【SQL周周练】给你无酸纸、变色油墨,你能伪造多少美金?
大家好,我是“蒋点数分”,多年以来一直从事数据分析工作。从今天开始,与大家持续分享关于数据分析的学习内容。
本文是第 2 篇,也是【SQL 周周练】系列的第 2 篇。该系列是挑选或自创具有一些难度的 SQL 题目,一周至少更新一篇。后续创作的内容,初步规划的方向包括:
后续内容规划
1.利用 Streamlit 实现 Hive 元数据展示、SQL 编辑器、 结合Docker 沙箱实现数据分析 Agent
2.时间序列异常识别、异动归因算法
3.留存率拟合、预测、建模
4.学习 AB 实验、复杂实验设计等
5.自动化机器学习、自动化特征工程
6.因果推断学习
7. ……
欢迎关注,一起学习。
第 2 期题目
题目来源:自创题目,场景来源于香港电影《无双》
一、题目介绍
《无双》是一部很不错的电影,其主题是伪造美钞。虽然已经上映多年,但其中“无酸纸”、“变色油墨”的梗,至今在网上依旧可以看到。其中的一个经典片段 —— “画家”(周润发)嗔怪“李问”(郭富城)订购了500吨无酸纸,说让“李文”活着给他印完(当然结尾展示了郭富城其实才是“画家”)。那么由此而来,我想出了一道 SQL 题:
假设伪钞集团每日给你供应随机数量的变色油墨、无酸纸、安全线/防伪线(未用完的材料可以留给后面用),凹版印刷机等其他材料和工具也已经准备好。
请你计算每天能制作伪钞多少张,并且根据当天的情况输出第二天最缺哪种材料:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
假设 一张伪钞需要 1g 无酸纸,0.005g 的变色油墨,1 根安全线;印制过程中不考虑损耗
二、题目思路
想要答题的同学,可以先思考答案。
……
……
……
我来谈谈我的思路:这道题目的设计,材料是以固定比例的投入产生一张伪钞,哪种材料相对较少,哪种材料就限制住了伪钞的制造数量;所以可以单独计算三种材料能制造多少伪钞,然后用 least 求最小值,类似“木桶短板理论”。题目里提到了当日未用完的材料,可以后面再用;所以每天不需要单独计算,直接计算从开始到当天 => 这又用上了数据分析师的老朋友“窗口函数”。
下面,我用 NumPy 和 Scipy 生成模拟的数据集:
三、生成模拟数据
只关心 SQL 代码的同学,可以跳转到第四节(我在工作中使用 Hive 较多,因此采用 Hive 的语法)
模拟代码如下:
常量,计算目标数量的伪钞需要多少材料:import numpy as np
import pandas as pd
import scipy
# 随机数种子
RANDOM_SEED = 2025
# 伪造开始日期
START_DATE = "2025-05-01"
# 伪造天数
NUM_DAY = 10
# 需要伪造的伪钞数量(张数,非金额)
NUM_TOTAL_COUNTERFEIT_CURRENCY = 1_000_000
# 一张伪钞需要多少无酸纸,简化问题只考虑重量(单位 g)
ACID_FREE_PAPER_EACH_COUNTERFEIT_CURRENCY = 1
# 所有伪钞需要的无酸纸(1.05 是一个冗余度,所有材料类似)
ACID_FREE_PAPER_ALL_NEED = (
ACID_FREE_PAPER_EACH_COUNTERFEIT_CURRENCY
* NUM_TOTAL_COUNTERFEIT_CURRENCY
* 1.05
)
# 一张伪钞需要多少变色油墨,重量(单位 mg)
OPTICALLY_VARIABLE_INK_EACH_COUNTERFEIT_CURRENCY = 5
# 所有伪钞需要的变色油墨
OPTICALLY_VARIABLE_INK_ALL_NEED = (
OPTICALLY_VARIABLE_INK_EACH_COUNTERFEIT_CURRENCY
* NUM_TOTAL_COUNTERFEIT_CURRENCY
* 1.05
)
# 一张伪钞需要多少安全线(单位 条)
SECURITY_THREAD_EACH_COUNTERFEIT_CURRENCY = 1
# 所有伪钞需要的防伪线
SECURITY_THREAD_ALL_NEED = (
SECURITY_THREAD_EACH_COUNTERFEIT_CURRENCY
* NUM_TOTAL_COUNTERFEIT_CURRENCY
* 1.05
)# 权重范围,用来随机生成数据(需要归一化)
WEIGHT_RANGE = (0.2, 2)
# 无酸纸每天供应的随机权重
acid_free_paper_supply_weight = scipy.stats.uniform.rvs(
loc=WEIGHT_RANGE[0],
scale=WEIGHT_RANGE[1] - WEIGHT_RANGE[0],
size=NUM_DAY,
random_state=RANDOM_SEED - 1,
)
# 变色油墨每天供应的权重
optically_variable_ink_supply_weight = scipy.stats.uniform.rvs(
