【R语言学习笔记】 Day1 CART 逻辑回归、分类树以及随机森林的应用及对比
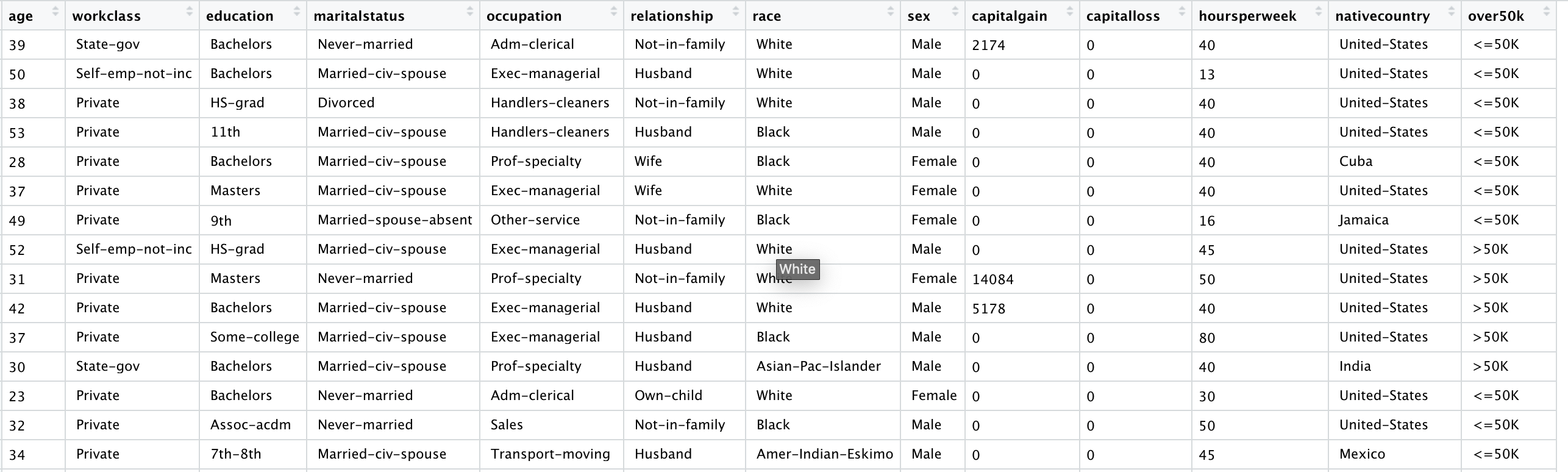
1. 目的:根据人口普查数据来预测收入(预测每个个体年收入是否超过$50,000)
2. 数据来源:1994年美国人口普查数据,数据中共含31978个观测值,每个观测值代表一个个体
3. 变量介绍:
(1)age: 年龄(以年表示)
(2)workclass: 工作类别/性质 (e.g., 国家机关工作人员、当地政府工作人员、无收入人员等)
(3)education: 受教育水平 (e.g., 小学、初中、高中、本科、硕士、博士等)
(4)maritalstatus: 婚姻状态(e.g., 未婚、离异等)
(5)occupation: 工作类型 (e.g., 行政/文员、农业养殖人员、销售人员等)
(6)relationship: 家庭身份 (e.g., 丈夫、妻子、孩子等)
(7)race: 种族
(8)sex: 性别
(9)capitalgain: 1994年的资本收入 (买卖股票、债券等)
(10)capitalloss: 1994年的资本支出 (买卖股票、债券等)
(11)hoursperweek: 每周工作时长
(12)nativecountry: 国籍
(13)over50k: 1994年全年工资是否超过$50,000
4. 应用及分析
census <- read.csv("census.csv") #读取文件
library(caTools) # 加载caTools包
# 将数据分为测试集和训练集
set.seed(2000)
spl <- sample.split(census$over50k, SplitRatio = 0.6)
census.train <- subset(census, spl == T) # 测试集
