[大数据]-Fscrawler导入文件(txt,html,pdf,worf...)到Elasticsearch5.3.1并配置同义词过滤
fscrawler是ES的一个文件导入插件,只需要简单的配置就可以实现将本地文件系统的文件导入到ES中进行检索,同时支持丰富的文件格式(txt.pdf,html,word...)等等。下面详细介绍下fscrawler是如何工作和配置的。
一、fscrawler的简单使用:
1、下载: wget https://repo1.maven.org/maven2/fr/pilato/elasticsearch/crawler/fscrawler/2.2/fscrawler-2.2.zip
2、解压: unzip fscrawler-2.2.zip 目录如下:bin下两个脚本,lib下全部是jar包。
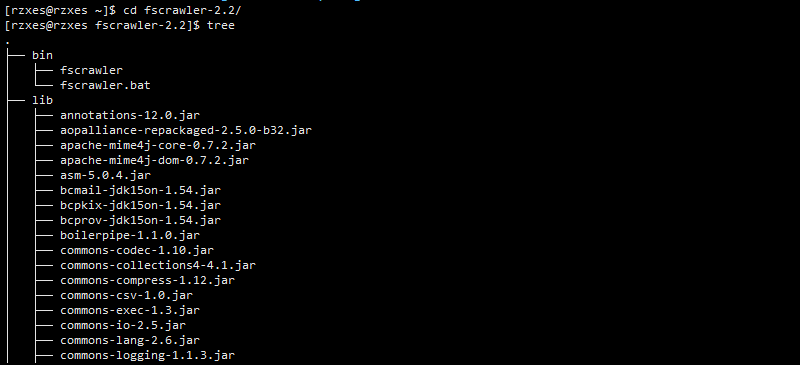
3、启动: bin/fscrawler job_name job_name需要自己设定,第一次启动这个job会创建一个相关的_setting.json用来配置文件和es相关的信息。如下:

- 编辑这个文件: vim ~/.fscrawler/job_1/_settting.json 修改如下:
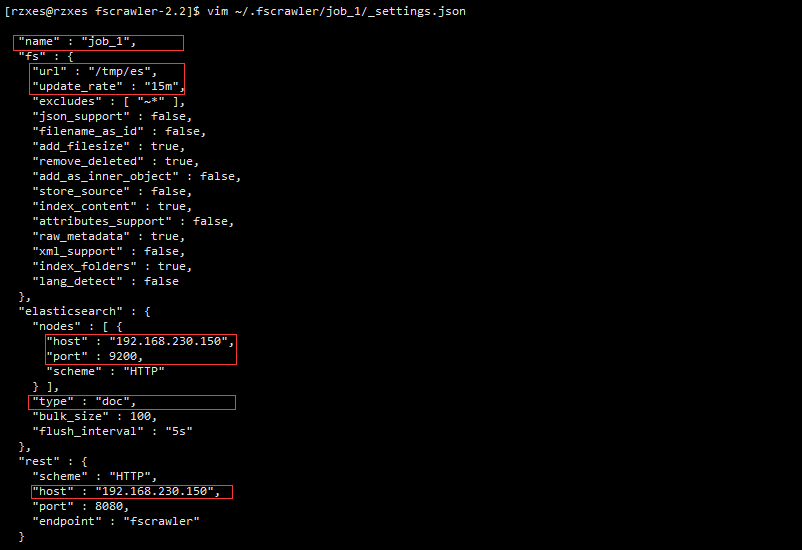
name表示的是一个job的name同时也是ES数据的的index,URL:代表需要导入的文件所在的文件夹。update_rate:表示多久刷新一次,host:连接es的IP地址和端口号。type:代表的就是ES的type。改完之后保存就可以运行,fs就会将数据导入了。
- 导入数据(会开启一个线程,根据设定的时间进行数据刷新,我们修改文件ES也能得到新的数据):bin/fscrawler job_name
二、fscrawler配置IK分词器和同义词过滤:
- 初始化一个job后系统会生成三个配置文件:doc.json,folder.json,_setting.json(1,2,5代表ES的版本号,我们是5.x版本就修改5文件夹下的配置文件。)这三个文件用来创建index,mapping。

- 配置IK分词首先在_default/5/_setting.json中配置analysis:删掉原有的配置文件,添加如下内容:
{
"settings": {
"analysis": {
"analyzer": {
"by_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": [
"by_tfr",
"by_sfr"
],
"char_filter": [
"by_cfr"
]
},
"by_max_word": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": [
"by_tfr",
"by_sfr"
],
"char_filter": [
"by_cfr"
]
}
},
"filter": {
"by_tfr": {
"type": "stop",
"stopwords": [
" "
]
},
"by_sfr": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt"
}
},
"char_filter": {
"by_cfr": {
"type": "mapping",
"mappings": [
"| => |"
]
}
}
}
}
}跟前面几篇博客中提到的自定义分词器创建同义词过滤一模一样,里面的filter可以选择删除,保留必要的部分,这样我们自定义了两种分词器:by_smart,by_max_word.
