java容器篇
引言
第三天卡。。。
今天主要看了下java容器方面的知识,很累但是很充实。吃两把鸡去了,休息一下,再战。
开始
-Collection 存储对象的集合;Map 存储键值对的映射表
-Iterator(迭代器模式)
-集合访问器,用于循环访问集合中的对象
-所有实现了Collection接口的容器类都有iterator方法,用于返回一个实现了Iterator接口的对象。Iterator对象称作迭代器,Iterator接口方法能以迭代方式逐个访问集合中
各个元素,并可以从Collection中除去适当的元素
-Collection
-set(特征:无序且不可重复)
-TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为
O(logN)。
-HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的
-LinkedHashSet:具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序
-红黑树:漫画看懂红黑树 链接:https://www.sohu.com/a/201923614_466939
-list(特征:有序且可重复)
-ArrayList:基于动态数组实现,支持随机访问。
-概览
-实现了 RandomAccess 接口,因此支持随机访问。这是理所当然的,因为 ArrayList 是基于数组实现的,其数组的默认大小为 10。
-序列化
-基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列
transient Object[] A; //transient关键字声明数组默认不会被序列化
-为什么定义A数组要用transient关键字修饰,使其默认不被序列化?
假如现在实际有了5个元素,而elementData的大小可能是10,那么在序列化时只需要储存5个元素,数组中的最后五个元素是没有实际意义的,不需要储
存。所以ArrayList的设计者将elementData设计为transient,然后在writeObject方法中手动将其序列化,并且只序列化了实际存储的那些元素,而不是整
个数组
-序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射
调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
-java中序列化的目的:
-以某种存储形式使自定义对象持久化;
-将对象从一个地方传递到另一个地方。
-使程序更具维护性
-扩容
-添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity
>> 1),也就是旧容量的 1.5 倍
-扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作
的次数
-删除元素
-需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N), ArrayList 删除元素的代价是非常高的。
-fail-fast
-modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元
素的值不算结构发生变化
-在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。
-fail-fast与fail-safe
-fail-fast
-fail-fast机制在遍历一个集合时,当集合结构被修改,会抛出ConcurrentModificationException。
-java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
-fail-safe
-fail-safe任何对集合结构的修改都会在一个复制的集合上进行修改,不像fail-fast在原集合上修改,因此不会抛出ConcurrentModificationException
-java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
-优点
-避免了ConcurrentModificationException
-缺点
-需要复制集合,产生大量的无效对象,开销大
-无法保证读取的数据是目前原始数据结构中的数据。
-迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
-Vector:和 ArrayList 类似,但它是线程安全的。
-它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。因此是线程安全的
-与ArrayList比较
-Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
-Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
-LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
-概览
-基于双向链表实现,使用 Node 存储链表节点信息。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
每个链表存储了 first 和 last 指针
transient Node<E> first;
transient Node<E> last;
-与 ArrayList 的比较
-ArrayList 基于动态数组实现,LinkedList 基于双向链表实现;
-ArrayList 支持随机访问,LinkedList 不支持;
-LinkedList 在任意位置添加删除元素更快。
-Map
-TreeMap:基于红黑树实现
-HashMap:基于哈希表实现。
-存储结构
-内部包含了一个 Entry 类型的数组 table。
transient Entry[] table;
Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使
用拉链法来解决冲突,同一个链表中存放哈希值相同的 Entry。
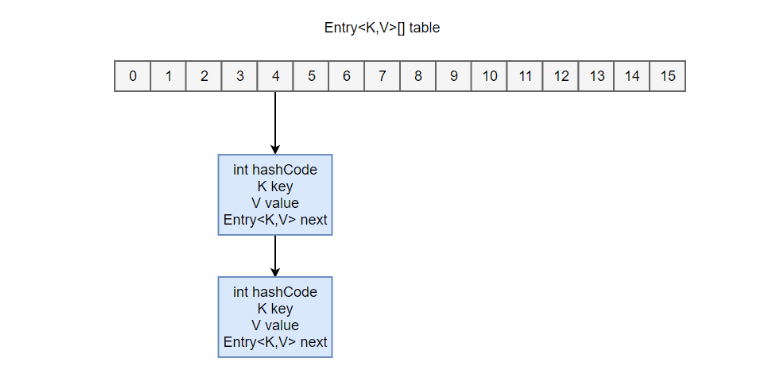
- 拉链法的工作原理
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");
新建一个 HashMap,默认大小为 16;
插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
-应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
-查找需要分成两步进行:
-计算键值对所在的桶;
-在链表上顺序查找,时间复杂度显然和链表的长度成正比。
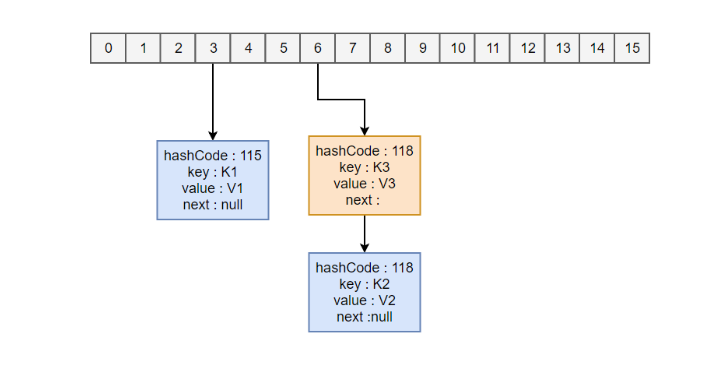
-put操作
-HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。
HashMap 使用第 0 个桶存放键为 null 的键值对。
-确定桶下标
-扩容
-基本原理
-重新计算桶下标
-计算数组容量
-链表转红黑树
-从 JDK 1.8 开始,一个桶存储的链表长度大于 8 时会将链表转换为红黑树
-与 HashTable 的比较
HashTable 使用 synchronized 来进行同步。
HashMap 可以插入键为 null 的 Entry。
HashMap 的迭代器是 fail-fast 迭代器。
HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
-HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现
在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
-LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
java容器篇的更多相关文章
- 菜鸟刷面试题(五、Java容器篇)
目录: java 容器都有哪些? Collection 和 Collections 有什么区别? List.Set.Map 之间的区别是什么? HashMap 和 Hashtable 有什么区别? 如 ...
