一次使用scrapy的问题记录
前景描述:
需要获取某APP的全国订单量,及抢单量。由于没有全国的选项所以只能分别对每一个城市进行订单的遍历。爬虫每天运行一次,一次获取48小时内的订单,从数据库中取出昨天的数据进行对比,有订单被抢则更新,无则不操作。(更新逻辑在这里不重要,重要的是爬取逻辑)。每个订单有发布时间,根据发布时间判断,在48小时外的就停止爬取,开始爬取下一个城市。
先看第一版:
#spider
# 构造一些请求参数,此处省略
# 从配置中读取所有城市列表
cities = self.settings['CITY_CH']
# end_signal为某个城市爬取完毕的信号,
self.end_signal = False
for city in cities:
# 通过for循环对每个城市进行订单爬取
post_data.update({'locationName':city})
count = 1
while not self.end_signas:
post_data.update({'pageNum':str(count)})
data = ''.join(json.dumps(post_data, ensure_ascii=False).split())
sign = MD5Util.hex_digest(api_key + data + salt).upper()
params = {
'apiKey':api_key,
'data':data,
'system':system,
'sign':sign
}
meta = {'page':count}
yield scrapy.Request(url=url, method='POST', body=json.dumps(params, ensure_ascii=False),
headers=self.headers, callback=self.parse,meta=meta, dont_filter=True)
count+=1
self.end_signal = False
def parse(self,response):
# 略
# 在spiderMiddleware中根据返回的item中的订单时间进行判断(此处不详写)
def process_spider_output(self, response, result, spider):
result_bkp = []
for res in result:
if res['order_time'] < before_date(2): #before_date为自定义的时间函数
logger.info("{%s}爬取完毕,开始爬取下一个城市" % (res['city_name']))
spider.end_signal = True
break
result_bkp.append(res.copy())
return result_bkp
乍一看没有问题,遍历每个城市,再到解析 解析完后返回item到spiderMiddleware中进行判断订单是否超过48小时,超过就设置
self.end_signal为True跳出spider中的while循环,注意while循环后面又将这个参数设置False然后下个城市的循环就开始了。
问题来了:
spider中将request返回出去添加到队列中,这里有一个队列,当response下载好返回回来通过parse函数去处理的时候也有一个队列,众所周知运气不好的人总会偶尔遇到一点网络问题,来举个栗子就清楚了
栗子:spider中将城市A的1、2、3订单页(2、3为超过48小时的订单页),添加到队列中,下载器去下载的时候可能第2页代理挂了,第三页超过48小时,中间件判断成功设置self.end_signal=True进行下一个城市的爬取。城市B添加了1、2、3(都在48小时内),这个时候城市A的第二页订单下载完成了在中间件中判断又将self.end_signal=True,于是城市B后面的订单也就都没了,都没了。。。,直接开始了下一个城市的订单!
一版总结:
不要在一个异步的程序中通过一个全局变量去控制整个程序的流程。(总结的不好,可以帮我总结一下)
第二版:
既然不能通过全局变量来控制,那能不能让每个城市带一个标识来指明订单爬取结束。
先看代码
#spider
cities = self.settings['CITY_CH']
# end_signal为某个城市爬取完毕的信号,
self.end_signal = False
for city in cities:
# 通过for循环对每个城市进行订单爬取
post_data.update({'locationName':city})
count = 1
print(cities)
print(city)
while in cities:
post_data.update({'pageNum':str(count)})
data = ''.join(json.dumps(post_data, ensure_ascii=False).split())
sign = MD5Util.hex_digest(api_key + data + salt).upper()
params = {
'apiKey':api_key,
'data':data,
'system':system,
'sign':sign
}
meta = {'page':count}
yield scrapy.Request(url=url, method='POST', body=json.dumps(params, ensure_ascii=False),
headers=self.headers, callback=self.parse,meta=meta, dont_filter=True)
count+=1
self.end_signal = False
def parse(self,response):
# 略
# 在spiderMiddleware中根据返回的item中的订单时间进行判断(此处不详写)
def process_spider_output(self, response, result, spider):
result_bkp = []
for res in result:
if res['order_time'] < before_date(2): #before_date为自定义的时间函数
if res['city_name'] in spider.cities:
spider.cities.remove(res['city_name'])
logger.info("{%s}爬取完毕,开始爬取下一个城市" % (res['city_name']))
break
result_bkp.append(res.copy())
return result_bkp
看逻辑也有点意思,判断这个城市是否在列表中,在的话说明还没爬取完毕,爬取完毕了就删除这个城市。嗯!运行一下!
