Scrapyd部署
从github(https://github.com/scrapy/scrapyd)下载安装包
放到D:\python\Lib\site-packages\
解压压缩包:cd 到解压目录
python setup.py install
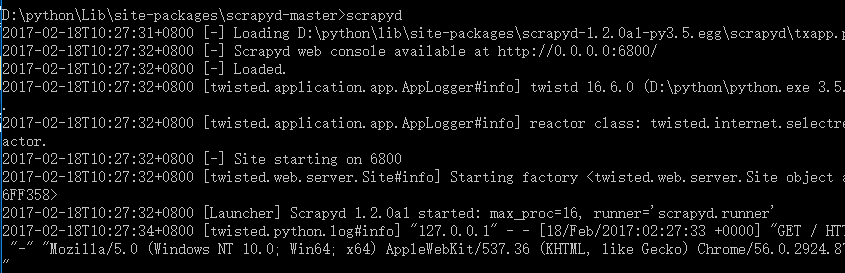
执行命令:Scrapyd;如下证明安装成功
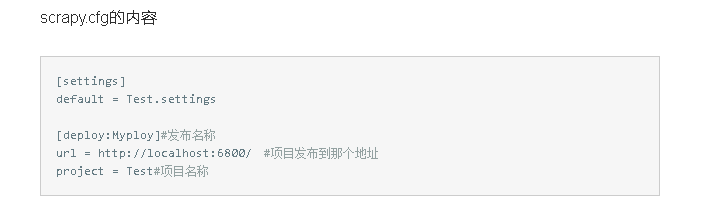
在项目中找到scrapy.cfg文件,编辑如下:
在scrapy.cfg所在目录中执行命令:
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置
报错:'scrapyd-deploy' 不是内部或外部命令,也不是可运行的程序 或批处理文件。在windows上使用scrapyd-client
安装后,并不能使用相应的命令'scrapyd-deploy'
需要在"C:\Python27\Scripts" 目录下 增加scrapyd-deploy.bat文件
内容填充为:
@echo off
"C:\python27\python.exe" "C:\python27\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
在scrapy.cfg所在目录中重新执行命令:
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置

现在只是将项目发布到目标地址,但是没有调度爬虫,调度爬虫需要用到curl命令,如下:
spd是自定义的:

curl http://localhost:6800/schedule.json -d project=testscrapy -d spider=spd
如果window下没有安装crul工具包,会报错:curl不是内部或外部命令,也不是可运行的程序 或批处理文件。
下载:http://curl.haxx.se/download.html;找到系统对应的版本;下载到本地并解压,找到curl.exe 所在路径配置到系统环境变量中;
再次输入:curl http://localhost:6800/schedule.json -d project=testscrapy -d spider=spd

参考:
http://www.jianshu.com/p/694a56b2199a
http://blog.wiseturtles.com/posts/scrapyd.html
http://blog.csdn.net/xxwang6276/article/details/45745181
Scrapyd部署的更多相关文章
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- 爬虫部署 --- scrapyd部署爬虫 + Gerapy 管理界面 scrapyd+gerapy部署流程
---------scrapyd部署爬虫---------------1.编写爬虫2.部署环境pip install scrapyd pip install scrapyd-client 启动scra ...
- scrapyd部署、使用Gerapy 分布式爬虫管理框架
Scrapyd部署爬虫项目 GitHub:https://github.com/scrapy/scrapyd API 文档:http://scrapyd.readthedocs.io/en/stabl ...
- 潭州课堂25班:Ph201805201 爬虫高级 第九课 scrapyd 部署 (课堂笔记)
c rapyd是 scrapy 的部署, 是官方提供的一个爬虫管理工具, 通过他可以非常方便的上传控制爬虫的运行, 安装 : pip install scapyd 他提供了一个json ,web, s ...
- scrapy 项目通过scrapyd部署
年前的时候采用scrapy 爬取了某网站的数据,当时只是通过crawl 来运行了爬虫,现在还想通过持续的爬取数据所以需要把爬虫部署起来,查了下文档可以采用scrapyd来部署scrapy项目,scra ...
- 1.scrapyd部署相关问题
部署scrapy爬虫项目到6800上 启动scrapyd 出现问题 1: scrapyd-deloy -l 未找到相关命令 scrapyd-deploy -l 可以看到当前部署的爬虫项目,但是当我输 ...
- 使用Scrapyd部署Scrapy爬虫到远程服务器上
1.准备好爬虫程序 2.修改项目配置 找到项目配置文件scrapy.cnf,将里面注释掉的url解开来 本代码需要连接数据库,因此需要修改对应的数据库配置 其实就是将里面的数据库地址进行修改,变成远程 ...
随机推荐
- eclipse 的SVN安装
打开eclipse -> Help ->Install New Software选项, 点击Add按钮 根据需要,添加自己需要的版本svn控制器的版本,填写name和url,点击ok. ...
- 卸载重安firefox
把firefox完全卸载掉重装: 查看安装的firefox版本: dpkg --get-selections |grep firefox 根据命令结果卸载重装 比如: $ dpkg --get-sel ...
- VirtualBox 與 Vmware 差異
VirtualBox 4.3.36_Ubuntu r105129 與 VMware® Workstation 12 Player 12.5.2 build-4638234, 分別在各自的 Ubunt ...
- Android系统默认输入法的修改为搜狗输入法
1. frameworks\base\packages\SettingsProvider\res\values\defaults.xml 文件中修改默认输入法为搜狗输入法 <stringnam ...
- Springboot 集成 Thymeleaf 及常见错误
Thymeleaf模板引擎是springboot中默认配置,与freemarker相似,可以完全取代jsp,在springboot中,它的默认路径是src/main/resources/templat ...
- javascript好文---深入理解定位父级offsetParent及偏移大小
前面的话 偏移量(offset dimension)是javascript中的一个重要的概念.涉及到偏移量的主要是offsetLeft.offsetTop.offsetHeight.offsetWid ...
- 在CentOS上安装 MongoDB
安装是在线安装方式,因此必须先保证能正常上网. 安装mongodb,官方的安装文档,是在线安装方式: https://docs.mongodb.com/manual/tutorial/install- ...
- 10.【nuxt起步】-引用mintui
这时候我们完成了list.vue,但是怎么返回index.vue,这时候需要这个头部返回 1.我们使用现成的minu-ui,eleme的开源移动端 ,参考 https://www.cnblogs.co ...
- Solaris Samba服务器与DNS服务
用于文件传输的协议,类似于ftp,ssh,只是它比其他两个好用. Samba协议 NetBIOS :一种编程接口. SMB:server message block .主要作为Microsoft网络通 ...
- Java如何Attachment源码
该文章教你如何在Eclipse中Attachment源码,学到了不少东西. http://jingyan.baidu.com/article/1709ad80b107f64635c4f040.html ...