Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在代码实现的级别管理好每一个处理步骤之间的先后运行关系,极大地简化了开发机器学习应用的难度。
Spark ML Pipeline使用DataFrame作为机器学习输入输出数据集的抽象。DataFrame来自Spark SQL,表示对数据集的一种特殊抽象,它也是Dataset(它是Spark 1.6引入的表示分布式数据集的抽象接口),但是DataFrame通过为数据集中每行数据的每列指定列名的方式来组织Dataset,类似于关系数据库中的表,同时还在底层处理做了非常多的优化。DataFrame可以基于不同的数据源进行构建,比如结构化文件、Hive表、数据库、RDD等。或者更直白一点表达什么是DataFrame,可以认为它等价于Dataset[Row],表示DataFrame是一个Row类型数据对象的Dataset。
机器学习可以被应用于各种数据类型,例如向量、文本、图片、结构化数据。Spark ML API采用DataFrame的理由是,来自Spark SQL中的DataFrame接口的抽象,可以支持非常广泛的类型,而且表达非常直观,便于在Spark中进行处理。所以说,DataFrame是Spark ML最基础的对数据集的抽象,所有各种ML Pipeline组件都会基于DataFrame构建更加丰富、复杂的数据处理逻辑。
Spark ML Pipeline主要包含2个核心的数据处理组件:Transformer、Estimator,其中它们都是Pipeline中PipelineStage的子类,另外一些抽象,如Model、Predictor、Classifier、Regressor等都是基于这两个核心组件衍生出来,比如,Model是一个Transformer,Predictor是一个Estimator,它们的关系如下类图所示:
基于上图,我们对它们进行详细的说明,如下所示:
- Transformer
Transformer对机器学习中要处理的数据集进行转换操作,类似于Spark中对RDD进行的Transformation操作(对一个输入RDD转换处理后生成一个新的RDD),Transformer是对DataFrame进行转换。我们可以从Transformer类的代码抽象定义,来看一下它定义的几个参数不同的transform方法,如下所示:
package org.apache.spark.ml @DeveloperApi
abstract class Transformer extends PipelineStage { @Since("2.0.0")
@varargs
def transform(
dataset: Dataset[_],
firstParamPair: ParamPair[_],
otherParamPairs: ParamPair[_]*): DataFrame = {
val map = new ParamMap()
.put(firstParamPair)
.put(otherParamPairs: _*)
transform(dataset, map)
} @Since("2.0.0")
def transform(dataset: Dataset[_], paramMap: ParamMap): DataFrame = {
this.copy(paramMap).transform(dataset)
} @Since("2.0.0")
def transform(dataset: Dataset[_]): DataFrame override def copy(extra: ParamMap): Transformer
}
上面对应的多个transform方法,都会输入一个Dataset[_],经过转换处理后输出一个DataFrame,实际上你可以通过查看DataFrame的定义,其实它就是一个Dataset,如下所示:
type DataFrame = Dataset[Row]
Transformer主要抽象了两类操作:一类是对特征进行转换,它可能会从一个DataFrame中读取某列数据,然后通过map算法将该列数据转换为新的列数据,比如,输入一个DataFrame,将输入的原始一列文本数据,转换成一列特征向量,最后输出的数据还是一个DataFrame,对该列数据转换处理后还映射到输入时的列名(通过该列名可以操作该列数据)。
下面,我们看一下,Spark MLLib中实现的Transformer类继承关系,如下类图所示:![]()
- Estimator
Estimator用来训练模型,它的输入是一个DataFrame,输出是一个Model,Model是Spark ML中对机器学习模型的抽象和定义,Model其实是一个Transformer。一个机器学习算法是基于一个数据集进行训练的,Estimator对基于该训练集的机器学习算法进行了抽象。所以它的输入是一个数据集DataFrame,经过训练最终得到一个模型Model。
Estimator类定了fit方法来实现对模型的训练,类的代码如下所示:
package org.apache.spark.ml @DeveloperApi
abstract class Estimator[M <: Model[M]] extends PipelineStage { @Since("2.0.0")
@varargs
def fit(dataset: Dataset[_], firstParamPair: ParamPair[_], otherParamPairs: ParamPair[_]*): M = {
val map = new ParamMap()
.put(firstParamPair)
.put(otherParamPairs: _*)
fit(dataset, map)
} @Since("2.0.0")
def fit(dataset: Dataset[_], paramMap: ParamMap): M = {
copy(paramMap).fit(dataset)
} @Since("2.0.0")
def fit(dataset: Dataset[_]): M @Since("2.0.0")
def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]): Seq[M] = {
paramMaps.map(fit(dataset, _))
} override def copy(extra: ParamMap): Estimator[M]
}
通过上面代码可以看到,Estimator调用fit方法以后,得到一个Model,也就是Transformer,一个Transformer又可以对输入的DataFrame执行变换操作。
下面,我们看一下,Spark MLLib中实现的Estimator类,如下类图所示:
- PipelineStage
