word2vec改进之Negative Sampling
训练网络时往往会对全部的神经元参数进行微调,从而让训练结果更加准确。但在这个网络中,训练参数很多,每次微调上百万的数据是很浪费计算资源的。那么Negative Sampling方法可以通过每次调整很小的一部分权重参数,从而代替全部参数微调的庞大计算量。
词典D中的词在语料C中出现的次数有高有低,对于那些高频词,我们希望它被选为负样本的概率比较大,对于那些低频词,我们希望它被选中的概率比较小,这是我们对于负采样过程的一个大致要求,本质上可以认为是一个带权采样的问题。
一、基于Negative Sampling的CBOW模型
输入:基于CBOW的语料训练样本,词向量的维度大小Mcount,CBOW的上下文大小2c,步长η, 负采样的个数neg
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:

d) 如果梯度收敛,则结束梯度迭代,否则回到步骤3继续迭代。
二、基于Negative Sampling的Skip-Gram模型
输入:基于Skip-Gram的语料训练样本,词向量的维度大小Mcount,Skip-Gram的上下文大小2c,步长η, , 负采样的个数neg。
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:
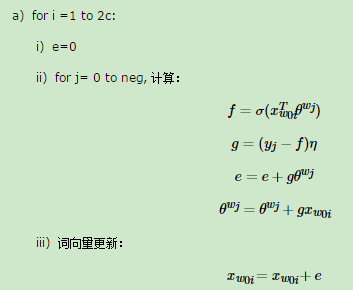
b)如果梯度收敛,则结束梯度迭代,算法结束,否则回到步骤a继续迭代。
参考内容:
https://www.cnblogs.com/pinard/p/7249903.html
word2vec改进之Negative Sampling的更多相关文章
- word2vec原理(三) 基于Negative Sampling的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec 中的数学原理具体解释(五)基于 Negative Sampling 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注. 因为 word2vec 的作者 Tomas ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- Notes on Noise Contrastive Estimation and Negative Sampling
Notes on Noise Contrastive Estimation and Negative Sampling ## 生成负样本 在常见的关系抽取应用中,我们经常需要生成负样本来训练一个好的系 ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- [DeeplearningAI笔记]序列模型2.7负采样Negative sampling
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 负采样 Negative sampling Mikolov T, Sutskever I, Chen K, et a ...
- word2vec改进之Hierarchical Softmax
首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点: 1. 对于从输入层到隐藏层的映射,没有采取神经网 ...
- 【计算语言学实验】基于 Skip-Gram with Negative Sampling (SGNS) 的汉语词向量学习和评估
一.概述 训练语料来源:维基媒体 https://dumps.wikimedia.org/backup-index.html 汉语数据 用word2vec训练词向量,并用所学得的词向量,计算 pku_ ...
随机推荐
- Linux struct itimerval使用方法
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/hbuxiaofei/article/details/35569229 先看一段代码 #include ...
- SQL JOIN--初级篇
写在前面的话: 以下是最简单的join原理,为后面的大数据分布式join做概念复习和知识铺垫: 有时为了得到完整的结果,我们需要从两个或更多的表中获取结果.我们就需要执行 join. JOIN: 如果 ...
- Hive与impala的对比测试实验
前面几篇随笔记录了我安装环境的一些笔记,环境ok以后,自然要看看impala到底性能如何,拿他来hive做做对比: 前面hive章节中,已经建立了一张名叫chengyeliang的table,该表的结 ...
- UIView封装动画--iOS利用系统提供方法来做关键帧动画
iOS利用系统提供方法来做关键帧动画 ios7以后才有用. /*关键帧动画 options:UIViewKeyframeAnimationOptions类型 */ [UIView animateKey ...
- raise 与 raise ... from 的区别
起步 Python 的 raise 和 raise from 之间的区别是什么? try: print(1 / 0) except Exception as exc: raise RuntimeErr ...
- 电脑设备对于IT人员,犹如武器对于士兵
本人做了多年Softwarer,写些感受. 比我们早的老一代程序员更是用自己的健康总结了一些经验. 先说关于健康方面: 程序员要长期坐着,这对健康损害很大,颈椎腰椎,心肺能力都会衰减.以前只是听说,自 ...
- BluetoothLE-Multi-Library
github地址:https://github.com/qindachang/BluetoothLE-Multi-Library BluetoothLE-Multi-Library 一个能够连接多台蓝 ...
- hdu-5748 Bellovin(LIS)
题目链接: Bellovin Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- SPOJ:Red John is Back(DP)
Red John has committed another murder. But this time, he doesn't leave a red smiley behind. What he ...
- BZOJ_1044_[HAOI2008]木棍分割_二分答案+DP+单调队列
BZOJ_1044_[HAOI2008]木棍分割_二分答案+DP Description 有n根木棍, 第i根木棍的长度为Li,n根木棍依次连结了一起, 总共有n-1个连接处. 现在允许你最多砍断m个 ...