census.test <- subset(census, spl == F) # 训练集
# 构建逻辑回归模型
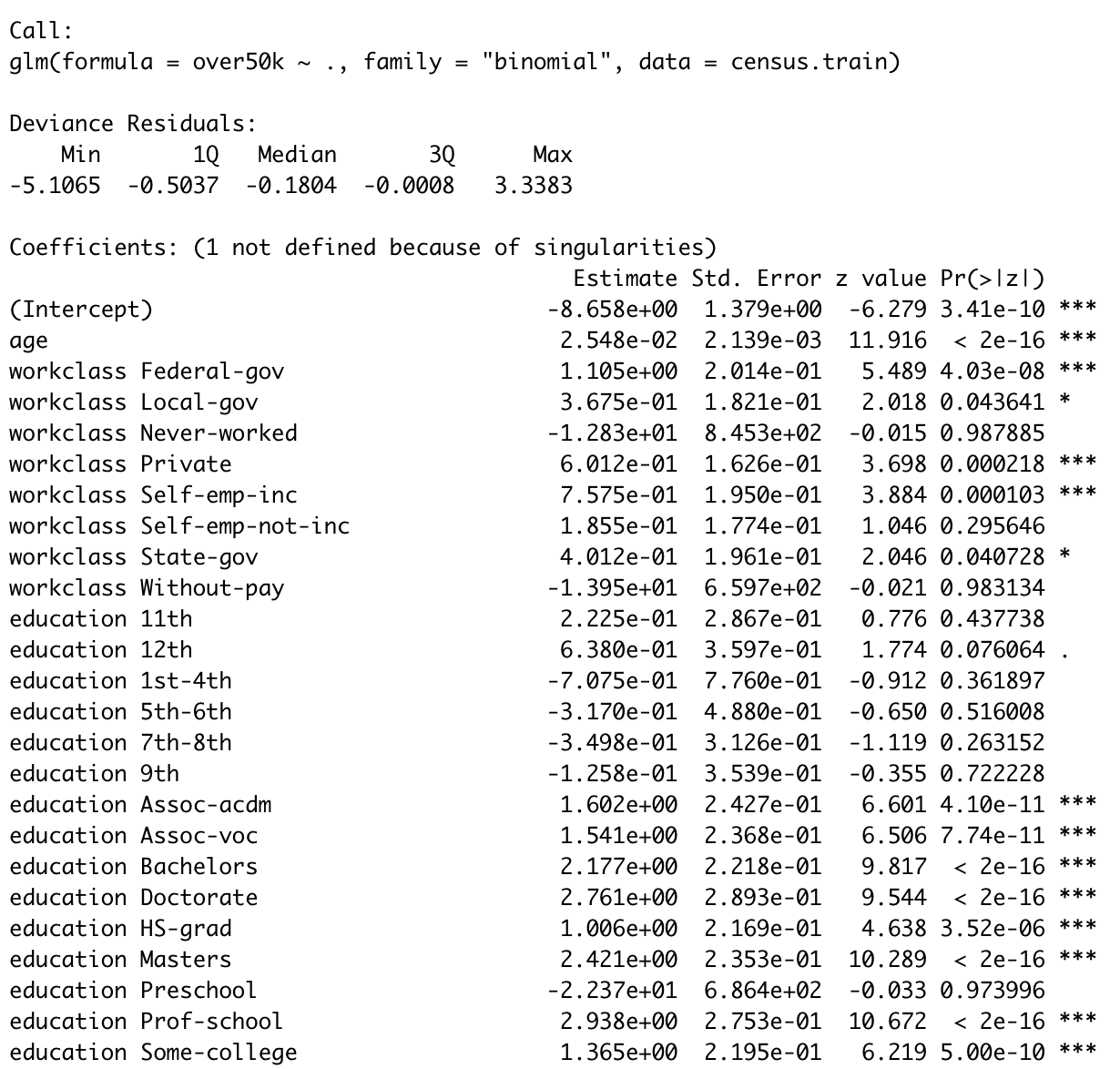
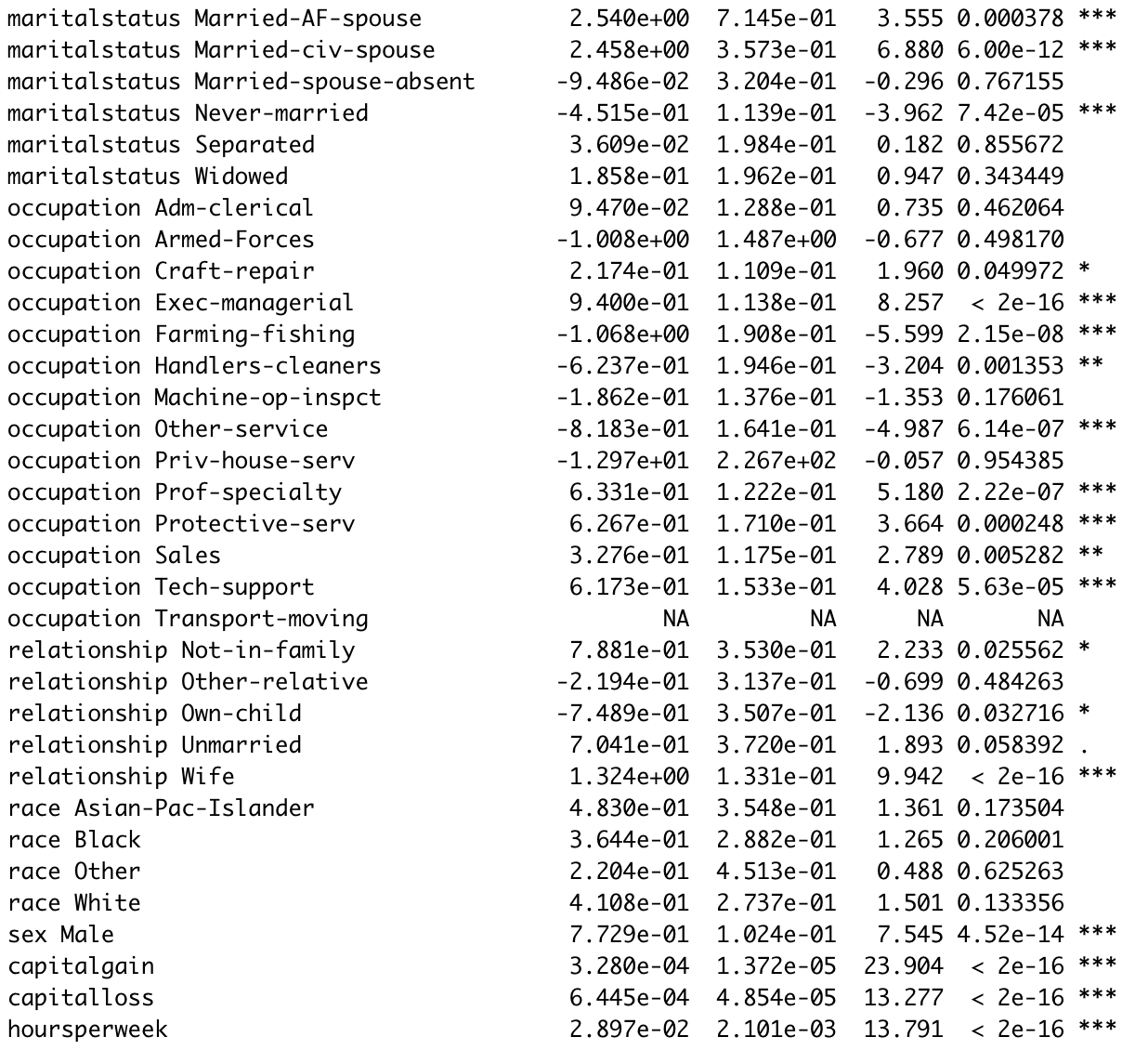
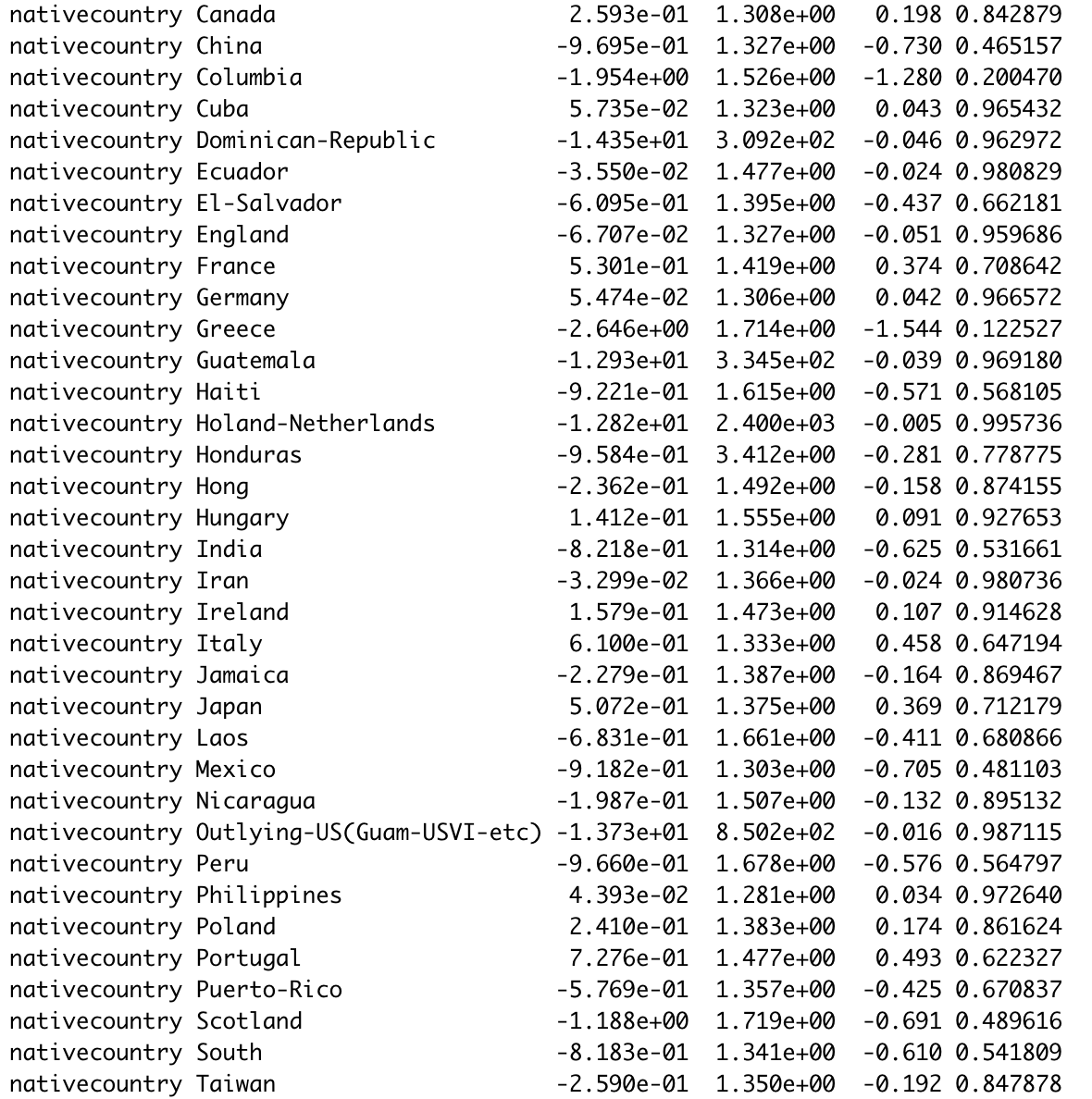
census.logistic <- glm(over50k ~ ., data = census.train, family = 'binomial')
summary(census.logistic) # 查看模型拟合结果

# 在临界值为0.5的情况下,逻辑回归模型应用到测试集的准确性
## method1
census.logistic.pred <- predict(census.logistic, newdata = census.test, type = 'response')
library(caret)
confusionMatrix(as.factor(ifelse(census.logistic.pred >= 0.5, " >50K", " <=50K")), as.factor(census.test$over50k)) ## method2
table(census.test$over50k, census.logistic.pred>= 0.5)
sum(diag(table(census.test$over50k, census.logistic.pred>= 0.5)))/nrow(census.test) #0.8552 # 测试集的基础准确性
table(census.test$over50k)/nrow(census.test) #0.759
# ROC 以及 AUC
library(ROCR)
