用PHP抓取百度贴吧邮箱数据
注:本程序可能非常适合那些做百度贴吧营销的朋友。
去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发。
对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些回复的邮箱,然后再粘贴发送邮件,不是被折磨死就是被累死。无聊至极写了一个抓取百度贴吧邮箱数据的程序,需要的拿走。
程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,界面懒得做了,效果如下:
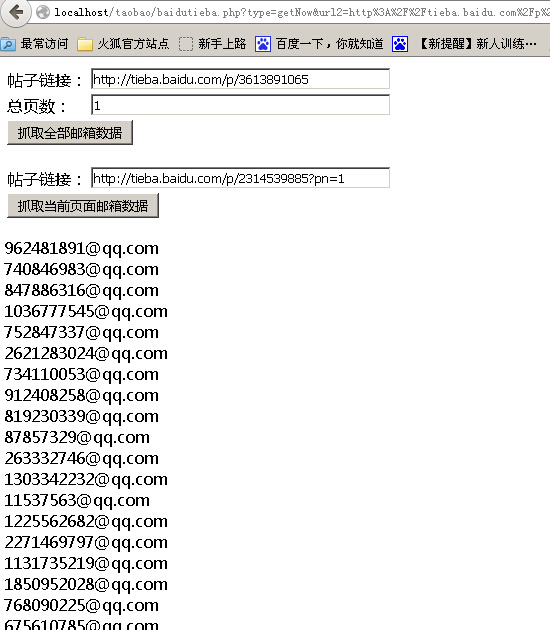
老规矩,直接贴源码
<?php
$url2="";
$page="";
if($_GET['url2']==""){
$url2="http://tieba.baidu.com/p/2314539885?pn=1";
}else{
$url2=$_GET['url2'];
} if($_GET['page']==""){
$page="1";
}else{
$page=$_GET['page'];
}
?>
<form action="" method="get">
<input type="hidden" value="getAll" name="type" />
<table>
<tr>
<td>帖子链接:</td><td><input type="text" name="url" value="http://tieba.baidu.com/p/2314539885" style="width:300px;" /></td>
</tr>
<tr>
<td>总页数:</td><td><input type="text" name="page" style="width:300px;" value="<?php echo $page;?>" /></td>
</tr>
<tr>
<td colspan=2><input type="submit" value="抓取全部邮箱数据" /></td>
</tr>
</table>
</form> <form action="" method="get">
<input type="hidden" value="getNow" name="type" />
<table>
<tr>
<td>帖子链接:</td><td><input type="text" name="url2" value="<?php echo $url2;?>" style="width:300px;" /></td>
</tr>
<tr>
<td colspan=2><input type="submit" value="抓取当前页面邮箱数据" /></td>
</tr>
</table>
</form>
<?php
if($_GET['type']!=""){
$counts=0;
if($_GET['type']=="getAll"){
$pages=$_GET['page'];
$url = $_GET['url'];
for($i=0;$i<$pages;$i++){
$ch2 = curl_init();
curl_setopt($ch2, CURLOPT_URL, $url);
curl_setopt($ch2, CURLOPT_FOLLOWLOCATION, TRUE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch2, CURLOPT_RETURNTRANSFER, TRUE);
$texts = curl_exec($ch2);
curl_close($ch2);
$dat=getEmail($texts);
for($j=0;$j<count($dat);$j++){
echo $dat[$j]."<br />";
$counts++;
}
}
}else if($_GET['type']=="getNow"){
$url = $_GET['url2'];
$ch2 = curl_init();
curl_setopt($ch2, CURLOPT_URL, $url);
curl_setopt($ch2, CURLOPT_FOLLOWLOCATION, TRUE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch2, CURLOPT_RETURNTRANSFER, TRUE);
$texts = curl_exec($ch2);
curl_close($ch2);
$dat=getEmail($texts);
for($i=0;$i<count($dat);$i++){
echo $dat[$i]."<br />";
$counts++;
}
}
echo '<h2>共采集到数据:'.$counts.'条</h2>';
}
function getEmail($str){
$pattern = "/([a-z0-9\-_\.]+@[a-z0-9]+\.[a-z0-9\-_\.]+)/";
preg_match_all($pattern,$str,$emailArr);
return $emailArr[0];
}
?>
用PHP抓取百度贴吧邮箱数据的更多相关文章
- Python爬虫之小试牛刀——使用Python抓取百度街景图像
之前用.Net做过一些自动化爬虫程序,听大牛们说使用python来写爬虫更便捷,按捺不住抽空试了一把,使用Python抓取百度街景影像. 这两天,武汉迎来了一个德国总理默克尔这位大人物,又刷了一把武汉 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- python3 - 通过BeautifulSoup 4抓取百度百科人物相关链接
导入需要的模块 需要安装BeautifulSoup from urllib.request import urlopen, HTTPError, URLError from bs4 import Be ...