- 修改_default/5/doc.json:删除掉所有字段的分词器;analyzer:"xxx",因为在这里只有一个字段需要分词那就是content(文件的内容),给content节点添加加分词器。如下:
"content" : {
"type" : "text",
"analyzer":"by_max_word" #添加此行。。。
},- 配置就完成了,同样的再次启动job: bin/fscrawler job_name
- 访问9100:可以看到index已经创建好,如下图:

- 同义词查询:我在同义词中配置了西红柿和番茄,在/tmp/es文件夹下中添加了一个包含西红柿和番茄的文件,9100端口用以下语句查询:
{
"query": {
"match": {
"content": "番茄"
}
},
"highlight": {
"pre_tags": [
"<tag1>",
"<tag2>"
],
"post_tags": [
"</tag1>",
"</tag2>"
],
"fields": {
"content": {}
}
}
}结果如下:
{
"hits": [
{
"_index": "jb_8",
"_type": "doc",
"_id": "3a15a979b4684d8a5d86136257888d73",
"_score": 0.49273878,
"_source": {
"content": "我爱吃西红柿鸡蛋面。还喜欢番茄炒蛋饭",
"meta": {
"raw": {
"X-Parsed-By": "org.apache.tika.parser.DefaultParser",
"Content-Encoding": "UTF-8",
"Content-Type": "text/plain;charset=UTF-8"
}
},
"file": {
"extension": "txt",
"content_type": "text/plain;charset=UTF-8",
"last_modified": "2017-05-24T10: 22: 31",
"indexing_date": "2017-05-25T14: 08: 10.881",
"filesize": 55,
"filename": "sy.txt",
"url": "file: ///tmp/es/sy.txt"
},
"path": {
"encoded": "824b64ab42d4b63cda6e747e2b80e5",
"root": "824b64ab42d4b63cda6e747e2b80e5",
"virtual": "/",
"real": "/tmp/es/sy.txt"
}
},
"highlight": {
"content": [
"我爱吃<tag1>西红柿</tag1>鸡蛋面。还喜欢<tag1>番茄</tag1>炒蛋饭"
]
}
}
]
}完整的IK分词同义词过滤就配置完成了。
- 如下图是txt,html格式,其他格式亲测可用,但是文件名中文会乱码。
注意:
要选择fs2.2的版本,2.1的版本在5.3.1的ES上连接失败。
[大数据]-Fscrawler导入文件(txt,html,pdf,worf...)到Elasticsearch5.3.1并配置同义词过滤的更多相关文章
- [大数据]-Logstash-5.3.1的安装导入数据到Elasticsearch5.3.1并配置同义词过滤
阅读此文请先阅读上文:[大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置,前面介绍了ES,Kibana5.3.1的安装配置,以及IK分词的安装和同义词设置,这里主要记录L ...
- MYSQL数据库导入大数据量sql文件失败的解决方案
1.在讨论这个问题之前首先介绍一下什么是"大数据量sql文件". 导出sql文件.选择数据库-----右击选择"转储SQL文件"-----选择"结构和 ...
- POI实现大数据EXCLE导入导出,解决内存溢出问题
使用POI能够导出大数据保证内存不溢出的一个重要原因是SXSSFWorkbook生成的EXCEL为2007版本,修改EXCEL2007文件后缀为ZIP打开可以看到,每一个Sheet都是一个xml文件, ...
