[CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #042eee }
span.s1 { }
span.s2 { text-decoration: underline }
Is object localization for free? –Weakly-supervised learning with convolutional neural networks. Maxime Oquab, Leon Bottou, Ivan Laptev, Josef Sivic
http://www.di.ens.fr/~josef/publications/Oquab15.pdf
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 15.0px "Helvetica Neue"; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 }
li.li2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 }
span.s1 { }
span.s2 { background-color: #fefa00 }
ul.ul1 { list-style-type: disc }
ul.ul2 { list-style-type: circle }
亮点
- 一个好名字给了让读者开始阅读的理由
- global max pooling over sliding window的定位方法值得借鉴
方法
本文的目标是:设计一个弱监督分类网络,注意本文的目标主要是提升分类。因为是2015年的文章,方法比较简单原始。
Following three modifications to a classification network.
- Treat the fully connected layers as convolutions, which allows us to deal with nearly arbitrary-sized images as input.
- The aim is to apply the network to bigger images in a sliding window manner thus extending its output to n×m× K, where n and m denote the number of sliding window positions in the x- and y- direction in the image, respectively.
- 3xhxw —> convs —> kxmxn (k: number of classes)
- Explicitly search for the highest scoring object position in the image by adding a single global max-pooling layer at the output.
- kxmxn —> kx1x1
- The max-pooling operation hypothesizes the location of the object in the image at the position with the maximum score
- Use a cost function that can explicitly model multiple objects present in the image.
因为图中可能有很多物体,所以多类的分类loss不适用。作者把这个任务视为多个二分类问题,loss function和分类的分数如下
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333; min-height: 15.0px }
p.p3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 15.0px "Helvetica Neue"; color: #323333 }
li.li1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 }
span.s1 { }
ul.ul1 { list-style-type: disc }
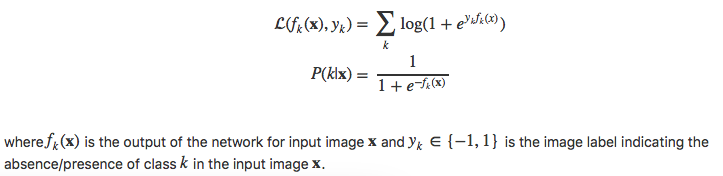
training
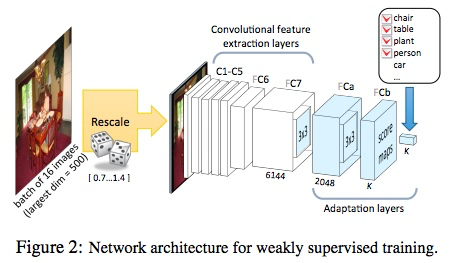
muti-scale test
实验
classification
- mAP on VOC 2012 test: +3.1% compared with [56]
- mAP on VOC 2012 test: +7.6% compared with kx1x1 output and single scale training
- mAP on VOC: +2.6% compared with RCNN
- mAP on COCO 62.8%
Localisation
- Metric: if the maximal response across scales falls within the ground truth bounding box of an object of the same class within 18 pixels tolerance, we label the predicted location as correct. If not, then we count the response as a false positive (it hit the background), and we also increment the false negative count (no object was found).
- metric on VOC 2012 val: -0.3% compared with RCNN
- mAP on COCO 41.2%
缺点
- 定位评测的metric不具有权威性
- max pooling改为average pooling会不会对于多个instance的情况更好一些
[CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记的更多相关文章
- Coursera, Deep Learning 4, Convolutional Neural Networks, week3, Object detection
学习目标 Understand the challenges of Object Localization, Object Detection and Landmark Finding Underst ...
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- [CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee } p. ...
- A brief introduction to weakly supervised learning(简要介绍弱监督学习)
by 南大周志华 摘要 监督学习技术通过学习大量训练数据来构建预测模型,其中每个训练样本都有其对应的真值输出.尽管现有的技术已经取得了巨大的成功,但值得注意的是,由于数据标注过程的高成本,很多任务很难 ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 课程四(Convolutional Neural Networks),第三 周(Object detection) —— 0.Learning Goals
Learning Goals: Understand the challenges of Object Localization, Object Detection and Landmark Find ...
- [C4W3] Convolutional Neural Networks - Object detection
第三周 目标检测(Object detection) 目标定位(Object localization) 大家好,欢迎回来,这一周我们学习的主要内容是对象检测,它是计算机视觉领域中一个新兴的应用方向, ...
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
UC Berkeley的Deepak Pathak 使用了一个具有图像级别标记的训练数据来做弱监督学习.训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息.该文章的方法将imag ...
随机推荐
- 【算法导论】图的广度优先搜索遍历(BFS)
图的存储方法:邻接矩阵.邻接表 例如:有一个图如下所示(该图也作为程序的实例): 则上图用邻接矩阵可以表示为: 用邻接表可以表示如下: 邻接矩阵可以很容易的用二维数组表示,下面主要看看怎样构成邻接表: ...
- git使用详解
1. Git概念 1.1. Git库中由三部分组成 Git 仓库就是那个.git 目录,其中存放的是我们所提交的文档索引内容,Git 可基于文档索引内容对其所管理的文档进行内容追踪,从而实现文档的版本 ...
- SpriteBuilder中关于大量CCB文件的数字命名建议
开发者总是频繁的填充文件名字使用额外的0,以此来对抗长久以来的长痘:数字排序.如果你觉得在数字名字前添加额外的0是一个好主意,比如说Level0001,因为可能你会创建数以千记的关卡--请不要这样做! ...
- 测试AtomicInteger与普通int值在多线程下的递增操作
日期: 2014年6月10日 作者: 铁锚 Java针对多线程下的数值安全计数器设计了一些类,这些类叫做原子类,其中一部分如下: java.util.concurrent.atomic.AtomicB ...
- 不错的网络协议栈测试工具 — Packetdrill
Packetdrill - A network stack testing tool developed by Google. 项目:https://code.google.com/p/packetd ...
- 基于MT6752/32平台 Android L版本驱动移植步骤
基于MT6752/32平台 Android L版本驱动移植步骤 根据MK官网所述,在Android L 版本上Turnkey ABS 架构将会phase out,而Mediatek Turnkey架构 ...
- HashMap是无序的
一. 说明 HashMap是基于哈希表Map的实现.设计初衷主要是为了解决键值(key-value)对应关联的,HashMap的优势是可以很快的根据键(key)找到该键对应的值(value),但是我们 ...
- 【Android 应用开发】对Android体系结构的理解--后续会补充
1.最底层_硬件 任何Android设备最底层的硬件包括 显示屏, wifi ,存储设备 等. Android最底层的硬件会根据需要进行裁剪,选择自己需要的硬件. 2.Linux内核层 该层主要对硬件 ...
- LeetCode(61)-Valid Palindrome
题目: Given a string, determine if it is a palindrome, considering only alphanumeric characters and ig ...
- obj-c编程10:Foundation库中类的使用(5)[时间对象]
隔了好久才有了这新的一篇,还是无奈的时间啊!so这次我们就着重谈谈它喽. F库中有很多时间相关的类,比如NSDate,NSTimeInterval,NSTimeZone,NSDateComponent ...