三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块
scrapy-redis的依赖
- Python 2.7, 3.4 or 3.5,Python支持版本
- Redis >= 2.8,Redis版本
Scrapy>= 1.1,Scrapy版本redis-py>= 2.10,redis-py版本,redis-py是一个Python操作Redis的模块,scrapy-redis底层是用redis-py来实现的
下载地址:https://pypi.python.org/pypi/scrapy-redis/0.6.8
我们以scrapy-redis/0.6.8版本为讲
一、安装scrapy-redis/0.6.8版本的依赖
首先安装好scrapy-redis/0.6.8版本的依赖关系模块和软件
二、创建scrapy项目
执行命令创建项目:scrapy startproject fbshpch
三、将下载的scrapy-redis-0.6.8模块包解压,解压后将包里的crapy-redis-0.6.8\src\scrapy_redis的scrapy_redis文件夹复制到项目中
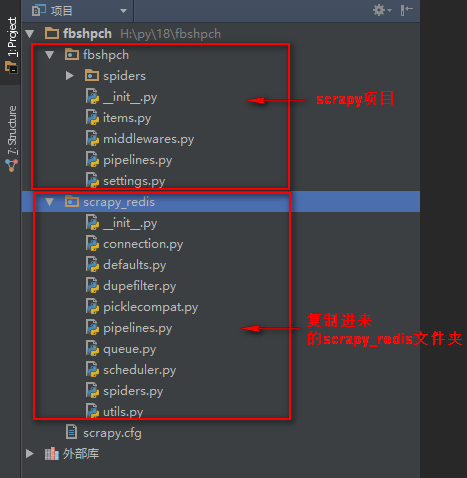
四、分布式爬虫实现代码,普通爬虫,相当于basic命令创建的普通爬虫
注意:分布式普通爬虫必须继承scrapy-redis的RedisSpider类

#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy_redis.spiders import RedisSpider # 导入scrapy_redis里的RedisSpider类
import scrapy
from scrapy.http import Request #导入url返回给下载器的方法
from urllib import parse #导入urllib库里的parse模块 class jobboleSpider(RedisSpider): # 自定义爬虫类,继承RedisSpider类
name = 'jobbole' # 设置爬虫名称
allowed_domains = ['blog.jobbole.com'] # 爬取域名
redis_key = 'jobbole:start_urls' # 向redis设置一个名称储存url def parse(self, response):
"""
获取列表页的文章url地址,交给下载器
"""
# 获取当前页文章url
lb_url = response.xpath('//a[@class="archive-title"]/@href').extract() # 获取文章列表url
for i in lb_url:
# print(parse.urljoin(response.url,i)) #urllib库里的parse模块的urljoin()方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接
yield Request(url=parse.urljoin(response.url, i),
callback=self.parse_wzhang) # 将循环到的文章url添加给下载器,下载后交给parse_wzhang回调函数 # 获取下一页列表url,交给下载器,返回给parse函数循环
x_lb_url = response.xpath('//a[@class="next page-numbers"]/@href').extract() # 获取下一页文章列表url
if x_lb_url:
yield Request(url=parse.urljoin(response.url, x_lb_url[0]),
callback=self.parse) # 获取到下一页url返回给下载器,回调给parse函数循环进行 def parse_wzhang(self, response):
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract() # 获取文章标题
print(title)
五、分布式爬虫实现代码,全站自动爬虫,相当于crawl命令创建的全站自动爬虫
注意:分布式全站自动爬虫必须继承scrapy-redis的RedisCrawlSpider类
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy_redis.spiders import RedisCrawlSpider # 导入scrapy_redis里的RedisCrawlSpider类
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule class jobboleSpider(RedisCrawlSpider): # 自定义爬虫类,继承RedisSpider类
name = 'jobbole' # 设置爬虫名称
allowed_domains = ['www.luyin.org'] # 爬取域名
redis_key = 'jobbole:start_urls' # 向redis设置一个名称储存url rules = (