loc=WEIGHT_RANGE[0],
scale=WEIGHT_RANGE[1] - WEIGHT_RANGE[0],
size=NUM_DAY,
random_state=RANDOM_SEED,
)
# 安全线每天供应的权重
security_thread_supply_weight = scipy.stats.uniform.rvs(
loc=WEIGHT_RANGE[0],
scale=WEIGHT_RANGE[1] - WEIGHT_RANGE[0],
size=NUM_DAY,
random_state=RANDOM_SEED + 1,
)
# 将权重归一化,使得所有天数的供应比例和为 1
acid_free_paper_supply_weight /= acid_free_paper_supply_weight.sum()
optically_variable_ink_supply_weight /= optically_variable_ink_supply_weight.sum()
security_thread_supply_weight /= security_thread_supply_weight.sum()pd.DataFrame,并输出为 csv 文件:df = pd.DataFrame(
{
"acid_free_paper_supply": ACID_FREE_PAPER_ALL_NEED
* acid_free_paper_supply_weight,
"optically_variable_ink_supply": OPTICALLY_VARIABLE_INK_ALL_NEED
* optically_variable_ink_supply_weight,
"security_thread_supply": SECURITY_THREAD_ALL_NEED
* security_thread_supply_weight
}
)
# 四舍五入并转为 int
df = df.round().astype(int)
df["date"] = pd.date_range(start=START_DATE, periods=NUM_DAY, freq="D")
# 在 Jupyter 中展示数据
display(df)
out_csv_path = "./dwd_conterfeit_material_daily_supply_records.csv"
columns = [
"date",
"acid_free_paper_supply",
"optically_variable_ink_supply",
"security_thread_supply"
]
# 导出 csv 用来让 hive load 数据,utf-8-sig 编码处理中文,虽然表里数据没有中文
df[columns].to_csv(out_csv_path, header=False, index=False, encoding="utf-8-sig")Hive 表,并将数据 load 到表中:from pyhive import hive
# 配置连接参数
host_ip = "127.0.0.1"
port = 10000
username = "蒋点数分"
with hive.Connection(host=host_ip, port=port) as conn:
cursor = conn.cursor()
drop_table_sql = """
drop table if exists data_exercise.dwd_conterfeit_material_daily_supply_records
"""
print(drop_table_sql)
cursor.execute(drop_table_sql)
create_table_sql = """
create table data_exercise.dwd_conterfeit_material_daily_supply_records (
`date` string comment "日期",
acid_free_paper_supply int comment "无酸纸供应量(单位g)",
optically_variable_ink_supply int comment "变色油墨供应量(单位mg)",
security_thread_supply int comment "安全线供应量"
)
comment "伪钞集团每天供应的伪钞原材料数量 | 文章编号:2c3d2561"
row format delimited fields terminated by ","
stored as textfile
"""
print(create_table_sql)
cursor.execute(create_table_sql)
import os
load_data_sql = f"""
load data local inpath "{os.path.abspath(out_csv_path)}"
