Spark环境搭建(五)-----------Spark生态圈概述与Hadoop对比
Spark:快速的通用的分布式计算框架
概述和特点:
1) Speed,(开发和执行)速度快。基于内存的计算;DAG(有向无环图)的计算引擎;基于线程模型;
2)Easy of use,易用 。 多语言(Java,python,scala,R); 多种计算API可调用;可在交互式模式下运行;
3)Generality 通用。可以一站式解决多个不同场景的应用业务
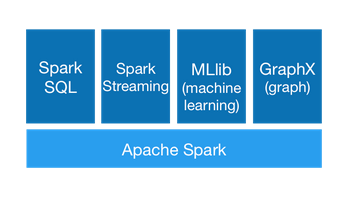
Spark Streaming :用来做流处理
MLlib : 用于机器学习
GraphX:用来做图形计算的
4) Runs Everywhere :
(1)可以运行在Hadoop的yarn,Mesos,standalone(Sprk自带的)这些资源管理和调度的程序之上
(2) 可以连接包括HDFS,Cassandra,HBase,S3这些数据源

产生背景:
1)MapReduce 局限性
(1)代码繁琐(官网有WordOCunt案例)
(2)效率低下:
a) 有结果写入磁盘,降低效率;
b) 通过进程模型,销毁创建效率低
(3)只能支持map和reduce方法
(4) 不适合迭代多次,交互式,流水的处理
2) 框架的多样化
(1)批处理(离线):MapReduce,Hive,Pig
(2)流式处理(实时):Storm,Jstorm
(3)交互式计算 :Impala
综上: 框架的多样化导致生产时所需要的框架繁多,学习运维成本较高,那么有没有一种框架,
既能执行效率高,学习成本低,还能支持批处理和流式处理与交互计算呢?
结论:Spark诞生
Spark与Hadoop对比:
Hadoop生态系统
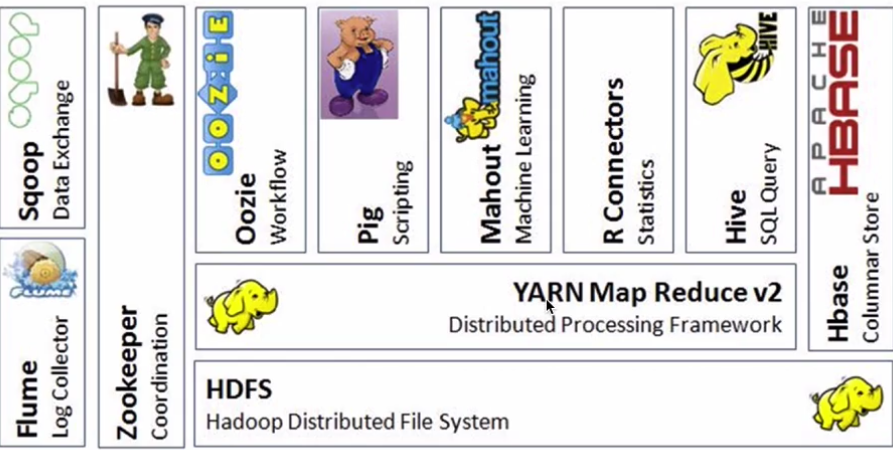
Hive:数据仓库
R:数据分析
Mahout:机器学习库
pig:脚本语言,跟Hive类似
Oozie:工作流引擎,管理作业执行顺序
Zookeeper:用户无感知,主节点挂掉选择从节点作为主的
Flume:日志收集框架
Sqoop:数据交换框架,例如:关系型数据库与HDFS之间的数据交换
Hbase : 海量数据中的查询,相当于分布式文件系统中的数据库
BDAS:Berkeley Data Analytics Stack(伯克利数据分析平台)
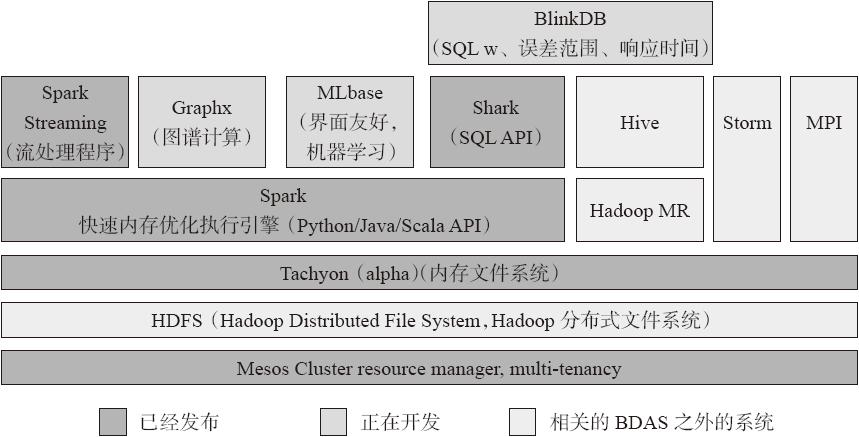
