hadoop单机配置
条件:
先下载VMware1.2,然后安装。
下载ubuntu-1.4.05-desktop-amd64.iso。下载地址:http://mirrors.aliyun.com/ubuntu-releases/14.04.5/
下载hadoop2.7。下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/
下载jdk-8u171-linux-x64.tar.gz。到官网下载。参考教程:https://blog.csdn.net/zl007700/article/details/50533675
将ubuntu安装在VMware上。
1.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
设置密码
sudo passwd hadoop
增加管理员权限
sudo adduser hadoop sudo

最后退出当前用户,然后重新登陆hadoop用户。
2.更新apt
sudo apt-get update

3.安装SSH,配置SSH无密码登录
安装SSH server:
sudo apt-get install openssh-server
安装后,用命令登录:
ssh localhost
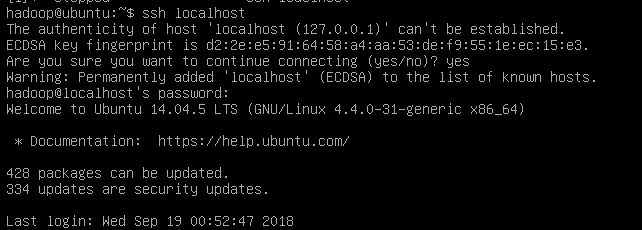
但是这样登陆需要密码。所以首先退出刚才的 ssh,利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