census.pred <- prediction(census.logistic.pred, census.test$over50k)
census.perf <- performance(census.pred, 'tpr', 'fpr')
plot(census.perf, colorize = T) #ROC curve
as.numeric(performance(census.pred, 'auc')@y.values) #AUC value is 0.9061598
虽然逻辑回归模型准确率高达0.8572,且变量的显著性有助于我们判断个体的收入情况;但是在自变量中的分类变量类别太多的情况下,我们无法判断哪些变量更重要。
因此,接下来构建CART模型。
# 默认的CART模型
library(rpart)
library(rpart.plot)
census.cart <- rpart(over50k ~ ., data = census.train, method = 'class')
prp(census.cart) # 作图
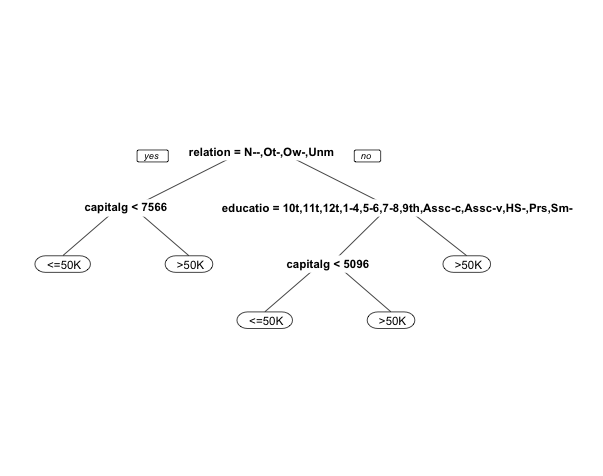
# 模型准确性
census.cart.pred <- predict(census.cart, newdata = census.test, type = 'class')
## method1
table(census.test$over50k, census.cart.pred)
sum(diag(table(census.test$over50k, census.cart.pred)))/nrow(census.test)
## method2
confusionMatrix(census.cart.pred, as.factor(census.test$over50k)) # 模型准确性为0.8474