- .net core利用MySqlBulkLoader大数据批量导入MySQL
最近用core写了一个数据迁移小工具,从SQLServer读取数据,加工后导入MySQL,由于数据量太过庞大,数据表都过百万,常用的dapper已经无法满足.三大数据库都有自己的大数据批量导入数据的方 ...
- Mysql 大数据量导入程序
Mysql 大数据量导入程序<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" ...
- 学习推荐《零起点Python大数据与量化交易》中文PDF+源代码
学习量化交易推荐学习国内关于Python大数据与量化交易的原创图书<零起点Python大数据与量化交易>. 配合zwPython开发平台和zwQuant开源量化软件学习,是一套完整的大数据 ...
- [大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world
[大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world 原文链接:http://www.cnblogs.com/blog5277/ ...
- R—读取数据(导入csv,txt,excel文件)
导入CSV.TXT文件 read.table函数:read.table函数以数据框的格式读入数据,所以适合读取混合模式的数据,但是要求每列的数据数据类型相同. read.table读取数据非常方便,通 ...
- 分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节
1:MSSQL SQL语法篇: BULK INSERT [ database_name . [ schema_name ] . | schema_name . ] [ table_name | vie ...
随机推荐
- 感谢Thunder
感谢Thunder团队中的每一位成员. 组长王航认真负责,是一个合格优秀的领导者与伙伴,老师布置的任务都会及时分配给每个人,对待每一项任务都认真严谨负责,了解每个成员的优势及强项. 成员李传康.宋雨. ...
- 必应词典手机版(IOS版)与有道词典(IOS版)之软件分析【功能篇】【用户体验篇】
1.序言: 随着手机功能的不断更新和推广,手机应用市场的竞争变得愈发激烈.这次我们选择必应词典和有道词典的苹果客户端作对比,进一步分析这两款词典的客户端在功能和用户体验方面的利弊.这次测评的主要评测人 ...
- BugPhobia开发篇章:Scurm Meeting-更新至0x02
0x01 :目录与摘要 If you weeped for the missing sunset, you would miss all the shining stars 索引 提纲 整理与更新记录 ...
- 《Java学习笔记JDK8》学习总结
chapter 6 继承与多态 6.1何谓继承 1.继承的定义:继承就是避免多个类间重复定义共同行为. 2.总结:教材中通过设计一款RPG游戏的部分代码向我们展示了“重复”程序代码的弊端,为了改进 ...
- “吃神么,买神么”的第二个Sprint计划(总结)
“吃神么,买神么”项目Sprint计划 ——5.28 星期四(第八天)第一次Spring计划结束 第一阶段Spring的目标以及完成情况: 时间:5月21号~5月28号(7天) 目标:第二阶段主 ...
- DPDK L3fwd 源码阅读
代码部分 整个L3fwd有三千多行代码,但总体思想就是在L2fwd的基础上,增加网络层的根据 IP 地址进行路由查找的内容. main.c 文件 int main(int argc, char **a ...
- Java 线程结束 & 守护线程
/* 停止线程: 1,stop方法. 2,run方法结束. 怎么控制线程的任务结束呢? 任务中都会有循环结构,只要控制住循环就可以结束任务. 控制循环通常就用定义标记来完成. 但是如果线程处于了冻结状 ...
- Python开发【第五篇】迭代器、生成器、递归函数、二分法
阅读目录 一.迭代器 1. 迭代的概念 #迭代器即迭代的工具(自定义的函数),那什么是迭代呢? #迭代:指一个重复的过程,每次重复都可以称之为一次迭代,并且每一次重复的结果是下一个迭代的初始值(例如: ...
- grunt入门讲解6:grunt使用步骤和总结
Grunt是啥? 很火的前端自动化小工具,基于任务的命令行构建工具. Grunt能帮我们干啥? 假设有这样一个场景: 编码完成后,你需要做以下工作 HTML去掉注析.换行符 - HtmlMin CSS ...
- excel文件怎么使用php进行处理
1.可以通过phpmyadmin导入csv文件 2.也可以直接使用php 处理已经将excel另存为.csv后缀的文件, 通过php专门处理csv文件的函数 如 fgetcsv() <?php ...