ubuntu 单机配置hadoop
前言
因为是课程要求,所以在自己电脑上安装了hadoop,由于没有使用虚拟机,所以使用单机模拟hadoop的使用,可以上传文件,下载文件。
1.安装配置JDK
Ubuntu18.04是自带Java1.8的,你可以在命令行输入
java -version查看,如果你想重新配置的话清查看以下的教程。
下载JDK
单击下载地址进行下载
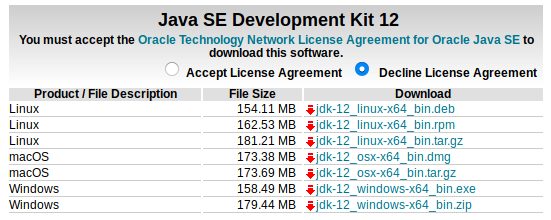
下载之前点击 Accept License Agreement, 然后下载 jdk-12_linux-64_bin.tar.gz
解压JDK
进行下载目录,打开terminal,输入
tar zxvf jdk-12_linux-64_bin.tar.gz
将解压后的文件夹移动到 /usr/local 文件夹中,在命令行中输入如下命令
sudo mv jdk-12_linux-64_bin /usr/local
jdk-12_linux-64_bin 为你解压后得到的文件夹,如果和你的不一样,清按实际情况进行修改。
配置Java环境
在terminal中输入如下命令
sudo gedit ~/.bashrc
在文件末尾写入如下内容
export JAVA_HOME=/usr/local/jdk-12_linux-64_bin
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
然后在terminal中输入如下命令
source ~/.bashrc
测试Java安装是否成功
在terminal中输入如下命令
java -version
如果配置成功的话会显示出java 的版本,再继续输入如下命令
javac
配置成功的话会显示出可以使用的命令
2.下载hadoop
请单击下载地址进行下载
下载 hadoop-2.7.6.tar.gz 这个版本,有需要可以下载其他版本
3.解压到 /opt 目录(如果有需要可以改为其他目录,后面的操作也要陆续修改)
打开terminal进入下载目录,执行命令
tar -zxvf hadoop-2.7.6.tar.gz -C /opt/
4.配置hadoop环境变量
打开命令行,输入如下命令
sudo gedit /etc/profile
在文件中添加如下代码
export HADOOP_HOME=/opt/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
在命令行中执行如下命令
source /etc/profile
5.配置hadoop
5.1配置hadoop-env.sh
在命令行中执行如下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
找到# The java implementation to use.将其下面的一行改为:
export JAVA_HOME=/usr/local/jdk-12_linux-64_bin
如果你没有按照我上面的步骤安装java,清填写你自己的java路径
5.2 配置core-site.xml (5.2和5.3中配置文件里的文件路径和端口随自己习惯配置)
其中的IP:192.168.44.128为虚拟机ip,不能设置为localhost,如果用localhost,后面windows上用saprk连接服务器(虚拟机)上的hive会报异常
在命令行输入 ifconfig查看自己的ip地址,在下面的代码中将 192.168.44.128 改为你自己的ip就可以了
在命令行中输入如下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/core-site.xml
