Elasticsearch搜索功能的实现(五)-- 实战
实战环境
elastic search 8.5.0 + kibna 8.5.0 + springboot 3.0.2 + spring data elasticsearch 5.0.2 + jdk 17
一、集成 spring data elasticsearch
1 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2 配置es连接
@Configuration
public class ElasticsearchConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("127.0.0.1:9200")
.withBasicAuth("elastic", "********")
.build();
}
}
3 配置打印DSL语句
# 日志配置
logging:
level:
#es日志
org.springframework.data.elasticsearch.client.WIRE : trace
二、index及mapping 文件编写
@Data
@Document(indexName = "news") //索引名
@Setting(shards = 1,replicas = 0,refreshInterval = "1s") //shards 分片数 replicas 副本数
@Schema(name = "News",description = "新闻对象")
public class News implements Serializable {
@Id //索引主键
@NotBlank(message = "新闻ID不能为空")
@Schema(type = "integer",description = "新闻ID",example = "1")
private Integer id;
@NotBlank(message = "新闻标题不能为空")
@Schema(type = "String",description = "新闻标题")
@MultiField(mainField = @Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart"),
otherFields = {@InnerField(type = FieldType.Keyword, suffix = "keyword") }) //混合类型字段 指定 建立索引时分词器与搜索时入参分词器
private String title;
@Schema(type = "LocalDate",description = "发布时间")
@Field(type = FieldType.Date,format = DateFormat.date)
private LocalDate pubDate;
@Schema(type = "String",description = "来源")
@Field(type = FieldType.Keyword)
private String source;
@Schema(type = "String",description = "行业类型代码",example = "1,2,3")
@Field(type = FieldType.Text,analyzer = "ik_max_word",searchAnalyzer = "ik_smart")
private String industry;
@Schema(type = "String",description = "预警类型")
@Field(type = FieldType.Keyword)
private String type;
@Schema(type = "String",description = "涉及公司")
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String companies;
@Schema(type = "String",description = "新闻内容")
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
}
三、DAO层编写
@Repository
public interface NewsRepository extends ElasticsearchRepository<News,Integer> {
Page<News> findByType(String type, Pageable pageable);
}
四、简单功能实现
4.1 简单功能写法
/**
* 新增新闻
* @param news
* @return
*/
@Override
public void saveNews(News news) {
newsRepository.save(news);
}
/**
* 删除新闻
* @param newsId
*/
@Override
public void delete(Integer newsId) {
newsRepository.deleteById(newsId);
}
/**
* 删除新闻索引
*/
@Override
public void deleteIndex() {
operations.indexOps(News.class).delete();
}
/**
* 创建索引
*/
@Override
public void createIndex() {
operations.indexOps(News.class).createWithMapping();
}
@Override
public PageResult findByType(String type) {
// 先发布日期排序
Sort sort = Sort.by(new Order(Sort.Direction.DESC, "pubDate"));
Pageable pageable = PageRequest.of(0,10,sort);
final Page<News> newsPage = newsRepository.findByType(type, pageable);
return new PageResult(newsPage.getTotalElements(),newsPage.getContent());
}
实现效果图片:
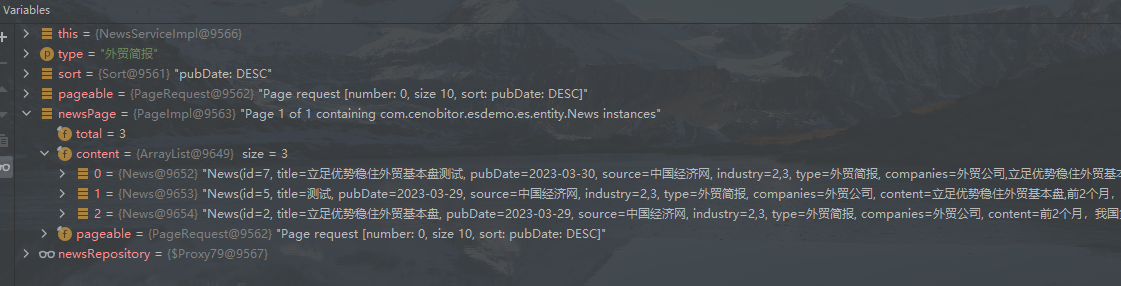
实际执行的DSL语句:

注意: 当指定排序条件时 _score 会被置空
4.2 搜索功能的实现
@Override