PipelineStage是构建一个Pipeline的基本元素,它或者是一个Transformer,或者是一个Estimator。
- Pipeline
Pipeline实际上是Estimator的实现类,一个Pipeline是基于多个PipelineStage构建而成的DAG图,简单一点可以使用线性的PipelineStage序列来完成机器学习应用的构建,当然也可以构建相对复杂一些的PipelineStage DAG图。
调用Pipeline的fit方法,会生成一个PipelineModel,它是Model的子类,所以也就是一个Transformer。在训练过程中,Pipeline中的多个PipelineStage是运行在训练数据集上的,最后生成了一个Model。我们也可以看到,训练模型过程中,处于最后面的PipelineStage应该是一个或多个连续的Estimator,因为只有Estimator运行后才会生成Model。
接着,就是Pipeline中处于训练阶段和测试阶段之间,比较重要的一个PipelineStage了:PipelineModel,它起了承上启下的作用,调用PipelineModel的transform方法,按照和训练阶段类似的数据处理(转换)流程,经过相同的各个PipelineState对数据集进行变换,最后将训练阶段生成模型作用在测试数据集上,从而实现最终的预测目的。
基于Spark ML Pipeline,可以很容易地构建这种线性Pipeline,我们可以看到一个机器学习应用构建过程中(准备数据、训练模型、评估模型)的各个处理过程,可以通过一个同一个Pipeline API进行线性组合,非常直观、容易管理。
Spark ML Pipeline实践
这里,我们直接根据Spark ML Pipeline官方文档给出的示例——基于Logistic回归实现文本分类,来详细说明通过Spark ML Pipeline API构建机器学习应用,以及具体如何使用它。官网给出的这个例子非常直观,后续有关在实际业务场景中的实践,我们会单独在另一篇文章中进行分享。
- 场景描述
这个示例:
在训练阶段,需要根据给定的训练文本行数据集,将每个单词分离出来;然后根据得到的单词,生成特征向量;最后基于特征向量,选择Logistic回归算法,进行训练学习生成Logistic模型。
在测试阶段,需要按照如上相同的方式去处理给定的测试数据集,基于训练阶段得到的模型,进行预测。
- 训练阶段
训练阶段各个数据处理的步骤,如下图所示:
上图中,蓝色方框表示的都是Transformer,红色方框表示Estimator。
在训练阶段,通过Pipeline运行时,Tokenizer和HashingTF都会将输入的DataFrame进行转换,生成新的DataFrame;LogisticRegression是一个Estimator,当调用LogisticRegression的fit方法时,会生成一个LogisticRegressionModel,它是一个Transformer,可以在测试阶段使用。
- 测试阶段
上面的过程都是在调用Pipeline的fit方法时进行处理的,最后会生成一个PipelineModel,它是一个Transformer,会被用于测试阶段。测试阶段运行始于该PipelineModel,具体处理流程如下图所示: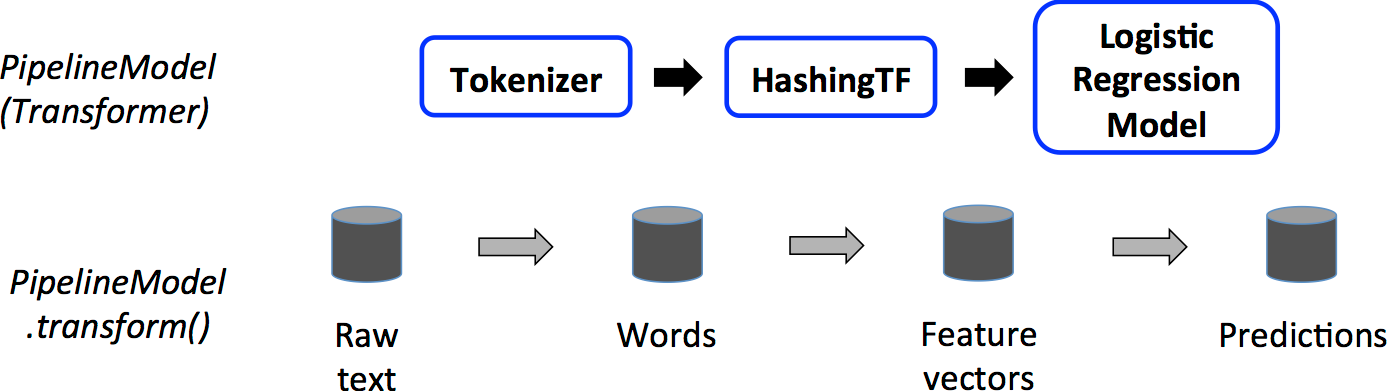
PipelineModel作为一个Transformer,首先也会对输入的测试数据集执行转换操作,对比训练阶段的处理流程,可以看到,在训练阶段的Estimator都变成了Transformer,因为我们在测试阶段的输出就是一个结果集DataFrame,而不需要训练阶段生成Model了。
- 示例代码
首先,准备模拟的训练数据集,代码如下所示:
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
模拟的训练数据集中,有3个字段,分别为ID、文本内容、标签。在实际应用中,我们应该是从指定的文件系统中去读取数据,如HDFS,只需要根据需要修改即可。
其次,创建一个Pipeline对象,同时设置对应的多个顺序执行的PipelineStage,代码如下所示:
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words") val hashingTF = new HashingTF()
.setNumFeatures()
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features") val lr = new LogisticRegression()
.setMaxIter()
.setRegParam(0.001) val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr)) // 包含3个PipelineStage
接着,就可以基于训练数据集进行训练操作了,代码如下所示:
val model = pipeline.fit(training)
调用Pipeline的fit方法生成了一个Model,我们可以根据实际情况,选择是否将生成模型进行保存(以便后续重新加载使用模型),如下所示:
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model") // We can also save this unfit pipeline to disk
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
然后,创建一个模拟测试数据集,用来测试前面训练生成的模型,代码如下所示:
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
测试数据集中,标签(Label)都是未知的,通过将前面生成的模型作用在该测试数据集上,就会预测生成对应的标签数据,代码如下所示:
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
这样就能够基于预测的结果,验证分类模型的准确性。
最后,可以将生成模型用于实际应用场景中,完成需要的功能。
有关更多使用Spark ML Pipeline的例子,可以参考Spark发行包中,examples里面src/main/scala/ml下面的很多示例代码,非常好的学习资源。
Spark ML Pipeline简介的更多相关文章
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- spark ml pipeline构建机器学习任务
一.关于spark ml pipeline与机器学习一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的流 ...
