POJ(有向图求LCA)
| Time Limit: 2000MS | Memory Limit: 10000K | |
| Total Submissions: 18013 | Accepted: 5774 |
Description
Input
nr_of_vertices
vertex:(nr_of_successors) successor1 successor2 ... successorn
...
where vertices are represented as integers from 1 to n ( n <= 900 ). The tree description is followed by a list of pairs of vertices, in the form:
nr_of_pairs
(u v) (x y) ...
The input file contents several data sets (at least one).
Note that white-spaces (tabs, spaces and line breaks) can be used freely in the input.
Output
For example, for the following tree:
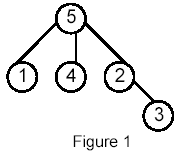
Sample Input
5
5:(3) 1 4 2
1:(0)
4:(0)
2:(1) 3
3:(0)
6
(1 5) (1 4) (4 2)
(2 3)
(1 3) (4 3)
Sample Output
2:1
5:5
有向图求LCA,注意输入的处理。
有向图只有一个树根,利用并查集求树根。无向图中可选任意一点作树根,在dfs是比有向图多一个条件,详情见代码。
#include"cstdio"
#include"cstring"
#include"vector"
using namespace std;
const int MAXN=;
int V;
vector<int> G[MAXN];
int par[MAXN];
void prep()
{
for(int i=;i<=MAXN;i++)
{
par[i]=i;
}
}
int fnd(int x)
{
if(par[x]==x)
return x;
return par[x]=fnd(par[x]);
}
void unite(int father,int son)
{
par[son]=fnd(father);
}
int fa[MAXN],dep[MAXN];
void dfs(int u,int father,int d)
{
fa[u]=father,dep[u]=d;
for(int i=;i<G[u].size();i++)
dfs(G[u][i],u,d+);//在无向图中 需要加上 if(G[u][i]!=father)
}
int lca[MAXN];
int LCA(int u,int v)
{
while(dep[u]>dep[v]) u=fa[u];
while(dep[v]>dep[u]) v=fa[v];
while(u!=v)
{
u=fa[u];
v=fa[v];
}
return u;
}
int main()
{
while(scanf("%d",&V)!=EOF)
{
for(int i=;i<=V;i++) G[i].clear();
prep();
memset(lca,,sizeof(lca));
for(int i=;i<V;i++)
{
int u,t;
scanf("%d:(%d)",&u,&t);
while(t--)
{
int v;
scanf("%d",&v);
G[u].push_back(v);
unite(u,v);
}
}
int root=fnd();
dfs(root,-,);
int Q;
scanf("%d",&Q);
while(true)
{
char ch=getchar();
if(ch=='(')
{
int u,v;
scanf("%d %d",&u,&v);
int a=LCA(u,v);
lca[a]++;
Q--;
getchar();//不能丢,有开就有闭
}
if(Q==) break;
}
for(int i=;i<=V;i++)
{
if(lca[i]!=) printf("%d:%d\n",i,lca[i]);
}
}
return ;
}
tarjan+并查集离线算法
#include"cstdio"
#include"cstring"
#include"vector"
using namespace std;
const int MAXN=;
int V;
vector<int> G[MAXN];
int que[MAXN][MAXN];
int vis[MAXN];
int par[MAXN];
int cnt[MAXN];
void prep()
{
for(int i=;i<=MAXN;i++)
par[i]=i;
}
int fnd(int x)
{
if(par[x]==x)
return x;
return par[x]=fnd(par[x]);
}
void unite(int father,int son)
{
par[son]=fnd(father);
}
void dfs(int u)
{
for(int i=;i<=V;i++)
if(vis[i]&&que[u][i])
{
int fa=fnd(i);//fa 为u与i的LCA
cnt[fa]+=que[u][i];
}
vis[u]=;
for(int i=;i<G[u].size();i++)
{
int v=G[u][i];
dfs(v);
unite(u,v);
}
}
int indeg[MAXN];
int main()
{
while(scanf("%d",&V)!=EOF)
{
prep();
for(int i=;i<=V;i++) G[i].clear();
memset(que,,sizeof(que));
memset(vis,,sizeof(vis));
memset(cnt,,sizeof(cnt));
memset(indeg,,sizeof(indeg));
for(int i=;i<V;i++)
{
int u,t;
scanf("%d:(%d)",&u,&t);
while(t--)
{
int v;
scanf("%d",&v);
G[u].push_back(v);
indeg[v]++;
}
}
int Q;
scanf("%d",&Q);
while(Q--)
{
int u,v;
scanf(" (%d %d)",&u,&v);
que[u][v]++;
que[v][u]++;
}
for(int i=;i<=V;i++)
if(!indeg[i])//入度为0的点为根节点
{
dfs(i);
break;
}
for(int i=;i<=V;i++)
if(cnt[i]!=) printf("%d:%d\n",i,cnt[i]);
}
return ;
}
POJ(有向图求LCA)的更多相关文章
- POJ 1986:Distance Queries(倍增求LCA)
http://poj.org/problem?id=1986 题意:给出一棵n个点m条边的树,还有q个询问,求树上两点的距离. 思路:这次学了一下倍增算法求LCA.模板. dp[i][j]代表第i个点 ...
