HashMap实现分析
HashMap最基本的实现思想如下图所示,使用数组加链表的组合形式来完成数据的存储。
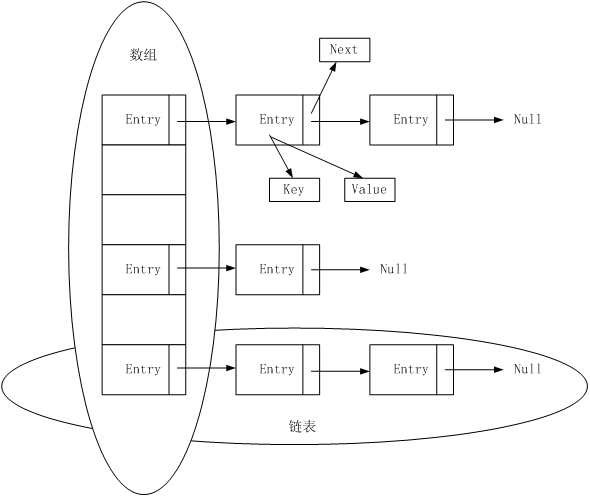
Entry在数组中的位置是由key的hashcode决定的。
向一个数组长度为16,负载因子为0.75的HashMap中插入key的hashcode为26、126、1、337、184、12、31、111的对象后的结构为:
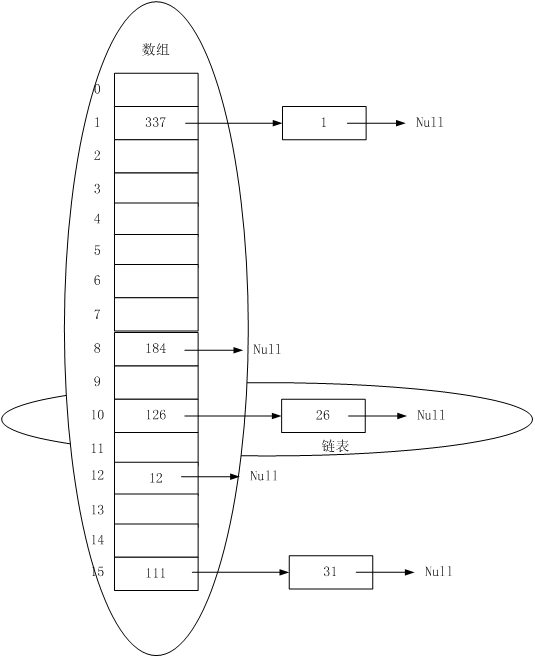
1%16 =1 ,337%16 =1。数组中存储的是最后插入的数据,并用next指针指向之前已经存在的数据。
HashMap查找数据的依据是:现根据key的hashcode查找位于数组中的位置,在使用next依次遍历链表中的元素,调用key的equals方法,如果key equals Entry对应的key,则Entry中的value就是所找的值。所以使用对象作为HashMap的key时,重写hashcode方法的同时需要重写equals方法。
可以参考HashMap的get方法的代码,就会更清楚上面的描述:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
HashMap中的Hash算法是经过了优化之后的,可以看到
int hash = hash(key.hashCode());对hashcode又进行了二次散列操作,这样做的目的是使得计算出的hash比hashcode在数组上的分布将更为均匀,HashMap的空间利用率也越高。
HashMap对hashcode的二次散列如下:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
HashMap在使用hash计算位于数组中的位置时也不是简单的%操作,而是用的indexFor来完成的。%操作比较耗资源,当HashMap中数组的length是2 的n次方时,h& (length-1)运算等价于h%length,但是&比%具有更高的效率。
static int indexFor(int h, int length) {
return h & (length-1);
}
理解了二次散列和indexFor,上面的代码就比较的好理解了。table数组就是图中的Entry数组。
HashMap可以存储key为null的Entry,该Entry将被放在数组指标为0的位置。
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中。最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是rehash。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这一策略在源码中的实现是通过modCount域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。
在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map:
modCount的修饰符为volatile,保证线程之间修改的可见性。
HashSet的底层也是用HashMap来实现的,使用HashMap的key来进行存储与散列。
HashMap实现分析的更多相关文章
- HashMap底层分析
以下基于 JDK1.7 分析. 如图所示,HashMap 底层是基于数组和链表实现的.其中有两个重要的参数: 容量 负载因子 容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 si ...