# ROC 以及 AUC
census.cart.pred2 <- predict(census.cart, newdata = census.test)
census.cart.pred2
census.cart.pred3 <- prediction(census.cart.pred2[,2], census.test$over50k)
census.cart.perf <- performance(census.cart.pred3, 'tpr', 'fpr')
plot(census.cart.perf, colorize = T) # ROC as.numeric(performance(census.cart.pred3, 'auc')@y.values) #AUC value is 0.8470256
# 随机森林模型
set.seed(1)
census.train.small <- census.train[sample(nrow(census.train), 2000),]
## 构建随机森林模型之前先减小训练集样本数量。
## 因为随机森林过程中包含大量运算过程,小样本更益于模型的建立 library(randomForest)
census.train.small.rf <- randomForest(over50k ~ ., data = census.train.small) # 模型预测
census.train.small.rf.pred <- predict(census.train.small.rf, newdata = census.test) # 模型准确性
confusionMatrix(census.train.small.rf.pred, as.factor(census.test$over50k)) # 0.8533
因为随机森林模型是一系列分类决策树的集合,因此与分类决策树相比,随机森林模型的解释性稍差,但仍可用一些方法来衡量变量的重要性
# 方法一:统计随机过程中每个变量出现的次数
vu <- varUsed(census.train.small.rf, count=TRUE)
vusrted <- sort(vu, decreasing = FALSE, index.return = TRUE)
# draw a Cleveland dot plot
dotchart(vusorted$x, names(census.train.small.rf$forest$xlevels[vusorted$ix]))
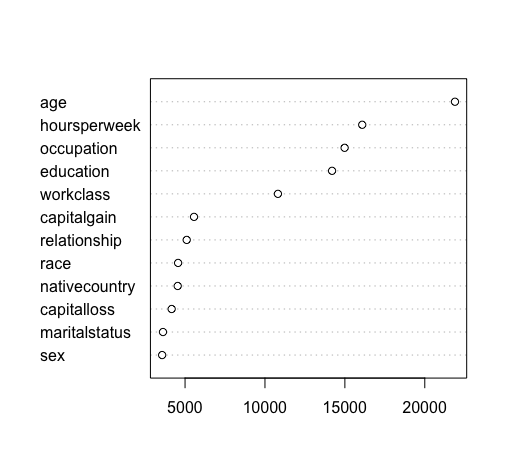
其中,age出现次数最多,sex出现次数最少。
# 方法二:比较平均Gini指数的下降程度
varImpPlot(census.train.small.rf)
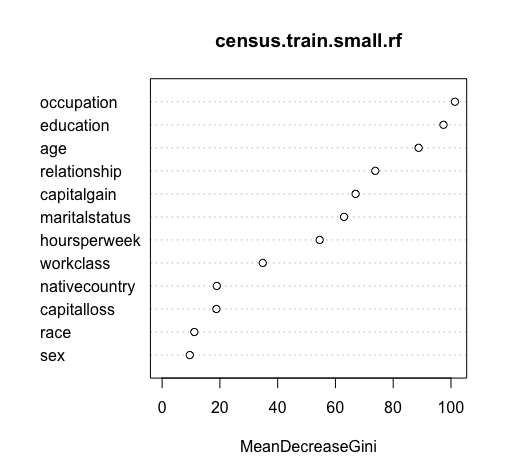
其中,occupation、education、age的平均Gini指数减少的最多,sex的平均Gini指数减少的最少
# 改进的CART模型(考虑cp值)
library(caret)
library(lattice)
library(ggplot2)
library(e1071) # 找出使得准确率最高的cp值
set.seed(2)
numFolds <- trainControl(method = 'cv', number = 10)
cpGrid <- expand.grid(.cp = seq(0.002,0.1,0.002))
train(over50k ~ ., data = census.train,