Spark与Hadoop生态圈对比
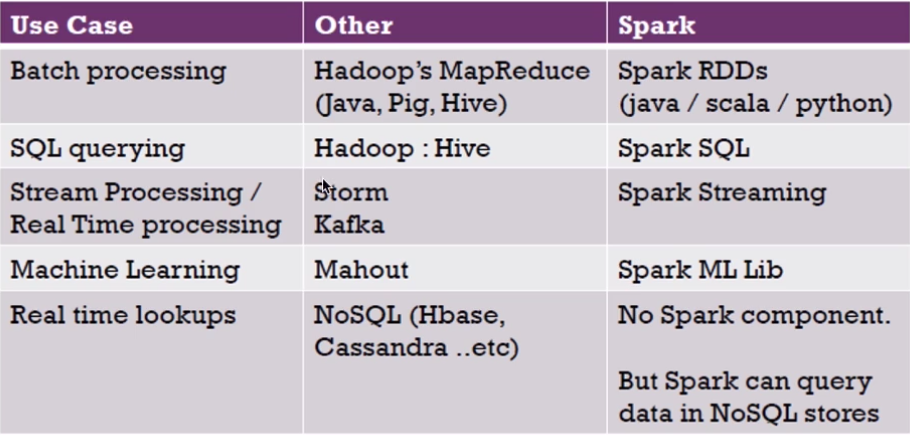
注意:在对实时的查询来说,Spark只是一个快速的分布式计算框架,所以没有存储的框架,但是可以连接多个存储的数据源
Hadoop与Spark对比
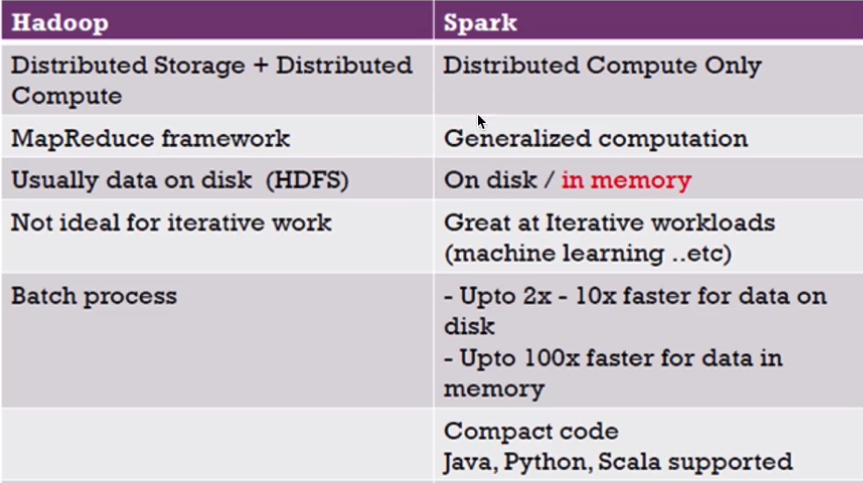
MapReduce与Spark对比:
MapReduce:若进行多次计算,MP则需要将上一次执行结果写入到磁盘,叫做数据落地
Spark:直接将存储在内存中的结果拿来使用,没有数据落地

Spark与Hadoop的协作性
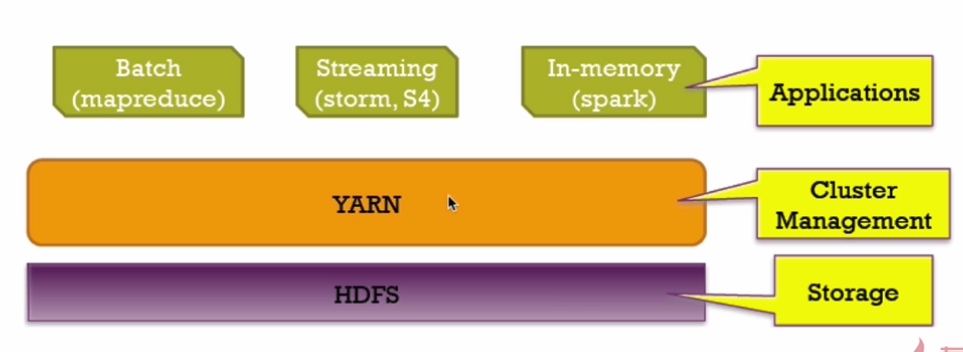
Spark概述和与Hadoop对比
Spark环境搭建(五)-----------Spark生态圈概述与Hadoop对比的更多相关文章
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Spark环境搭建(上)——基础环境搭建
Spark摘说 Spark的环境搭建涉及三个部分,一是linux系统基础环境搭建,二是Hadoop集群安装,三是Spark集群安装.在这里,主要介绍Spark在Centos系统上的准备工作--linu ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 4.Spark环境搭建和使用方法
一.安装Spark spark和Hadoop可以部署在一起,相互协作,由Hadoop的HDFS.HBase等组件复制数据的存储和管理,由Spark负责数据的计算. Linux:CentOS Linux ...
- 学习Spark——环境搭建(Mac版)
大数据情结 还记得上次跳槽期间,与很多猎头都有聊过,其中有一个猎头告诉我,整个IT跳槽都比较频繁,但是相对来说,做大数据的比较"懒"一些,不太愿意动.后来在一篇文中中也证实了这一观 ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
随机推荐
- 技术栈(technology stack)
technology stack 技术栈: 产品实现上依赖的软件基础组件, 包括 1. 系统 2. 中间件 3. 数据库 4. 应用软件 5. 开发语言 6. 框架 https://en.wikipe ...
- vue父子组件生命周期执行顺序