- HashMap的分析(转)
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- 面试必问---HashMap原理分析
一.HashMap的原理 众所周知,HashMap是用来存储Key-Value键值对的一种集合,这个键值对也叫做Entry,而每个Entry都是存储在数组当中,因此这个数组就是HashMap的主干.H ...
- HashMap 底层分析
以下基于 JDK1.7 分析 如图所示,HashMap底层是基于数组和链表实现的,其中有两个重要的参数: ---容量 ---负载因子 容量的默认大小是16,负载因子是0.75,当HashMap的siz ...
- ConcurrentHashMap 并发HashMap原理分析
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁.如图 左边便是Hashtable的实现方式---锁整个hash表:而右边则是Concurrent ...
- Java基础之HashMap原理分析(put、get、resize)
在分析HashMap之前,先看下图,理解一下HashMap的结构 我手画了一个图,简单描述一下HashMap的结构,数组+链表构成一个HashMap,当我们调用put方法的时候增加一个新的 key-v ...
- 聊聊经典数据结构HashMap,逐行分析每一个关键点
本文基于JDK-8u261源码分析 本文原创首发于 奇客时间(qiketime) 1 简介 HashMap是一个使用非常频繁的键值对形式的工具类,其使用起来十分方便.但是需要注意的是,HashMap不 ...
- 2021超详细的HashMap原理分析,面试官就喜欢问这个!
一.散列表结构 散列表结构就是数组+链表的结构 二.什么是哈希? Hash也称散列.哈希,对应的英文单词Hash,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出 这个映射的规则就是对 ...
- HashMap原理分析
HashMap 实现Map.Cloneable.Serializable接口,继承AbstractMap基类. HashMap map = new HashMap(); 实例化一个HashMap,在构 ...
随机推荐
- [bzoj4240] 有趣的家庭菜园
还是膜网上题解QAQ 从低到高考虑,这样就不会影响后挪的草了. 每次把草贪心地挪到代价较小的一边.位置为i的草,花费为min( 1..i-1中更高的草的数目,i+1..n中更高的草的数目 ) 因为更小 ...
- myEclipse配置SVN
方法三:直接解压 下载SVN插件:site-1.6.10.zip 解压后将其全部文件拷贝至:D:\Program Files\Genuitec\MyEclipse 8.5\drop ...
- JS验证两次输入密码是否相同
js中 <script>function check(){ with(document.all){if(input1.value!=input2.value){alert("fa ...
- Vue.js实现一个SPA登录页面的过程
技术栈 vue.js 主框架 vuex 状态管理 vue-router 路由管理 一般过程 在一般的登录过程中,一种前端方案是: 检查状态:进入页面时或者路由变化时检查是否有登录状态(保存在cooki ...
- Linux下安装PostgreSQL 转载linux社区
Linux下安装PostgreSQL [日期:2016-12-25] 来源:Linux社区 作者:xiaojian [字体:大 中 小] 在Linux下安装PostgreSQL有二进制格式安装和 ...
- sizeof(extern类型数组)
error: #70: incomplete type is not allowed 用sizeof计算数组大小,编译器提示不允许使用不完整的类型.在keil上编译直接报错,拿到vs2010上编译可 ...
- VisualSVN Server启动错误(0x8007042a)
SVN Server启动错误(0x8007042a) 原因是SVN Server端口被占用 打开VisualSVN Server, 菜单->操作->Properties->Net ...
- Bootstrap中data-src无法显示图片,但是src可以
在学习bootstrap时,书中的源码是用的data-src来定义图像位置,但是我在使用的时候无法显示图片:data-src可以在img标签中使用来显示图片吗?我使用src可以,而是用data-src ...
- Lytro 光场相机重对焦C++实现以及CUDA实现
前面有几篇博客主要介绍了光场和光场相机相关知识,以及重对焦效果和多视角效果的展示.算是自己学习光场过程的一种总结. 这次贴上自己用OpenCV/C++编写的重对焦算法实现(包含CPU版和CUDA GP ...
- UE4/Unity3D中同时捕获多高清摄像头的高效插件
本文主要讲实现过程的一些坑. 先说下要实现的目标,主要功能在UE4/Unity中都要用,能同时捕获多个摄像头,并且捕获的图片要达到1080p25桢上,并且需要经过复杂的图片处理后丢给UE4/Unity ...