有意思的来了,第一个城市爬取正常,第二个城市不见了,上诉代码中打印的城市没有显示第二个城市,直接跳到了最后一个(设就三个城市) 怎么被吞了呢。
敏感数据就不截图了。
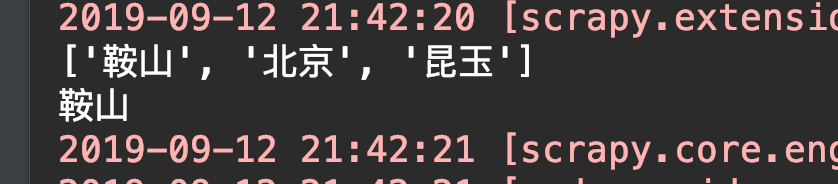
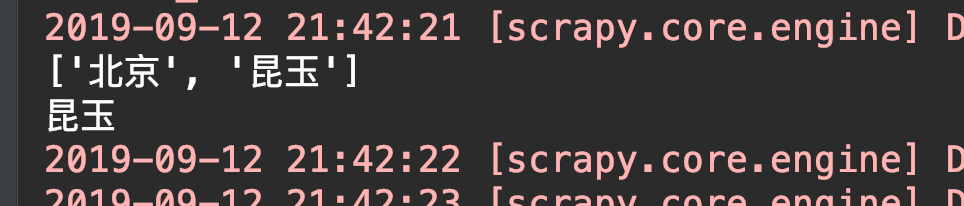
可以看到 打印的城市列表中明明还有北京的没有被删除,为啥直接到最后一个城市了呢?
可能有大佬已经看出来了,我是生生打断点调试了半天,甚至怀疑是for循环内部有什么bug。
最后灵机一动(滑稽),难倒是因为城市列表的问题?我for循环它,然后又在他内部去删除它里面的元素,可以这样吗?
写个demo测试一下
cities = ['鞍山', '北京', '昆玉',]
for city in cities:
cities.remove('鞍山')
print(city)
# 错误就来了! 果然不能在循环它的时候再对它进行删除操作
ValueError: list.remove(x): x not in list
至于在运行scrapy的时候为什么没有报这个错误,可能是在别的地方做了异常处理,但是有这个问题在,我们先去修复它一下。
将for city in cities改为for city in cities.copy(),完美解决!!!
还有一个小点就是python的值传递和地址传递,在处理item的时候要注意。
一次使用scrapy的问题记录的更多相关文章
- python scrapy简单爬虫记录(实现简单爬取知乎)
之前写了个scrapy的学习记录,只是简单的介绍了下scrapy的一些内容,并没有实际的例子,现在开始记录例子 使用的环境是python2.7, scrapy1.2.0 首先创建项目 在要建立项目的目 ...
- Scrapy使用详细记录
这几天,又用到了scrapy框架写爬虫,感觉忘得差不多了,虽然保存了书签,但有些东西,还是多写写才好啊 首先,官方而经典的的开发手册那是需要的: https://doc.scrapy.org/en/l ...
- Python Scrapy安装杂症记录
昨天安装了scrapy一切正常,调试了bbsSpider案例(详见上文),今日开机因为冰封还原,提示找不到python27.dll,重新安装了python2.7, 使用easy-install scr ...
