代码实现的深入研究
原文地址:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细 ...
- Java实现一致性Hash算法
Java代码实现了一致性Hash算法,并加入虚拟节点.,具体代码为: package com.baijob.commonTools; import java.util.Collection; im ...
随机推荐
- BATCH梯度下降,单变量线性回归
- C#后端调用前端的方法
在我实际开发过程中,刚好遇到c#后端要调用前端js中的方法,所以研究了一下,特分享如下: 前端代码: <%@ Page Language="C#" AutoEventWire ...
- 新浪微博 page应用 自适应高度设定 终于找到解决方法
我做的是PAGE应用,无法自适应高度.找了好久解决方法. 用js 设置父窗口 iframe 也不好用,有的浏览器不兼容. 官方上说发是这样的: 应用动态高度自适应 Iframe高度:开发者可以使Ifr ...
- 如何实现自己的Android MVP框架?
相信熟悉android开发的童鞋对MVP框架应该都不陌生吧,网上很多关于android中实现MVP的文章,大家可以直接搜索学习.这些文章中,MVP的实现思路基本都是把Activity.Fragment ...
- 安装JDK以及配置Java运行环境
安装JDK以及配置Java运行环境 1.JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2 ...
- h5滚动条加载到底部
https://www.zhihu.com/question/31861301 重复加载问题 http://www.jianshu.com/p/12aa901bee1f?from=timeline w ...
- ubuntu14 简单安装ffmpeg
1.简单安装 sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next sudo apt-get update sudo apt ...
- BZOJ 2199: [Usaco2011 Jan]奶牛议会
2199: [Usaco2011 Jan]奶牛议会 Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 375 Solved: 241[Submit][S ...
- 【ZOJ4063】Tournament(构造)
题意:n个人要打m轮比赛 每一轮每个人都要有一个对手.而且每个对手只能打一次.假设a与b打了,c与d打了, 那么后面的任意一轮如果a与c打了,那么b就必须和d打 问是否存在方案,输出字典序最小的一组, ...
- md5 加解密
using JGDJWeb.Model; using System; using System.Collections.Generic; using System.IO; using System.L ...