method = 'rpart', trControl = numFolds, tuneGrid = cpGrid) # cp = 0.002时模型准确度最高 # 构建新的CART模型(cp=0.002)
census.bestTree <- rpart(over50k ~ ., data = census.train, method = 'class', cp = 0.002)
prp(census.bestTree) # 作图 # 模型预测
predCV <- predict(census.bestTree, newdata = census.test, type = 'class') # 计算新模型的准确率
## method1
table(census.test$over50k, predCV)
sum(diag(table(census.test$over50k, predCV)))/nrow(census.test)
## method2
confusionMatrix(predCV, as.factor(census.test$over50k)) # 0.8612
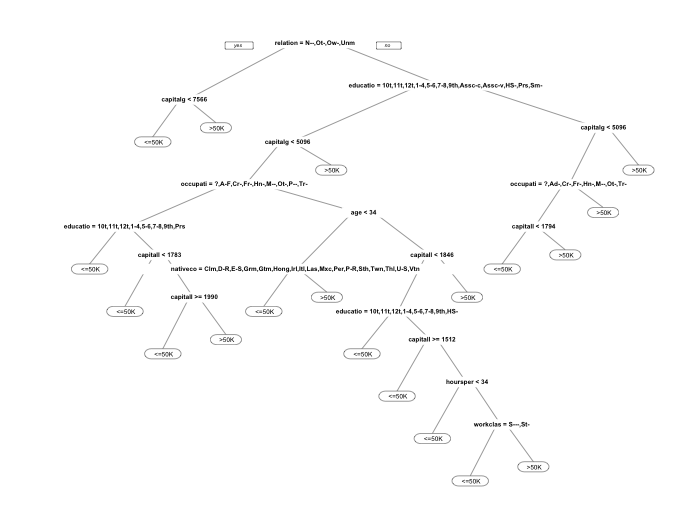
考虑cp值以后的CART模型的准确性比默认模型高了1%左右,但是模型明显复杂了更多,因此需要在模型简洁性及准确性之间做出权衡。
本案例中,默认模型足够简洁且准确度也很高,所以倾向使用默认模型。
【R语言学习笔记】 Day1 CART 逻辑回归、分类树以及随机森林的应用及对比的更多相关文章
- R语言学习笔记:基础知识
1.数据分析金字塔 2.[文件]-[改变工作目录] 3.[程序包]-[设定CRAN镜像] [程序包]-[安装程序包] 4.向量 c() 例:x=c(2,5,8,3,5,9) 例:x=c(1:100) ...