在打开的文件中添加如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/hadoop-2.7.6</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.44.128:8888</value>
</property>
</configuration>
保存并关闭文件,然后在命令行中输入以下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
在打开的文件中修改如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-2.7.6/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-2.7.6/tmp/dfs/data</value>
</property>
</configuration>
6.SSH免密登陆
在命令行中输入如下内容
sudo apt-get install openssh-server
cd ~/.ssh/
ssh localhost ssh-keygen -t rsa
/* 这个过程中持续按回车就可以了 */
cat id_rsa.pub >> authorized_keys
7.启动与停止
第一次启动hdfs需要格式化,在命令行中输入如下命令(出现询问输入Y or N,全部输Y即可)
cd /opt/hadoop-2.7.6
./bin/hdfs namenode -format
启动
./sbin/start-dfs.sh
停止
./sbin/stop-dfs.sh
验证,浏览器输入:http://192.168.44.128:50070
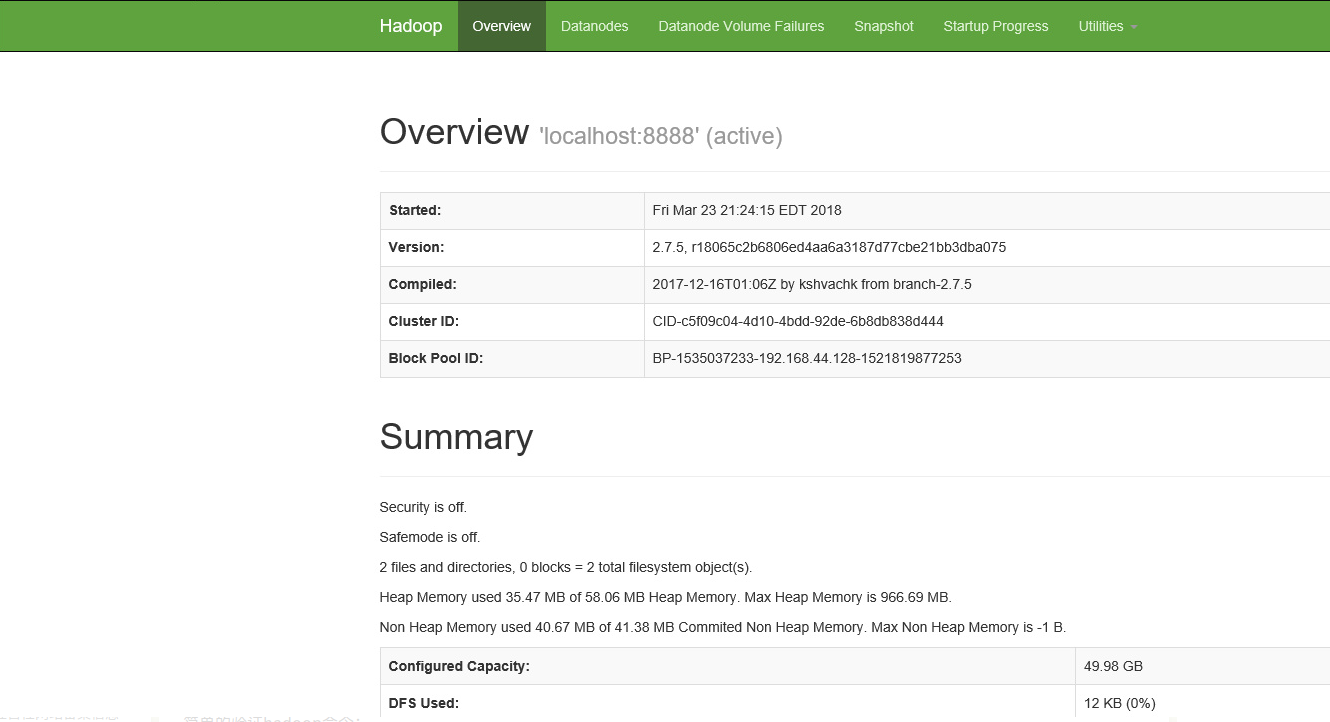
简单的验证hadoop命令:
hadoop fs -mkdir /test
在浏览器查看,出现如下图所示,即为成功
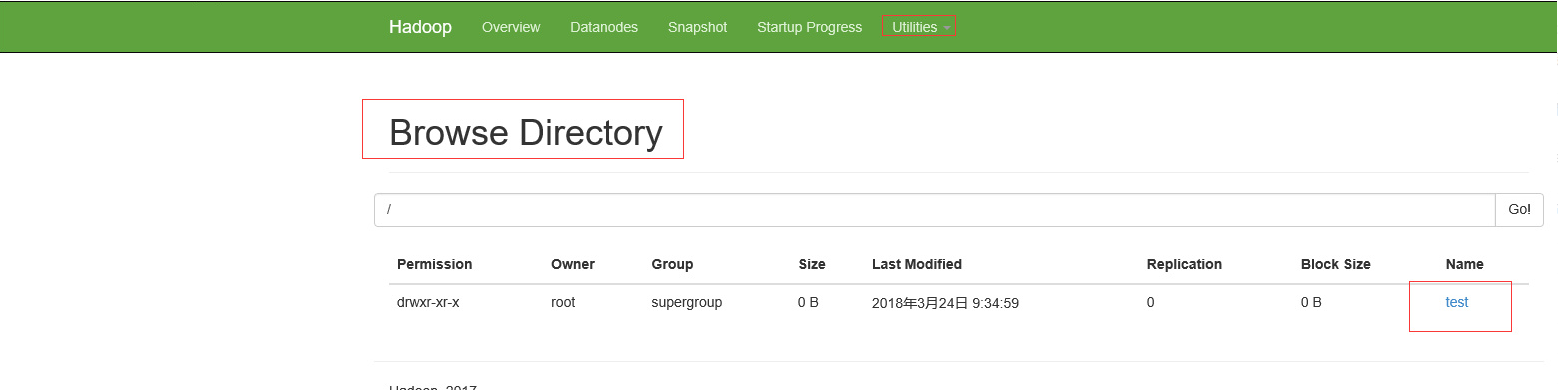
你也可以输入以下命令上传文件到hadoop
hadoop fs -put /test 1.txt /test
8.配置yarn
8.1 配置mapred-site.xml
命令行中输入如下命令:
cd /opt/hadoop-2.7.6/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xml
在文件中添加内容
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.2 配置yarn-site.xml
命令行中输入如下命令:
sudo gedit yarn-site.xml
在文件中添加内容
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.3 yarn启动与停止
启动
cd /opt/hadoop-2.7.5
./sbin/start-yarn.sh
停止
./sbin/stop-yarn.sh
浏览器查看:http://192.168.44.128:8088
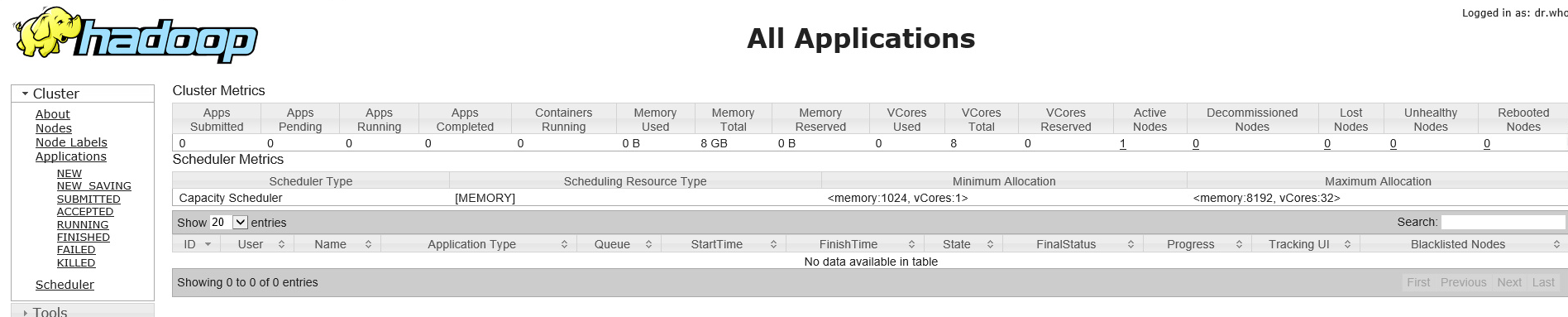
jps查看进程

输出如下所示,则表示hadoop单机模式配置成功
ubuntu 单机配置hadoop的更多相关文章
- hadoop单机配置
条件: 先下载VMware1.2,然后安装. 下载ubuntu-1.4.05-desktop-amd64.iso.下载地址:http://mirrors.aliyun.com/ubuntu-relea ...
- 沉淀,再出发——在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享