- Java并发-同步容器篇
作者:汤圆 个人博客:javalover.cc 前言 官人们好啊,我是汤圆,今天给大家带来的是<Java并发-同步容器篇>,希望有所帮助,谢谢 文章如果有问题,欢迎大家批评指正,在此谢过啦 ...
- Java并发容器篇
作者:汤圆 个人博客:javalover.cc 前言 断断续续一个多月,也写了十几篇原创文章,感觉真的很不一样: 不能说技术有很大的进步,但是想法确实跟以前有所不同: 还没开始的时候,想着要学的东西太 ...
- java容器——面试篇
背景:java容器是面试中基础的基础,所以 有必要对着源码撸一遍. 进行了高度总结,首推: https://github.com/CyC2018/CS-Notes/blob/master/notes/ ...
- Java面试题(容器篇)
容器 18.java 容器都有哪些? 如图: 首先分为Collection.Map: Collection下分为List.Set和Queue: List下分为ArrayList和LinkedLis ...
- 【Java心得总结七】Java容器下——Map
我将容器类库自己平时编程及看书的感受总结成了三篇博文,前两篇分别是:[Java心得总结五]Java容器上——容器初探和[Java心得总结六]Java容器中——Collection,第一篇从宏观整体的角 ...
- 【Java心得总结六】Java容器中——Collection
在[Java心得总结五]Java容器上——容器初探这篇博文中,我对Java容器类库从一个整体的偏向于宏观的角度初步认识了Java容器类库.而在这篇博文中,我想着重对容器类库中的Collection容器 ...
- 【Java心得总结五】Java容器上——容器初探
在数学中我们有集合的概念,所谓的一个集合,就是将数个对象归类而分成为一个或数个形态各异的大小整体. 一般来讲,集合是具有某种特性的事物的整体,或是一些确认对象的汇集.构成集合的事物或对象称作元素或是成 ...
- Java提高篇(三三)-----Map总结
在前面LZ详细介绍了HashMap.HashTable.TreeMap的实现方法,从数据结构.实现原理.源码分析三个方面进行阐述,对这个三个类应该有了比较清晰的了解,下面LZ就Map做一个简单的总结. ...
随机推荐
- Tarjan-割点
割点——tarjan #include <bits/stdc++.h> using namespace std; ; ; int n, m; int ans;//个数 * MAXM], n ...
- Mac安装和卸载Mysql
目录 一.安装 二.环境变量 2.1 MySQL服务的启停和状态的查看 三.启动 四.初始化设置 4.1 退出sql界面 五.配置 5.1 检测修改结果 一.安装 第一步:打开网址,https://w ...
- 程序员需要掌握的七种 Python 代码更易维护的武器
检查你的代码风格 PEP 8 是 Python 代码风格规范,它规定了类似行长度.缩进.多行表达式.变量命名约定等内容.尽管你的团队自身可能也会有稍微不同于 PEP 8 的代码风格规范,但任何代码风格 ...
- java中大整型BigInteger及setBit和testBit方法
最近在修改公司之前的项目,在项目中遇到了权限校验的问题,代码中出现了BigInteger的setBit()testBit()方法,之前未接触过,所以了解了下BigInteger. 在Java中,由CP ...
- day 35 协程 IO多路复用
0.基于socket发送Http请求 import socket import requests # 方式一 ret = requests.get('https://www.baidu.com/s?w ...
- vue 做一个简单的TodoList
目录结构 index.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"&g ...
- Selenium多层级的iframe中元素的定位
很多时候我们遇到多层级的iframe就会想各种方法去获取iframe中的元素,但其实很简单就可以做到的,就是一级一级获取就可以了,获取至你需要的那个层级即可,下面看下实际的案例:(转) <fra ...
- 深入理解.NET Core的基元(三) - 深入理解runtimeconfig.json
原文:Deep-dive into .NET Core primitives, part 3: runtimeconfig.json in depth 作者:Nate McMaster 译文:深入理解 ...
- 【Android - 自定义View】之自定义View实现“刮刮卡”效果
首先来介绍一下这个自定义View: (1)这个自定义View的名字叫做 GuaguakaView ,继承自View类: (2)这个View实现了很多电商项目中的“刮刮卡”的效果,即用户可以刮开覆盖层, ...
- if判断语句的总结
1.表达式:关系表达式或逻辑表达式: 2.表达式的运算结果应该是“真”或者“假”: 真:执行该语句: 假:跳过该语句,执行下一条语句: 3.“语句”可以是单语句也可以是复合语句: ...