从《数据挖掘概念与技术》到《Web数据挖掘》
从《数据挖掘概念与技术》到《Web数据挖掘》
认真读过《数据挖掘概念与技术》的第一章后,对数据挖掘有了更加深刻的了解。数据挖掘是知识发展过程的一个步骤。知识发展的过程可以分为:数据清洗(去噪和去除不一致数据)、数据集成(多个数据源组合在一起)、数据选择(从数据库中提取和分析与任务相关的数据)、数据变换(汇总、聚集,变成统一形式)、数据挖掘(智能方法提取数据模式)、模式评估(根据兴趣度度量、识别代表知识的真正有趣的模式)、知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。数据的基本组成形式包括:数据库数据、数据仓库数据(异构数据源在单个站点以统一的模式组织的存储)、事物数据、其他数据(时间数据挖掘、计算机网络数据、空间数据、文本数据、多媒体数据和Web数据)。数据的可挖掘的模式包括:类/概念描述:特征化与区别、挖掘频繁模式、关联和相关性(频繁模式包括频繁项集、频繁子序列和频繁子结构)、用于预测分析的分类和回归(导出的模型可以用各种形式表示,如分类规则、决策树、数学公式、神经网络)、聚类分析、离群点分析;数据挖掘作为一个交叉学科,设计统计学、机器学习、模式识别、数据库系统与数据仓库、信息检索、算法等;数据挖掘的主要问题包括:挖掘方法、用户交互、有效性与可伸缩性、数据类型的多样性、数据挖掘与社会。
通过对引言部分的总结,发现Web数据可以作为数据挖掘领域的有趣分支进行深入钻研,所以今后的方向打算对《Web数据挖掘》进行深入探讨。
Web数据挖掘的目标是从Web的超链接结构、网页内容和使用日志中探寻有用的信息。Web挖掘的任务可以换分为三种:Web结构挖掘(从表征Web结构的超链接中寻找有用的知识,例如找寻重要的网页)、Web内容挖掘(从网页内容中抽取有用的信息和知识,自动进行聚类和分类,例如商品描述、论坛回帖等)、Web使用挖掘(从记录每位用户点击情况的使用日志中挖掘用户的访问模式,例如点击流数据的预处理)。Web挖掘过程中,数据收集是一项艰巨的任务,需要爬取大量的网页。之后就是进行数据预处理、Web数据挖掘和数据后续处理。
算法预备:关联规则
关联规则在网页和纯文本文件中,来找群单词见并发关系和Web的使用模式。
关联规则挖掘是指"给定一个事物集合T,找出T中多有满足支持度和置信度分别高于一个用户指定的最小支持度(T中包含X并Y的事物的百分比)和最小置信度(条件概率函数)"。在大量的关联规则挖掘算法中,尽管效率各不相同(是否对效率进行研究),但是在同样的关联规则定义下,他们的输出结果应该一样。
Apriori算法
Apriori算法分为两步进行;(1)生成所有频繁项目集(一个频繁项目集是一个支持度高于最小支持度的项集)(2)从频繁项目集中生成所有可信关联规则(一个可信关联规则是置信度大于最小置信度的规则)
频繁项集中的难点和重点是合并和剪枝,合并:将两个(k-1)-频繁项目集合并产生一个可能的k-候选项集c。两个频繁项目集f1和f2的前k-2个项目都是相同,只有最后一个项目是不同的。随后c被加入到候选项集集合Ck中。剪枝:从合并步中得到的候选项集集合并不是最终的Ck。需要判断c的所有(k-1)-子集是否都在Fk-1中。如果其中任何一个子集不在Fk-1中,则根据向下封闭原理,c必然不可能是频繁项目集,将c从候选集Ck中剔除。
关联规则生成算法中,需要记住一点,如果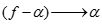 是一条关联规则,那么所有
是一条关联规则,那么所有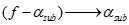 也必然是关联规则。
也必然是关联规则。
关联规则的挖掘可以应用在关系数据表上进行,只需要先把表数据转换成事物数据。
从《数据挖掘概念与技术》到《Web数据挖掘》的更多相关文章
- 【读书笔记-数据挖掘概念与技术】数据仓库与联机分析处理(OLAP)
之前看了认识数据以及数据的预处理,那么,处理之后的数据放在哪儿呢?就放在一个叫“数据仓库”的地方. 数据仓库的基本概念: 数据仓库的定义——面向主题的.集成的.时变的.非易失的 操作数据库系统VS数据 ...