在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享 一.工作准备 首先,明确工作的重心,在Ubuntu Kylin15.04中配置Hadoop集群,这里我是用的双系统中的 ...
- Hadoop单机模式安装-(3)安装和配置Hadoop
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在Ubuntu安装完 ...
- (转)单机上配置hadoop
哈哈,几天连续收到百度两次电话,均是利好消息,于是乎不知不觉的自己的工作效率也提高了,几天折腾了好久终于在单机上配置好了hadoop,然后也成功的运行了一个用例,耶耶耶耶耶耶. 转自:http://w ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Data - Hadoop单机配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
随机推荐
- Zabbix监控ActiveMQ
当我们在线上使用了ActiveMQ 后,我们需要对一些参数进行监控,比如 消息是否有阻塞,哪个消息队列阻塞了,总的消息数是多少等等.下面我们就通过 Zabbix 结合 Python 脚本来实现对 Ac ...
- 解码mmo游戏服务器三:大地图同步(aoi)
问题引入:aoi(area of interest).在大地图中,玩家只需要关心自己周围的对象变化,而不需要关心距离较远的对象的变化.所以大地图中的数据不需要全部广播,只要同步玩家自己视野范围的消息即 ...
- Python自学day-1
一.Python介绍 1.python擅长领域: WEB开发:Django. pyramid. Tornado. Bottle. Flask. WebPy 网络编程:Twisted(牛 ...
- Nginx部署多个站点
Nginx部署多个站点 一,介绍与需求 1.1,介绍 详细介绍请看nginx代理部署Vue与React项目,在这儿主要介绍多个站点的配置 1.2,需求 有时候想在一台服务器上为不同的域名/不同的二级域 ...
- 分布式个人理解概述和dubbo实现简述
什么是分布式?为什么使用分布式? 个人有一些浅薄的理解希望可以批评指正,从概念和应用 两个方面概述: 一.概念:分布式也叫分布式服务,也就是说 他是 一种面向服务思想的程序设计和架构风格,典 ...
- 蓝桥杯:合并石子(区间DP+平行四边形优化)
http://lx.lanqiao.cn/problem.page?gpid=T414 题意:…… 思路:很普通的区间DP,但是因为n<=1000,所以O(n^3)只能拿90分.上网查了下了解了 ...
- 大规模SDN云计算数据中心组网的架构设计
本文首先分析了在大规模SDN数据中心组网中遇到的问题.一方面Underlay底层组网规模受限于设备实际的转发能力和端口密度,单一Spine-leaf的Fabric架构无法满足大规模组网的需求:另一方面 ...
- Linux虚拟机怎么添加磁盘?
一.VMware workstation菜单栏
- fastdfs java client error
tracker,storage运行正常,利用fdfs_test程序做测试,可以正常上传下载文件. tracker的端口配置 # HTTP port on this tracker server htt ...
- Touch Bar 废物利用系列 | 在触控栏上显示 Dock 应用图标
都说 Intel 第八代 CPU 对比上代是牙膏不小心挤多了,而配备第八代 CPU 的 MacBook Pro,只有 Touch Bar 版本,虽然贵了一点,但就一个字 -- 买! 收到电脑后,兴冲冲 ...