- 树上倍增求LCA及例题
先瞎扯几句 树上倍增的经典应用是求两个节点的LCA 当然它的作用不仅限于求LCA,还可以维护节点的很多信息 求LCA的方法除了倍增之外,还有树链剖分.离线tarjan ,这两种日后再讲(众人:其实是你 ...
- POJ 1330(LCA/倍增法模板)
链接:http://poj.org/problem?id=1330 题意:q次询问求两个点u,v的LCA 思路:LCA模板题,首先找一下树的根,然后dfs预处理求LCA(u,v) AC代码: #inc ...
- Tarjan算法离线 求 LCA(最近公共祖先)
本文是网络资料整理或部分转载或部分原创,参考文章如下: https://www.cnblogs.com/JVxie/p/4854719.html http://blog.csdn.net/ywcpig ...
- 树链剖分求LCA
树链剖分中各种数组的作用: siz[]数组,用来保存以x为根的子树节点个数 top[]数组,用来保存当前节点的所在链的顶端节点 son[]数组,用来保存重儿子 dep[]数组,用来保存当前节点的深度 ...
- 树上倍增求LCA(最近公共祖先)
前几天做faebdc学长出的模拟题,第三题最后要倍增来优化,在学长的讲解下,尝试的学习和编了一下倍增求LCA(我能说我其他方法也大会吗?..) 倍增求LCA: father[i][j]表示节点i往上跳 ...
- [算法]树上倍增求LCA
LCA指的是最近公共祖先(Least Common Ancestors),如下图所示: 4和5的LCA就是2 那怎么求呢?最粗暴的方法就是先dfs一次,处理出每个点的深度 然后把深度更深的那一个点(4 ...
- 【树链剖分】洛谷P3379 树链剖分求LCA
题目描述 如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先. 输入输出格式 输入格式: 第一行包含三个正整数N.M.S,分别表示树的结点个数.询问的个数和树根结点的序号. 接下来N-1行每 ...
- 【倍增】洛谷P3379 倍增求LCA
题目描述 如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先. 输入输出格式 输入格式: 第一行包含三个正整数N.M.S,分别表示树的结点个数.询问的个数和树根结点的序号. 接下来N-1行每 ...
随机推荐
- jquery 获取 outerHtml
在开发过程中,jQuery.html() 是获取当前节点下的html代码,并不包括当前节点本身的代码,然后我们有时候确须要.找遍jQuery api文档也没有不论什么方法能够拿到. 看到有的人通过pa ...
- 基于Apache POI 向xlsx写入数据
[0]写在前面 0.1) these codes are from 基于Apache POI 的向xlsx写入数据 0.2) this idea is from http://cwind.iteye. ...
- 数据结构与算法之枚举(穷举)法 C++实现
枚举法的本质就是从全部候选答案中去搜索正确的解,使用该算法须要满足两个条件: 1.能够先确定候选答案的数量. 2.候选答案的范围在求解之前必须是一个确定的集合. 枚举是最简单.最基础.也是最没效率的算 ...
- C# WinForm退出方法
1.this.Close(); 只是关闭当前窗口,若不是主窗体的话,是无法退出程序的,另外若有托管线程(非主线程),也无法干净地退出: 2.Application.Exit(); 强制所有消息中 ...
- Python 深入剖析SocketServer模块(一)(V2.7.11)
一.简介(翻译) 通用socket server 类 该模块尽力从各种不同的方面定义server: 对于socket-based servers: -- address family: ...
- ZOJ 3502 Contest <状态压缩 概率 DP>
链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3502 #include <iostream> #incl ...
- ArcGIS api for js OverviewMap(鹰眼/概览图)
说明.本篇博客中主要介绍 地图显示在某个div情况 1.运行效果 2.HTML <!DOCTYPE html> <html> <head> <meta htt ...
- css多余字符显示省略号
width:300px; white-space:nowrap; overflow:hidden; text-overflow:ellipsis; ;
- sort()函数到底是怎样进行数字排序的
很多人会用sort(),并不见得知道它具体是怎样给数字排序的.其实不知道也行,会用就可以,感兴趣的可以来看看. var numberArray = [2,4,1,3]; numberArray.sor ...
- 【题解】P2602[JZOI2010]数字计数
[题解][P2602ZJOI2010]数字计数 乍看此题,感觉直接从数字的位上面动手,感觉应该很容易. 但是仔细看数据范围,发现如果不利用计数原理,肯定会超时,考虑数码出现的特征: \(A000\)到 ...