- spark ML pipeline 学习
一.pipeline 一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出.这非常类似于流水线式工作,即通常会包含源数据ETL(抽取.转化.加载),数据预处理,指标提取,模型训练与 ...
- spark ml 的例子
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- 基于Spark ML的Titanic Challenge (Top 6%)
下面代码按照之前参加Kaggle的python代码改写,只完成了模型的训练过程,还需要对test集的数据进行转换和对test集进行预测. scala 2.11.12 spark 2.2.2 packa ...
- Spark ML机器学习库评估指标示例
本文主要对 Spark ML库下模型评估指标的讲解,以下代码均以Jupyter Notebook进行讲解,Spark版本为2.4.5.模型评估指标位于包org.apache.spark.ml.eval ...
- Spark.ML之PipeLine学习笔记
地址: http://spark.apache.org/docs/2.0.0/ml-pipeline.html Spark PipeLine 是基于DataFrames的高层的API,可以方便用户 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- Spark ML源码分析之一 设计框架解读
本博客为作者原创,如需转载请注明参考 在深入理解Spark ML中的各类算法之前,先理一下整个库的设计框架,是非常有必要的,优秀的框架是对复杂问题的抽象和解剖,对这种抽象的学习本身 ...
随机推荐
- ubuntu 按键替换 Control_R to Left
ubuntu 按键替换 Control_R to Left 1 查看当前键盘布局 $xmodmap -pke keycode 105 = Control_R NoSymbol Control_Rkey ...
- Hibernate Annotations 注解
Hibernate Annotations 注解 对于org.hibernate.annotations与org.hibernate.persistence,它的注释比如Columns,可是不知道怎么 ...
- 《Programming with Objective-C》第五章 Customizing Existing Classes
1.分类里面只新增函数,不要新增变量:虽然新增是语法合法的,但是编译器并不会为你的property合成相应的成员变量.setter和getter Categories can be used to d ...
- MP 及OMP算法解析
转载自http://blog.csdn.net/pi9nc/article/details/18655239 1,MP算法[盗用2] MP算法是一种贪心算法(greedy),每次迭代选取与当前样本残差 ...
- TcpClient和Tcplistener
前天去面试,让写这东西 之前的项目也做过这东西,好长时间没看,就给忘了,惭愧!今天重新拾起来,做了个简单的demo Client端 static void Main(string[] args) { ...
- ios开发之 -- 强制横屏
在写项目的时候,会遇到很多稀奇古怪的需求,我就碰到一个写一个网站,需要强制横屏,然后不需要上架,网上看了很多大神的需求,基本都能实现,但是不太好用, 自己参考搞了一个,代码如下: AppDelegat ...
- 使用 composer 下载更新卸载类库
前言:要下载什么包,可以去 https://packagist.org/ 找一下包名及其版本信息 1)配置composer.json文件,并使用composer install 命令下载类包,下面以下 ...
- 使用Audio API设计绚丽的HTML5音乐播放器
HTML5 有两个很炫的元素,就是Audio和 Video,可以用他们在页面上创建音频播放器和视频播放器,制作一些效果很不错的应用. 无论是视屏还是音频,都是一个容器文件,包含了一些音频轨道,视频轨道 ...
- 构建API
前言 过程,如图: 第一步创建一个帮助类,类里面提供了加密.组装Url等方法,代码如下: using System; using System.Collections.Generic; using S ...
- 【BZOJ3195】[Jxoi2012]奇怪的道路 状压DP
[BZOJ3195][Jxoi2012]奇怪的道路 Description 小宇从历史书上了解到一个古老的文明.这个文明在各个方面高度发达,交通方面也不例外.考古学家已经知道,这个文明在全盛时期有n座 ...