overwrite into table data_exercise.dwd_conterfeit_material_daily_supply_records
"""
print(load_data_sql)
cursor.execute(load_data_sql)
cursor.close()我通过使用
PyHive包实现 Python 操作Hive。我个人电脑部署了Hadoop及Hive,但是没有开启认证,企业里一般常用Kerberos来进行大数据集群的认证。
四、SQL 解答
思路在第二节已经说明,下面是代码,细节参见注释。其中 cumulative_conterfeit_all_restriction 等于哪种材料的 cumulative_conterfeit_only... 就可以认为第二天最缺哪种材料(伪钞制造量被这种材料制约)。提示:order by 时,统计的窗口范围默认是 rows between preceding unbounded and current row,写清楚更好。三种材料单独判断,然后用 concat_ws 合并结果(注意其他 SQL 方言不一定有 Hive 的这个函数)。
每天的伪钞制造量 action_daily_production 使用 cumulative_conterfeit_all_restriction 结合窗口函数 lag 减去上一行即可。
with calc_single_material_restrict_production as (
-- 计算一种材料限制能造多少美元伪钞
select
`date`
, acid_free_paper_supply
, optically_variable_ink_supply
, security_thread_supply
-- 只考虑无酸纸,不考虑其他材料和每日最大制造量限制,累计伪钞制作数,下面以此类推
-- 有些材料比例为 1,因此不额外写除以 1
, sum(acid_free_paper_supply) over(orderby `date` asc) as cumulative_conterfeit_only_acid_free_paper
-- 注意向下取整
, floor(sum(optically_variable_ink_supply) over(orderby `date` asc) /5) as cumulative_conterfeit_only_optically_variable_ink
, sum(security_thread_supply) over(orderby `date` asc) as cumulative_conterfeit_only_security_thread
from data_exercise.dwd_conterfeit_material_daily_supply_records
)
, calc_all_restriction_prodection as (
select
`date`
, acid_free_paper_supply
, optically_variable_ink_supply
, security_thread_supply
, cumulative_conterfeit_only_acid_free_paper
, cumulative_conterfeit_only_optically_variable_ink
, cumulative_conterfeit_only_security_thread
-- 使用 least 计算最小值
, least(
cumulative_conterfeit_only_acid_free_paper,
cumulative_conterfeit_only_optically_variable_ink,
cumulative_conterfeit_only_security_thread
) as cumulative_conterfeit_all_restriction
from calc_single_material_restrict_production
)
select
`date`
, cumulative_conterfeit_only_acid_free_paper
, cumulative_conterfeit_only_optically_variable_ink
, cumulative_conterfeit_only_security_thread
, cumulative_conterfeit_all_restriction
-- 减去上一行的数据,获取每日伪钞制造量
, cumulative_conterfeit_all_restriction -lag(cumulative_conterfeit_all_restriction, 1, 0) over(orderby `date` asc) as action_daily_production
, if( cumulative_conterfeit_all_restriction >=1000000, null, -- 已经完成目标量,就不写缺哪种材料了