之前写了vue的生命周期,本以为明白了vue实例在创建到显示在页面上以及销毁等一系列过程,以及各个生命周期的特点.然而今天被问到父子组件生命周期执行顺序的时候一头雾水,根本不知道怎么回事.然后写了一段 ...
- vuex概念详解
阅读vuex官网以后用自己的话概括起来就是:vuex是vue配套的公共数据管理工具,它可以把一些共享的数据,保存到vuex中,方便整个程序中的任何组件直接获取或修改我们的公共数据. vuex是为了保存 ...
- zhifubao
使用Git的一个优势便是 我们可以自由的切换到其他分支,而不影响主分支的正常开发,每个分支上都是一份完成的可执行代码那么如何创建分支呢, 创建分支有几种方法, 本地分支和远程分支的差别,意义各是什么,
- Python爬虫从入门到进阶(3)之requests的使用
快速上手(官网地址:http://www.python-requests.org/en/master/user/quickstart/) 发送请求 首先导入Requests模块 import requ ...
- SpringBoot文件的上传与下载
⒈文件实体类 package cn.coreqi.security.entities; public class FileInfo { private String path; public File ...
- django+uwsgi+nginx的部署
1.下载与项目对应的django版本pip3 install django==1.11.16 -i https://pypi.douban.com/simple/2.用django内置的wsgi模块测 ...
- Unity AssetBundle的生成、加载和热更新
当前使用的是unity2018.2.6版本. 生成AssetBundle 这个版本生成AssetBundle有两种方式,一种是在资源的Inspector面板下边配置AssetBundle名称,然后调用 ...
- git 随笔(随时更新)
w:跳到下个词前面, e:跳到下个词后面,b是跳到上一个单词前面. v:选择 ,可以批量操作 q + a: 录制宏, a 是存录制地方,q录制完毕. @a :执行录制操作. @a 前面➕数字:例如1 ...
- php 常用的知识点归集(下)
24.静态属性与静态方法在类中的使用 需求:在玩CS的时候不停有伙伴加入,那么现在想知道共有多少人在玩,这个时候就可能用静态变量的方法来处理 利用原有的全局变量的方法来解决以上的问题 <?php ...