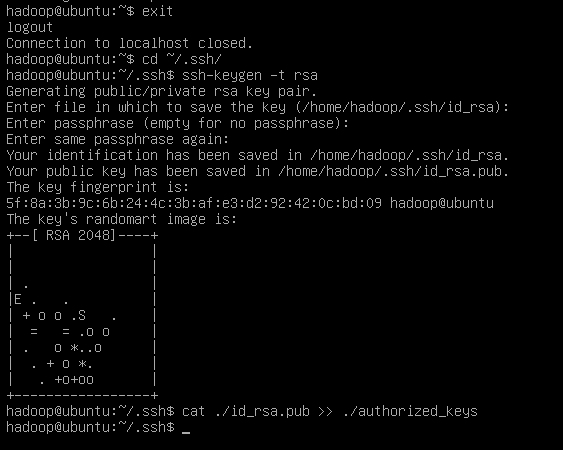
然后就可以无密码登录了

3.免配置环境安装jdk
sudo apt-get install default-jre default-jdk
上述安装过程需要访问网络下载相关文件,请保持联网状态。安装结束以后,需要配置JAVA_HOME环境变量,请在Linux终端中输入下面命令打开当前登录用户的环境变量配置文件.bashrc:
vim ~/.bashrc
在文件最前面添加如下单独一行(注意,等号“=”前后不能有空格),然后保存退出:
export JAVA_HOME=/usr/lib/jvm/default-java
接下来,要让环境变量立即生效,请执行如下代码:
source ~/.bashrc
执行上述命令后,可以检验一下是否设置正确:

4.安装hadoop
将下载好的hapoop解压到/usr/local/
sudo tar -zxf ~/Downloads/hadoop-2.7.6.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.6/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
我在写文件夹名时写错了。所以用来查看当前目录下的文件夹的命令是 Is 文件名
最后查看hadoop的版本:

5.单机配置hadoop
hadoop默认为非分布式模式(本地模式)。无需进行其他配置即可。
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