public PageResult searchNews(NewsPageSearch search) {
//创建原生查询DSL对象
final NativeQueryBuilder nativeQueryBuilder = new NativeQueryBuilder();
// 先发布日期再得分排序
Sort sort = Sort.by(new Order(Sort.Direction.DESC, "pubDate"),new Order(Sort.Direction.DESC, "_score"));
Pageable pageable = PageRequest.of(search.getCurPage(), search.getPageSize(),sort);
final BoolQuery.Builder boolBuilder = new BoolQuery.Builder();
//过滤条件
setFilter(search, boolBuilder);
//关键字搜索
if (StringUtils.isNotBlank(search.getKeyword())){
setKeyWordAndHighlightField(search, nativeQueryBuilder, boolBuilder);
}else {
nativeQueryBuilder.withQuery(q -> q.bool(boolBuilder.build()));
}
nativeQueryBuilder.withPageable(pageable);
SearchHits<News> searchHits = operations.search(nativeQueryBuilder.build(), News.class);
//高亮回填封装
final List<News> newsList = searchHits.getSearchHits().stream()
.map(s -> {
final News content = s.getContent();
final List<String> title = s.getHighlightFields().get("title");
final List<String> contentList = s.getHighlightFields().get("content");
if (!CollectionUtils.isEmpty(title)){
s.getContent().setTitle(title.get(0));
}
if (!CollectionUtils.isEmpty(contentList)){
s.getContent().setContent(contentList.get(0));
}
return content;
}).collect(Collectors.toList());
return new PageResult<News>(searchHits.getTotalHits(),newsList);
}
/**
* 设置过滤条件 行业类型 来源 预警类型
* @param search
* @param boolBuilder
*/
private void setFilter(NewsPageSearch search, BoolQuery.Builder boolBuilder) {
//行业类型
if(StringUtils.isNotBlank(search.getIndustry())){
// 按逗号拆分
List<Query> industryQueries = Arrays.asList(search.getIndustry().split(",")).stream().map(p -> {
Query.Builder queryBuilder = new Query.Builder();
queryBuilder.term(t -> t.field("industry").value(p));
return queryBuilder.build();
}).collect(Collectors.toList());
boolBuilder.filter(f -> f.bool(t -> t.should(industryQueries)));
}
// 来源
if(StringUtils.isNotBlank(search.getSource())){
// 按逗号拆分
List<Query> sourceQueries = Arrays.asList(search.getSource().split(",")).stream().map(p -> {
Query.Builder queryBuilder = new Query.Builder();
queryBuilder.term(t -> t.field("source").value(p));
return queryBuilder.build();
}).collect(Collectors.toList());
boolBuilder.filter(f -> f.bool(t -> t.should(sourceQueries)));
}
// 预警类型
if(StringUtils.isNotBlank(search.getType())){
// 按逗号拆分
List<Query> typeQueries = Arrays.asList(search.getType().split(",")).stream().map(p -> {
Query.Builder queryBuilder = new Query.Builder();
queryBuilder.term(t -> t.field("type").value(p));
return queryBuilder.build();
}).collect(Collectors.toList());
boolBuilder.filter(f -> f.bool(t -> t.should(typeQueries)));
}
//范围区间
if (StringUtils.isNotBlank(search.getStartDate())){
boolBuilder.filter(f -> f.range(r -> r.field("pubDate")
.gte(JsonData.of(search.getStartDate()))
.lte(JsonData.of(search.getEndDate()))));
}
}
/**
* 关键字搜索 title 权重更高
* 高亮字段 title 、content
* @param search
* @param nativeQueryBuilder
* @param boolBuilder
*/