# 配置抓取列表页规则
# Rule(LinkExtractor(allow=('ggwa/.*')), follow=True), # 配置抓取内容页规则
Rule(LinkExtractor(allow=('.*')), callback='parse_job', follow=True),
) def parse_job(self, response): # 回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数
# 利用ItemLoader类,加载items容器类填充数据
neir = response.css('title::text').extract()
print(neir)
六、settings.py文件配置
# 分布式爬虫设置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 使调度在redis存储请求队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 确保所有的蜘蛛都共享相同的过滤器通过Redis复制
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300 # 存储在redis刮项后处理
}
七、执行分布式爬虫
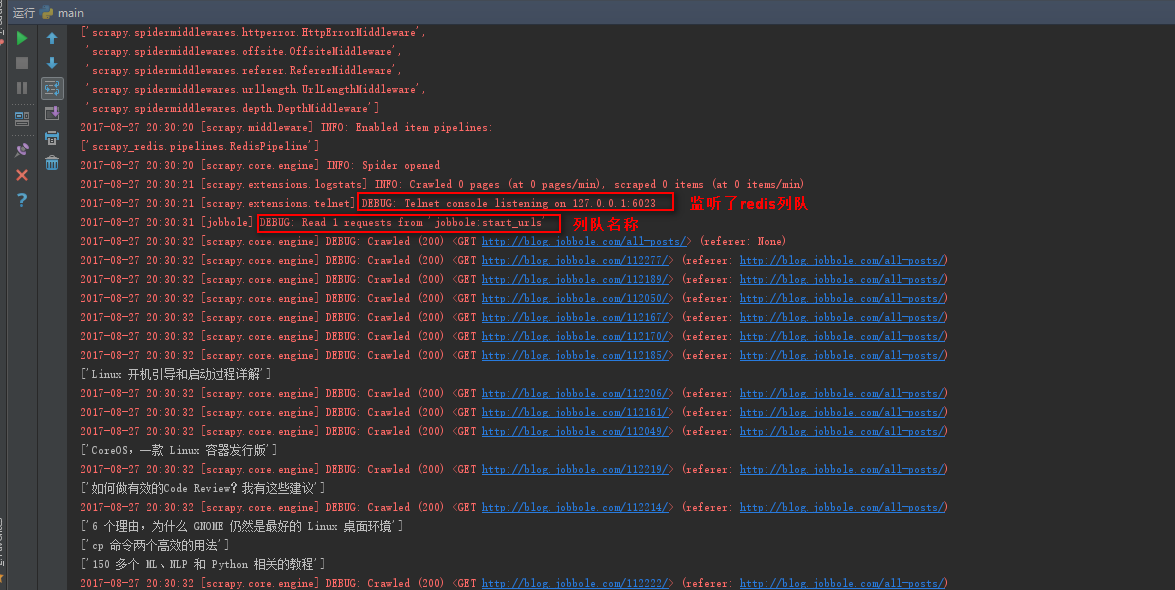
1、运行命令:scrapy crawl jobbole(jobbole表示爬虫名称)
2、启动redis,然后cd到redis的安装目录,
执行命令:redis-cli -h 127.0.0.1 -p 6379 连接一个redis客户端
在连接客户端执行命令:lpush jobbole:start_urls http://blog.jobbole.com/all-posts/ ,向redis列队创建一个起始URL
说明:lpush(列表数据) jobbole:start_urls(爬虫里定义的url列队名称) http://blog.jobbole.com/all-posts/(初始url)
八、scrapy-redis编写分布式爬虫代码原理
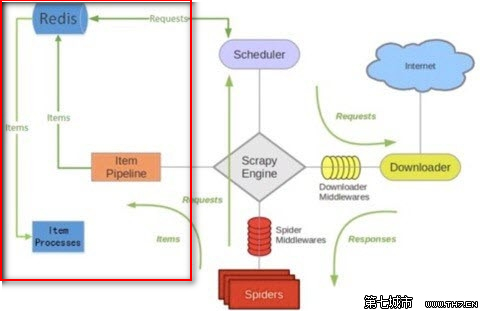
其他使用方法和单机版爬虫一样
三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码的更多相关文章
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
随机推荐
- 解决chrome在ubuntu+root模式下打不开的问题
chrome在ubuntu root模式下打不开 双击图标,chrome打不开了: 解决办法: 查看一下打开chrome浏览器的命令是什么,右键properties 发现是chromium-brows ...
- centos7 docker 安装配置
docker快速入门测试 ########################################## #docker安装配置 #环境centos7 #配置docker阿里源 echo '#D ...
- 踩坑之jinja2注释问题(Flask中)
报错信息 jinja2.exceptions.TemplateSyntaxError jinja2.exceptions.TemplateSyntaxError: Expected an expr ...
- Keras网络层之卷积层
卷积层 Cov1D层 keras.layers.convolutional.Conv1D(filters, kernel_size, strides=1, padding='valid', dilat ...
- mysql模糊查询实践总结
%代表任意多个字符 _代表一个字符 在 MySQL中,SQL的模式缺省是忽略大小写的 正则模式使用REGEXP和NOT REGEXP操作符. “.”匹配任何单个的字符.一个字符类 “[...]”匹配在 ...
- sql server always on 2014安装配置
SQL 2014 AlwaysOn 搭建 原文:SQL 2014 AlwaysOn 搭建 AlwaysOn底层依然采用Windows 故障转移群集的机制进行监测和转移,因此也需要先建立Window ...
- Dijkstra 算法初探
一.Dijkstra 算法的介绍 Dijkstra 算法,又叫迪科斯彻算法(Dijkstra),算法解决的是有向图中单个源点到其他顶点的最短路径问题.举例来说,如果图中的顶点表示城市,而边上的 ...
- 让Jackson JSON生成的数据包含的中文以unicode方式编码
本文出处:http://blog.csdn.net/chaijunkun/article/details/8257209,转载请注明.由于本人不定期会整理相关博文,会对相应内容作出完善.因此强烈建 ...
- mfc学习---文档视图架构
MFC的AppWizard可以生成三种类型的应用程序:基于对话框的应用.单文档应用(SDI)和多文档应用(MDI). 一般情况下,采用文档/视结构的应用程序至少应由以下对象组成: 1. ...
- MySQL引擎及选择
一.MySQL的存储引擎 完整的引擎说明还是看官方文档:http://dev.mysql.com/doc/refman/5.6/en/storage-engines.html 这里介绍一些主要的引擎 ...