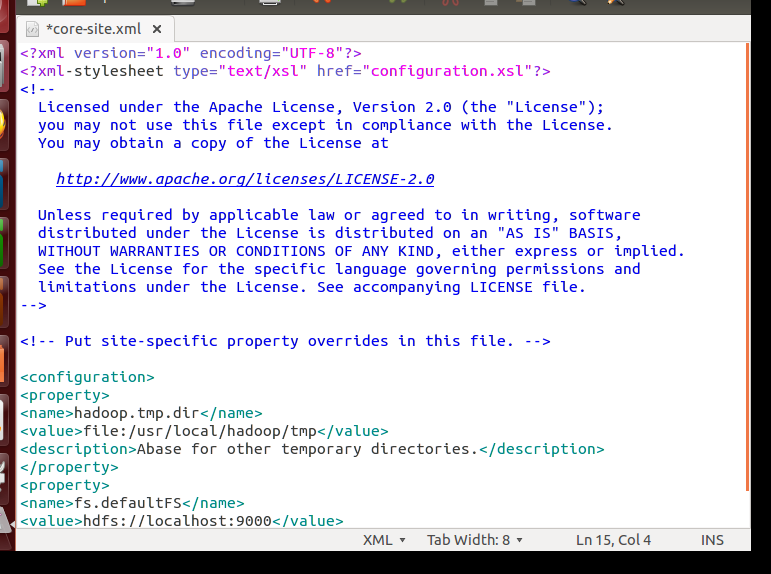
修改配置文件 core-site.xml
修改成:
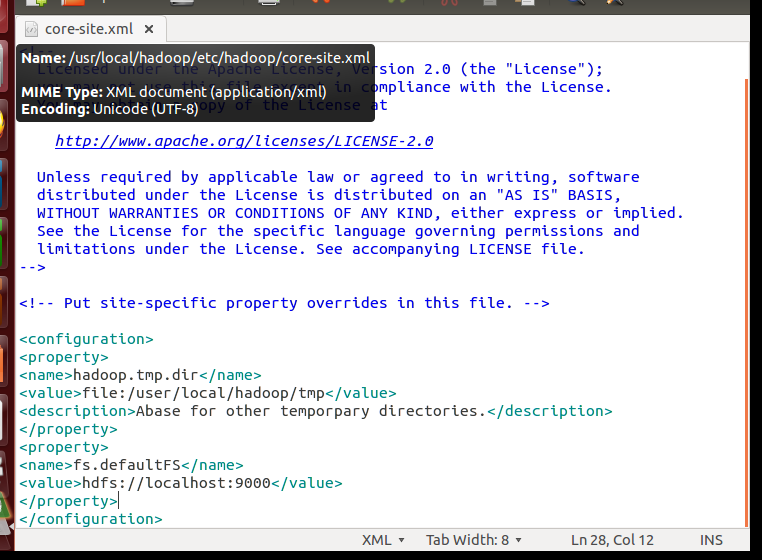
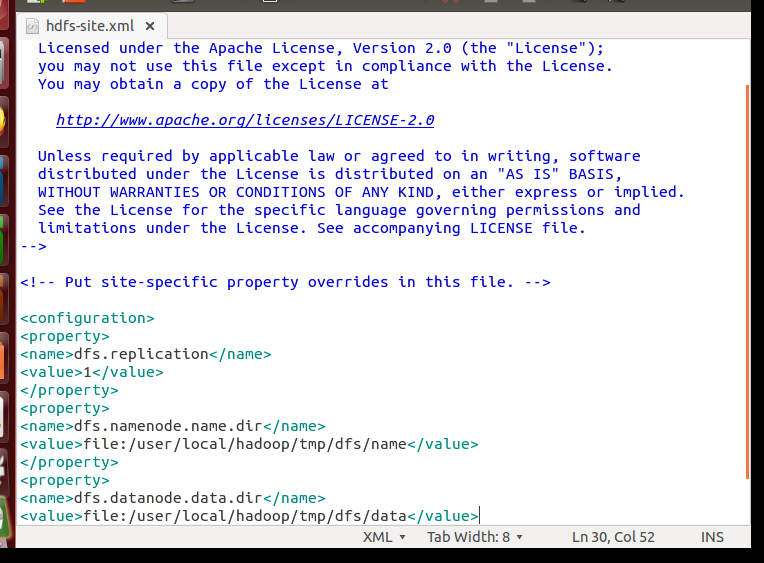
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
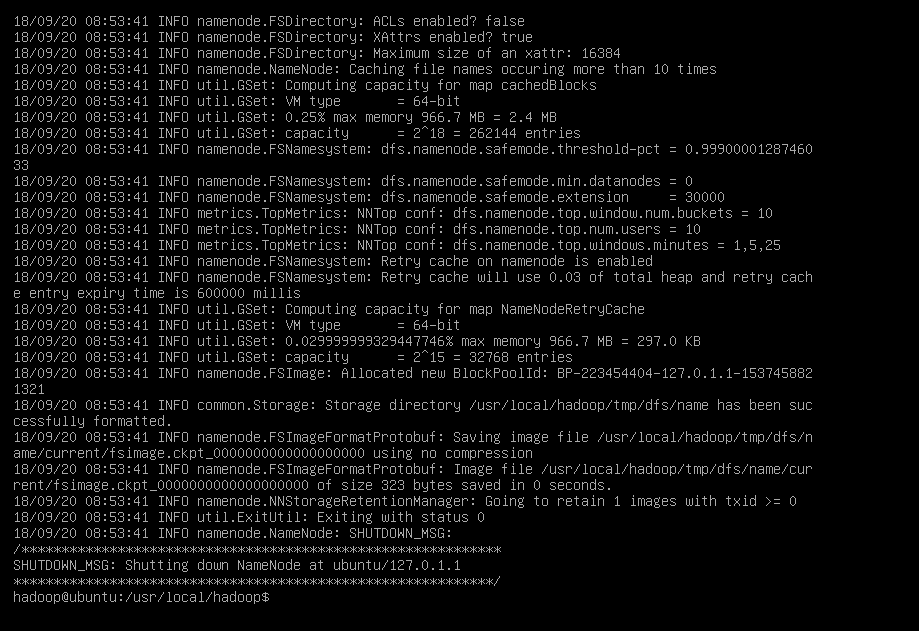
配置完成后,执行 NameNode 的格式化:
./bin/hdfs namenode -format
我执行命令时一直提醒找不到路径,需要先cd到/usr/local/hadoop目录下

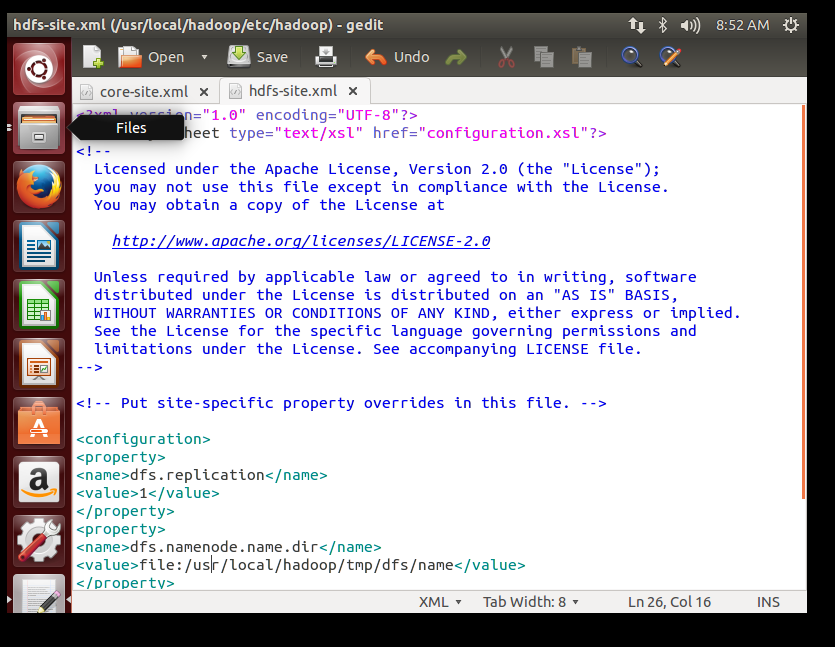
然后发现原来的xml文件写错了,正确的应该写成:
然后再执行:
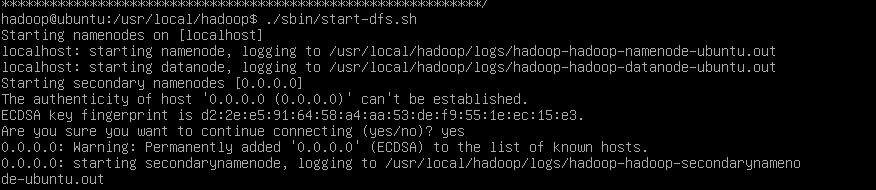
接着开启 NameNode 和 DataNode 守护进程。
./sbin/start-dfs.sh
hadoop单机配置的更多相关文章
- Data - Hadoop单机配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Hadoop单机模式安装-(3)安装和配置Hadoop
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在Ubuntu安装完 ...