- R语言学习笔记—决策树分类
一.简介 决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类.其典型算法包括ID3算法.C4.5算法.C5.0算法.CART算法等.每一个决策树包括根节点(root ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记(一)
1.不同的行业对数据集(即表格)的行和列称谓不同,统计学家称其为观测(observation)和变量(variable): 2.R语言存储数据的结构: ①向量:类似于C语言里的一位数组,执行组合功能的 ...
- R语言学习笔记:字符串处理
想在R语言中生成一个图形文件的文件名,前缀是fitbit,后面跟上月份,再加上".jpg",先不百度,试了试其它语言的类似语法,没一个可行的: C#中:"fitbit&q ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习笔记 (入门知识)
R免费使用:统计工具:# 注释,行注释块注释:anything="这是注释的内容"常用R语言编辑器:Rsutdio,Tinn-R,Eclipse+StatET:中文会有乱码帮助:? ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
随机推荐
- python接口自动化2-第一次发送get请求
前言 Requests: 让 HTTP 服务人类,唯一的一个非转基因的 Python HTTP 库,人类可以安全享用: Requests继承了urllib2的所有特性,能满足当前网络的需求,支持Pyt ...
- VMware15.5版本下安装Windows_Server_2008_R2
一.新建虚拟机 第一步:打开VMware15.5虚拟机,在欢迎界面点击新建虚拟机: 第二步:选择典型(推荐)选项-->适用于新手,单击下一步: 第三步:选定最后一项稍后安装操作系统,单击下一步: ...
- 渗透测试-基于白名单执行payload--Compiler
复现亮神课程 0x01 Compiler前言 说明:Microsoft.Workflow.Comiler.exe是.NET Framework默认自带的一个实用工具,用户能够以XOML工作流文件的形式 ...
- Python开发【第九篇】字典
字典 字典是一种可变的容器,可以存储任意类型的数据 字典中的每个数据都是用键进行索引,而不像序列容器(str,list,tuole)可以用整数进行索引 字典中的数据没有先后顺序,字典的存储是无序的 字 ...
- shell传递参数(三)
$n:n代表一个数字,指执行脚本的第n个参数.特别地,$0指执行的文件名 [root@ipha-dev71- exercise_shell]# cat test.sh #!/bin/bash echo ...
- 【Autofac打标签模式】Aspect拦截器
[ Autofac打标签模式]开源DI框架扩展地址: https://github.com/yuzd/Autofac.Annotation/wiki 前提条件 自己new一个对象不能实现拦截器功能,必 ...
- 玩转ArduinoJson库 V5版本
1.前言 一直以来,博主的事例代码中都一直使用到JSON数据格式.而很多初学者一直对JSON格式有很大疑惑,所以博主特意分出一篇博文来重点讲解Arduino平台下的JSON库--Arduino ...
- pytorch笔记
Tensor slice Tensor的indices操作 以[2,3]矩阵为例,slice后可以得到任意shape的矩阵,并不是说一定会小于2行3列. import torch truths=tor ...
- 记一次 XxlRpcException:xxl-rpc request timeout at 超时问题
事件起因 昨天有同事找我到,说他搭建的 XXL-JOB 任务调度系统不能工作了,调用总是出错(服务端返回 500)希望我能帮忙处理一下,不过说实话我也没有搭建过 XXL-JOB 的经验,但是既然同事请 ...
- day3------基本数据类型int, bool, str,list,tuple,dict
基本数据类型(int, bool, str,list,tuple,dict) 一.python基本数据类型 1. int 整数. 主要用来进行数学运算 2. str 字符串, 可以保存少量数据并进 ...