- 数据挖掘概念与技术15--为快速高维OLAP预计算壳片段
1. 论数据立方体预计算的多种策略的优弊 (1)计算完全立方体:需要耗费大量的存储空间和不切实际的计算时间. (2)计算冰山立方体:优于计算完全立方体,但在某种情况下,依然需要大量的存储空间和计算时间 ...
- 利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法
from itertools import combinations data = [['I1', 'I2', 'I5'], ['I2', 'I4'], ['I2', 'I3'], ['I1', 'I ...
- 大数据的常用算法(分类、回归分析、聚类、关联规则、神经网络方法、web数据挖掘)
在大数据时代,数据挖掘是最关键的工作.大数据的挖掘是从海量.不完全的.有噪声的.模糊的.随机的大型数据库中发现隐含在其中有价值的.潜在有用的信息和知识的过程,也是一种决策支持过程.其主要基于人工智能, ...
- 你知道吗?Web的26项基本概念和技术
这是我在网上看到一篇不错的文章,拿出来与大家分享一下:希望有所帮助 作者: 小鱼 来源: 前端里 发布时间: 2014-08-01 22:56 阅读: 10477 次 推荐: 51 原文链 ...
- Web的26项基本概念和技术
---恢复内容开始--- Web开发是比较费神的,需要掌握很多很多的东西,特别是从事前端开发的朋友,需要通十行才行.今天,本文向初学者介绍一些Web开发中的基本概念和用到的技术,从A到Z总共26项,每 ...
- 【JavaScript】你知道吗?Web的26项基本概念和技术
Web开发是比较费神的,需要掌握很多很多的东西,特别是从事前端开发的朋友,需要通十行才行.今天,本文向初学者介绍一些Web开发中的基本概念和用到的技术,从A到Z总共26项,每项对应一个概念或者技术. ...
- PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品,产品设计严格遵循国际数据挖掘标准CRISP-DM(跨行业数据挖掘过程标准),具备完备的数据准备、模型构建、模型评估、模型管理、海量数据处理和高纬数据可视化分析能力。
http://www.meritdata.com.cn/article/90 PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品, ...
- 20145226夏艺华 网络对抗技术EXP8 WEB基础实践
20145226夏艺华 网络对抗技术EXP8 WEB基础实践 实验问题回答 1.什么是表单? 表单在网页中主要负责数据采集功能.一个表单有三个基本组成部分: 表单标签:这里面包含了处理表单数据所用CG ...
随机推荐
- Linux wc指令解析
wc指令比较实用,可以统计文件中的字节数.字符数.行数.字数等. 先通过 wc --help 查看指令帮助. $ wc --help Usage: wc [OPTION]... [FILE]... o ...
- selenium+python 移动鼠标方法
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver=we ...
- 错误 1 缺少编译器要求的成员“System.Runtime.CompilerServices.ExtensionAttrib
错误 1 缺少编译器要求的成员“System.Runtime.CompilerServices.ExtensionAttrib 删除Newtonsoft.Json.dll 引用 ,再重新引用即可. 原 ...
- Build fast jar 打包,增加配置文件
Build fast jar 打包,增加配置文件
- Java 字符串 String
什么是Java中的字符串 在 Java 中,字符串被作为 String 类型的对象处理. String 类位于 java.lang 包中.默认情况下,该包被自动导入所有的程序. 创建 String 对 ...
- 转载spring restemplate
什么是RestTemplate? RestTemplate是Spring提供的用于访问Rest服务的客户端,RestTemplate提供了多种便捷访问远程Http服务的方法,能够大大提高客户端的编写效 ...
- Mysql总结(一)
数据库命令:创建create database 数据库名 charset=utf8;删除drop database 数据库名;查看所有数据库:show databases;使用数据库:use 数据库名 ...
- Requests抓取火车票数据
1.数据接口 https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes=ADULT&queryDate=2016-08-01&from_ ...
- Yii中使用RBAC完全指南
开始准备 Yii提供了强大的配置机制和很多现成的类库.在Yii中使用RBAC是很简单的,完全不需要再写RBAC代码.所以准备工作就是,打开编辑器,跟我来.设置参数.建立数据库 在配置数组中,增加以下内 ...
- 分享 - 普通程序员如何转向AI方向
原作者:计算机的潜意识 原文链接,内容稍有改动,侵删 1. 目的2. AI领域简介3. 学习方法4. 学习路线 0) 领域了解1) 知识准备2) 机器学习3) 实践做项目4) 深度学习5) 继续机器学 ...