concat_ws(',',
if(cumulative_conterfeit_only_acid_free_paper=cumulative_conterfeit_all_restriction, '无酸纸', null),
if(cumulative_conterfeit_only_optically_variable_ink=cumulative_conterfeit_all_restriction, '变色油墨', null),
if(cumulative_conterfeit_only_security_thread=cumulative_conterfeit_all_restriction, '安全线', null)
)
) as `最缺的材料`
from calc_all_restriction_prodection查询结果如下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
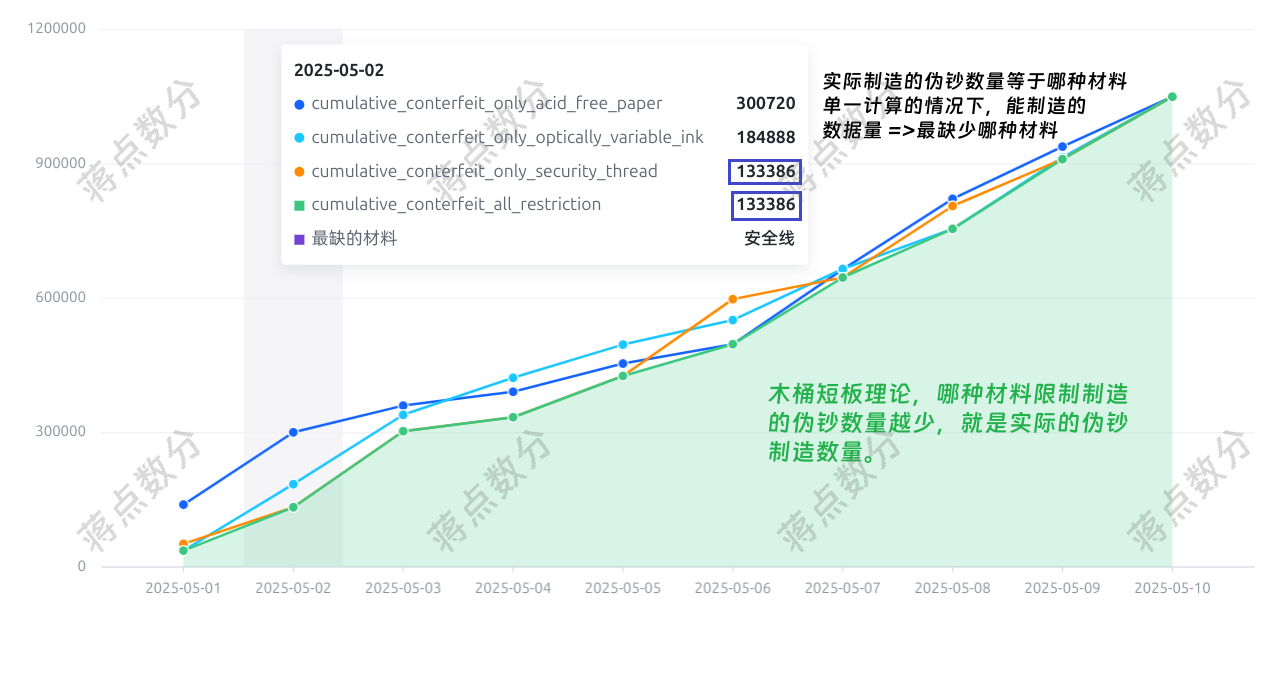
上面的图片,是我在 Python 中使用 pyvchart 库实现的,它是字节跳动开源的 vchart 的 Python 包,当然你也可以使用 pyecharts。pd.melt 函数用于将“宽数据框”转“长数据框”。代码部分如下:
with hive.Connection(host=host_ip, port=port) as conn:
select_data_sql = ''' 我给出 SQL 答案 '''
df_outcome = pd.read_sql_query(select_data_sql, conn)
from pyvchart import render_chart
spec = {
"type": 'area',
"data": [
{
"id": 'lineData',
"values": pd.melt(df_outcome[[
'date','cumulative_conterfeit_only_acid_free_paper',
'cumulative_conterfeit_only_optically_variable_ink',
'cumulative_conterfeit_only_security_thread'
]], id_vars=['date']).to_dict(orient='records')
},
{
"id": 'areaData',
"values": pd.melt(df_outcome[['date','cumulative_conterfeit_all_restriction',
'最缺的材料']], id_vars=['date']).to_dict(orient='records')
},
],
"series": [
{
"type": 'line',
"dataId": 'lineData',
"xField": 'date',
"yField": 'value',
"seriesField": 'variable',
},
{
"type": 'area',
"dataId": 'areaData',
"xField": 'date',
"yField": 'value',
"seriesField": 'variable',
},
],
};
display(render_chart(spec))我现在正在求职数据类工作(主要是数据分析或数据科学);如果您有合适的机会,恳请您与我联系,即时到岗,不限城市。您可以发送私信或者联系我(全网同名:蒋点数分)。
【SQL周周练】给你无酸纸、变色油墨,你能伪造多少美金?的更多相关文章
- 数电第五周周结_by_yc
数电第五周周结_by_yc 基本要点: 组合逻辑电路的行为特点.经典组合逻辑电路的设计.PPA优化 组合逻辑电路设计要点: ①敏感变量列表应包含所有会影响输出的控制量: ②条件语句的完全描述, ...
- Sql获取周、月、年的首尾时间。
,) -- 本周周一 ,,,)) -- 本周周末 ,) -- 本月月初 ,,,)) -- 本月月末 ,,) -- 上月月初 ,,)) -- 上月月末 ,) -- 本年年初 ,,,)) -- 本年年末 ...
- 牛客算法周周练20 F.紫魔法师 (二分图染色)
题意:给你一张图,对其染色,使得相连的点的颜色两两不同求,最少使用多少种颜色. 题解:首先,若\(n=1\),只需要一种.然后我们再去判断是否是二分图,对于二分图,两种颜色就够了,若不是二分图,也就是 ...
- java第二周周学习总结
java运算符和循环 java运算符 一.for 语句 for 语句的基本结构如下所示:for(初始化表达式;判断表达式;递增(递减)表达式){ 执行语句; //一段代码} 初始化表达式:初 ...
- web前端笔记整理,从入门到上天,周周更新
由于大前端知识点太多,所以一一做了分类整理,详情可见本人博客 http://www.cnblogs.com/luxiaoyao/ 一.HTML 1.注释 格式:<!-- 注释内容 --> ...