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- C#.Net使用正则表达式抓取百度百家文章列表
工作之余,学习了一下正则表达式,鉴于实践是检验真理的唯一标准,于是便写了一个利用正则表达式抓取百度百家文章的例子,具体过程请看下面源码: 一:获取百度百家网页内容 public List<str ...
- Python3---爬虫---抓取百度贴吧
前言 该文章主要描述如何抓取百度贴吧内容.当然是简单爬虫实现功能,没有实现输入参数过滤等辅助功能,仅供小白学习. 修改时间:20191219 天象独行 import os,urllib.request ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- SQL Server定时自动抓取耗时SQL并归档数据发邮件脚本分享
SQL Server定时自动抓取耗时SQL并归档数据发邮件脚本分享 第一步建库和建表 USE [master] GO CREATE DATABASE [MonitorElapsedHighSQL] G ...
- Hawk: 20分钟无编程抓取大众点评17万数据
1. 主角出场:Hawk介绍 Hawk是沙漠之鹰开发的一款数据抓取和清洗工具,目前已经在Github开源.详细介绍可参考:http://www.cnblogs.com/buptzym/p/545419 ...
随机推荐
- IIS基本介绍
应用程序池-网站-应用程序 1 应用程序池 设置应用程序的各种设置,新建.修改应用程序的时候可以选择应用程序池 2 [站外图片上传中...(image-3924c8-1511163001873 ...
- Ackerman 函数
先留个简介: 函数定义: 从定义可以看出是一个递归函数.阿克曼函数不仅值增长的非常快,而且递归深度很高. 一般用来测试编译其优化递归调用的能力.. 如果用一下代码简单实现的话,输入参数4,2程序就直接 ...
- JDK源码阅读—ArrayList的实现
1 继承结构图 ArrayList继承AbstractList,实现了List接口 2 构造函数 transient Object[] elementData; // 数组保存元素 private i ...
- js获取当前时间戳,仿PHP函数模式
函数: /** * 获取时间戳函数 * 仿PHP函数模式 */ function time(){ var this_time = Date.parse(new Date()); this_time = ...
- p标签内不能嵌套div(注解)
相关知识: 内联元素可以嵌套内联元素,块级元素可以嵌套部分块级元素并也能嵌套内联元素,但内联元素不能嵌套块级元素.块级元素为block,内联元素为inline,拥有“inline”特性的同时又拥有“b ...
- layabox pc app web同步发布的工具
http://layabox.com/ 或者vs + unity3d开发游戏
- 微信小程序把玩(三十八)获取设备信息 API
原文:微信小程序把玩(三十八)获取设备信息 API 获取设备信息这里分为四种, 主要属性: 网络信息wx.getNetWorkType, 系统信息wx.getSystemInfo, 重力感应数据wx. ...
- Android零基础入门第48节:可折叠列表ExpandableListView
原文:Android零基础入门第48节:可折叠列表ExpandableListView 上一期学习了AutoCompleteTextView和MultiAutoCompleteTextView,你已经 ...
- Qt 开发WEB Services客户端代码(使用gSoap)
1. 首先下载gSoap开发包 http://sourceforge.net/projects/gsoap2 目录包含 wsdl2h.exe( 由wsdl生成接口头文件C/C++格式的头文件 ) ...
- windows qt 使用c++ posix接口编写多线程程序(真神奇)good
一.多线程是多任务处理的一种特殊形式,多任务处理允许让电脑同时运行两个或两个以上的程序.一般情况下,两种类型的多任务处理:基于进程和基于线程.基于进程的多任务处理是程序的并发执行.基于线程的多任务处理 ...