- 沉淀,再出发——在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享
在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享 一.工作准备 首先,明确工作的重心,在Ubuntu Kylin15.04中配置Hadoop集群,这里我是用的双系统中的 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- Hadoop单机模式的配置与安装
Hadoop单机模式的配置与安装 单机hadoop集群正常启动后进程情况 ResourceManager NodeManager SecondaryNameNode NameNode DataNode ...
- Hadoop单机安装配置过程:
1. 首先安装JDK,必须是sun公司的jdk,最好1.6版本以上. 最后java –version 查看成功与否. 注意配置/etc/profile文件,在其后面加上下面几句: export JAV ...
- ubuntu 单机配置hadoop
前言 因为是课程要求,所以在自己电脑上安装了hadoop,由于没有使用虚拟机,所以使用单机模拟hadoop的使用,可以上传文件,下载文件. 1.安装配置JDK Ubuntu18.04是自带Java1. ...
随机推荐
- 【转】nginx的模块变量(HTTP核心模块变量)
nginx的HTTP核心模块引入了大量的变量,可以在指定范围内使用这些变量的值,可以分为三类:一是客户请求头中发送的变量.二是服务器端响应头中的变量,第三是nginx产生的各种变量,我们可以使用$变量 ...
- Servlet处理表单数据
Servlet 表单数据 很多情况下,需要传递一些信息,从浏览器到 Web 服务器,最终到后台程序.浏览器使用两种方法可将这些信息传递到 Web 服务器,分别为 GET 方法和 POST 方法. 使用 ...
- KMS激活工具
工具介绍 KMS_VL_ALL,国外MDL论坛的一款KMS激活工具,可自动识别需要激活的Windows以及Office的VL版本,无需联网即可全自动检测激活,支持创建自动续期计划,相比于国外的同类工具 ...
- 非阻塞socket与epoll
阻塞socket. –阻塞调用是指调用结果返回之前,当前线程会被挂起.函数只有在得到结果之后才会返回. –对于文件操作read,fread函数调用会将线程阻塞. –对于socket,accept与re ...
- Sass和Compass设计师指南 Ben Frain 中文高清PDF扫描版
Sass和Compass设计师指南是<响应式Web设计:HTML5和CSS3实战>作者Ben Frain的又一力作.作者通过丰富.完整的案例,循序渐进地展示了Sass和Compass的使用 ...
- javascript 设计模式实践之策略模式--输入验证
博客地址:http://www.cnblogs.com/kongxianghai/p/4985122.html,写的挺好的推荐下!
- console的使用
一.显示信息的命令 console.log("normal"); // 用于输出普通信息 console.info("information"); // 用于输 ...
- day-15递归与函数
生成器send方法 send的工作原理 1.send发生信息给当前停止的yield 2.再去调用__next__()方法,生成器接着往下指向,返回下一个yield值并停止 # 案例: persons ...
- 【转】在Asp.net前台和后台弹出提示框
源地址:http://blog.sina.com.cn/s/blog_5200dd680100mkk0.html
- 【转】ClickOnce部署Winform程序的方方面面
源地址:http://www.cnblogs.com/parry/archive/2012/10/30/ClickOnce_Winform_Deployment.html