- 第十七周周总结 Swing
考试系统 1.登录功能 用户和密码存在在哪里? 文件 2.考试功能 考试题目和答案存在哪? 文件 3.展示功能 GUI Graphical User Interface图形用户接口 #GUI Java ...
- 数电第11周周结_by_yc
Lab7_时序逻辑验证 一.简易电子时钟 功能描述: 设计一简易电子时钟,支持时.分.秒显示,其中HEX7-HEX6显示时,HEX5-HEX4显示分,HEX1-HEX0显示秒,假设进制为:18秒= ...
- 数电第8周周结_by_yc
基本知识: 1.有限状态机的分类: Moore型:输出仅与电路的状态有关: Mealy型:输出与当前电路状态和当前电路输入有关. 2.有限状态机的描述方法: 状态转换图:节点:状态(Moore输出): ...
- 数电第7周周结_by_yc
一.通用双向移位寄存器: 功能描述: 4位的双向移位寄存器,含控制输入端(ctrl).串行输入端(Dsl.Dsr).4个并行输入端和4个并行输出端,要求实现5种功能:异步置零.同步置数.左移.右移 ...
- 数电第六周周结_by_yc
时序逻辑电路的设计要点: ①只有时钟信号和复位信号可以放在敏感列表里: ②使用非阻塞赋值,即使用"<="; ③无需对所有分支进行描述,对于未描述的分支,变量将保持 ...
随机推荐
- Hetao P2071 打字游戏 题解 [ 绿 ] [ 最小生成树 ] [ 动态规划 ] [ 编辑距离 ]
打字游戏:MST 套 dp 好题. 首先看这个数据范围,\(O(n^4)\) 把每两个字符串之前的编辑距离求一下很显然吧. 然后我们观察一下每一个 node 的性质,发现他要么自己打完,要么从别人那里 ...
- .NET最佳实践:业务逻辑减少使用异常
在 .NET 开发中,异常处理是保证应用健壮性的重要手段,但不应被滥用. 异常的引发和捕获相较于普通的代码逻辑性能较差,因此在热路径(频繁执行的代码路径)中,避免依赖异常来控制程序流是提升性能的关键之 ...
- Java8 使用 stream().filter()过滤List对象等各种操作
内容简介 本文主要说明在Java8及以上版本中,使用stream().filter()来过滤一个List对象,查找符合条件的对象集合. list.stream().mapToDouble(User:: ...
- linux服务问题传文件连不上问题远程问题等
通过iptables相关命令实现防火墙的打开和关闭 1.首先可以在打开的终端使用iptables --help查看帮助使用命令: 2.查看防火墙状态:service iptables status(此 ...
- Sa-Token v1.41.0 发布 🚀,来看看有没有令你心动的功能!
Sa-Token 是一个轻量级 Java 权限认证框架,主要解决:登录认证.权限认证.单点登录.OAuth2.0.微服务网关鉴权 等一系列权限相关问题. 目前最新版本 v1.41.0 已推送至 Mav ...
- SpringSecurity5(10-动态权限管理)
授权流程 SpringSecurity 的授权流程如下: 拦截请求,已认证用户访问受保护的 web 资源将被 SecurityFilterChain 中的 FilterSecurityIntercep ...
- AI可解释性 I | 对抗样本(Adversarial Sample)论文导读(持续更新)
AI可解释性 I | 对抗样本(Adversarial Sample)论文导读(持续更新) 导言 本文作为AI可解释性系列的第一部分,旨在以汉语整理并阅读对抗攻击(Adversarial Attack ...
- 【SpringMVC】表单标签 & 处理静态资源
SpringMVC 表单标签 &处理静态资源 使用 Spring 的表单标签 • 通过 SpringMVC 的表单标签可以实现将模型数据中的属性和 HTML 表单元素相绑定,以实现表单数据更便 ...
- 【Unity】改变游戏运行时Window的窗口标题
[Unity]改变游戏运行时Window的窗口标题 零.需求 Unity打包好的Windows程序,启动后如何更改窗口标题?因为看着英文的感觉不太好,故有此想法.什么?你说为啥不改项目产品名?产品名会 ...
- Windows 鼠标右键失效
突然有一天...小邋遢他变了... 哦不是...鼠标右键/键盘菜单键莫名其妙失效了. 解决办法 运行 regedit 打开注册表编辑器 依次展开 HKEY_CURRENT_USER\Software\ ...