- scrapy安装问题记录
ubuntu小白一枚,由于对于ubuntu的不了解所以导致有的问题解决不了只能白痴的重装一遍. 总结一下问题: 1.pip安装自带scrapy版本过低官方不提供维护,卸载不完全导致重装最新版不成功 # ...
- scrapy笔记集合
细读http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 目录 Scrapy介绍 安装 基本命令 项目结构以及爬虫应用介绍 简单使用示例 选 ...
- Scrapy笔记:日志的使用
scrapy的日志记录有两种方式: spider.logger.xx()和python标准库中的logger = logging.get_Logger('log information') 向日志对象 ...
- windows下搭建scrapywindows 7 (64) + python 3.5 (64)
说明 之前在 window 10 (64) + python 3.5 (64) 环境下就已经成功安装了 scrapy,当然也费了不少周折. 由于近日将系统换回 windows 7 (64),再安装 s ...
- 爬虫:Scrapy11 - Logging
Scrapy 提供了 log 功能.可以通过 scrapy.log 模块使用.当前底层实现使用了 Twisted logging,不过可能在之后会有所变化. log 服务必须通过显式调用 scrapy ...
- scrapy学习记录
scrapy是一个用来爬取一个或多个网站的数据,提取数据的应用框架.下载过程非常复杂,而且会遇到各种问题.所以写个博客来记录下. 安装好python2.7之后,就可以开始.安装scrapy前还需要安装 ...
随机推荐
- Java连载11-转义字符&整数型
一.转义符 1.\'代表单引号:\\代表\; 二.native2ascii.exe JDK中自带的native2ascii.exe命令,可以将文字转换成unicode编码形式 我们使用这个程序尝试一下 ...
- 同时运行多个 tomcat 修改端口
修改 tomcat 配置文件,路径: tomcat_home/conf/server.xml 1.HTTP端口,默认8080,如下改为8081 <Connector connectionTim ...
- Java虚拟机学习笔记(三)--- 生存还是死亡
即便是可达性分析中不可达的对象,也不代表该对象一定被回收,一个对象被“宣判死刑”需要经过两次标记,第一次是被可达性算法标记为不可用,然后进入第二次筛选,筛选条件是对象是否有必要执行finalize() ...
- 9个tcpdump使用实例
tcpdump能帮助我们捕捉并保存网络包,保存下来的网络包可用于分析网络负载情况,包可通过tcpdump命令解析,也可以保存成后缀为pcap的文件,使用wireshark等软件进行查看. 以下将给出9 ...
- JavaWeb零基础入门-01 基础概念说明
一.序言 从学校出来到实习,发现学校学的东西太过基础,难于直接运用于工作中.而且工作中,现在都以web开发为主,学校开了web开发相关课程.自己学的不够深入,所以本人自学JavaWeb开发,介于学习巩 ...
- 直击根源:微信小程序中web-view再次刷新后页面需要退两次
背景 在上一章(直击根源:vue项目微信小程序页面跳转web-view不刷新)解决了vue在小程序回退不刷新的问题之后,会引出了一个刷新的页面需要点击返回两次才能返回上一个页面 问题描述 在A页面从B ...
- flask 使用基础
转 https://blog.csdn.net/yelena_11/article/details/53404892
- F#周报2019年第33期
新闻 宣告.NET Core 3.0预览版8 新的fable.io站点伴随着更多文档发布 正在努力使你的团队相信F#的益处?Compositional IT能够提供帮助 提名2019年度F#社区英雄 ...
- [HNOI2009]双递增序列(动态规划,序列dp)
感觉这个题还蛮难想的. 首先状态特别难想.设\(dp[i][j]\)表示前i个数,2序列的长度为j的情况下,2序列的最后一个数的最小值. 其中1序列为上一个数所在的序列,2序列为另外一个序列. 这样设 ...
- Appium+Python+Genymotion ------环境配置
前言 之前总是在找方向,也研究了很多的工具,终于找到了适合自己的一套,打算把学习的过程做一个记录,给自己加深印象,也希望能给其他人一些帮助. 一.工具准备 1.Appium // http://a ...