private void setKeyWordAndHighlightField(NewsPageSearch search, NativeQueryBuilder nativeQueryBuilder, BoolQuery.Builder boolBuilder) {
final String keyword = search.getKeyword();
//查询条件
boolBuilder.must(b -> b.multiMatch(m -> m.fields("title","content","companies").query(keyword)));
//高亮
final HighlightFieldParameters.HighlightFieldParametersBuilder builder = HighlightFieldParameters.builder();
builder.withPreTags("<font color='red'>")
.withPostTags("</font>")
.withRequireFieldMatch(true) //匹配才加标签
.withNumberOfFragments(0); //显示全文
final HighlightField titleHighlightField = new HighlightField("title", builder.build());
final HighlightField contentHighlightField = new HighlightField("content", builder.build());
final Highlight titleHighlight = new Highlight(List.of(titleHighlightField,contentHighlightField));
nativeQueryBuilder.withQuery(
f -> f.functionScore(
fs -> fs.query(q -> q.bool(boolBuilder.build()))
.functions( FunctionScore.of(func -> func.filter(
fq -> fq.match(ft -> ft.field("title").query(keyword))).weight(100.0)),
FunctionScore.of(func -> func.filter(
fq -> fq.match(ft -> ft.field("content").query(keyword))).weight(20.0)),
FunctionScore.of(func -> func.filter(
fq -> fq.match(ft -> ft.field("companies").query(keyword))).weight(10.0)))
.scoreMode(FunctionScoreMode.Sum)
.boostMode(FunctionBoostMode.Sum)
.minScore(1.0)))
.withHighlightQuery(new HighlightQuery(titleHighlight,News.class));
}
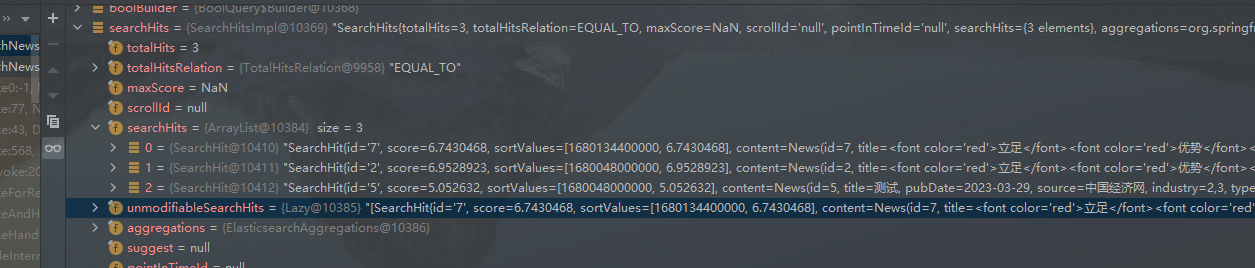
实现效果
加权前效果:
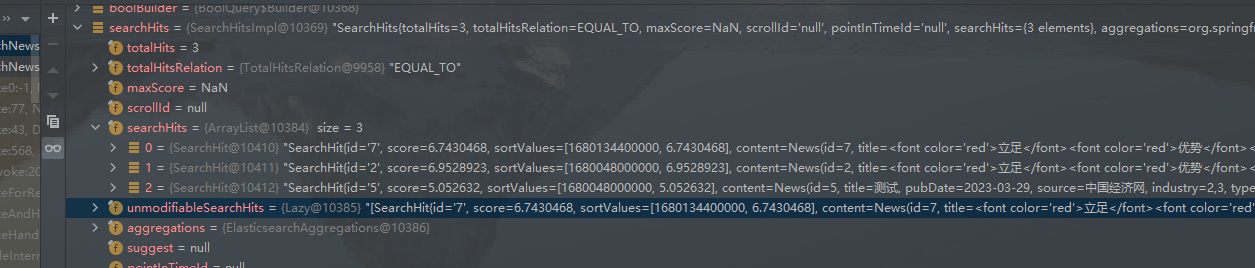
加权后效果:
DSL 语句:
{
"from": 0,
"size": 6,
"sort": [{
"pubDate": {
"mode": "min",
"order": "desc"
}
}, {
"_score": {
"order": "desc"
}
}],
"highlight": {
"fields": {
"title": {
"number_of_fragments": 0,
"post_tags": ["</font>"],
"pre_tags": ["<font color='red'>"]
},
"content": {
"number_of_fragments": 0,
"post_tags": ["</font>"],
"pre_tags": ["<font color='red'>"]
}
}
},
"query": {
"function_score": {
"boost_mode": "sum",
"functions": [{
"filter": {
"match": {
"title": {
"query": "立足优势稳住外贸基本盘"
}
}
},
"weight": 100.0
}, {
"filter": {
"match": {
"content": {
"query": "立足优势稳住外贸基本盘"
}
}
},
"weight": 20.0
}, {
"filter": {
"match": {
"companies": {
"query": "立足优势稳住外贸基本盘"
}
}
},
"weight": 10.0
}],
"min_score": 1.0,
"query": {
"bool": {
"filter": [{
"bool": {
"should": [{
"term": {
"industry": {
"value": "1"
}
}
}, {
"term": {
"industry": {
"value": "2"
}
}
}, {
"term": {
"industry": {
"value": "3"
}
}
}]
}
}, {
"bool": {
"should": [{
"term": {
"source": {
"value": "新华社"
}
}
}, {
"term": {
"source": {
"value": "中国经济网"
}
}
}]
}
}, {
"bool": {
"should": [{
"term": {
"type": {
"value": "经济简报"
}
}
}, {
"term": {
"type": {
"value": "外贸简报"
}
}
}]
}
}, {
"range": {
"pubDate": {
"gte": "2023-03-29",
"lte": "2023-03-30"
}
}
}],
"must": [{
"multi_match": {
"fields": ["title", "content", "companies"],
"query": "立足优势稳住外贸基本盘"
}
}]
}
},
"score_mode": "sum"
}
},
"track_scores": false,
"version": true
}
4.3 接口测试
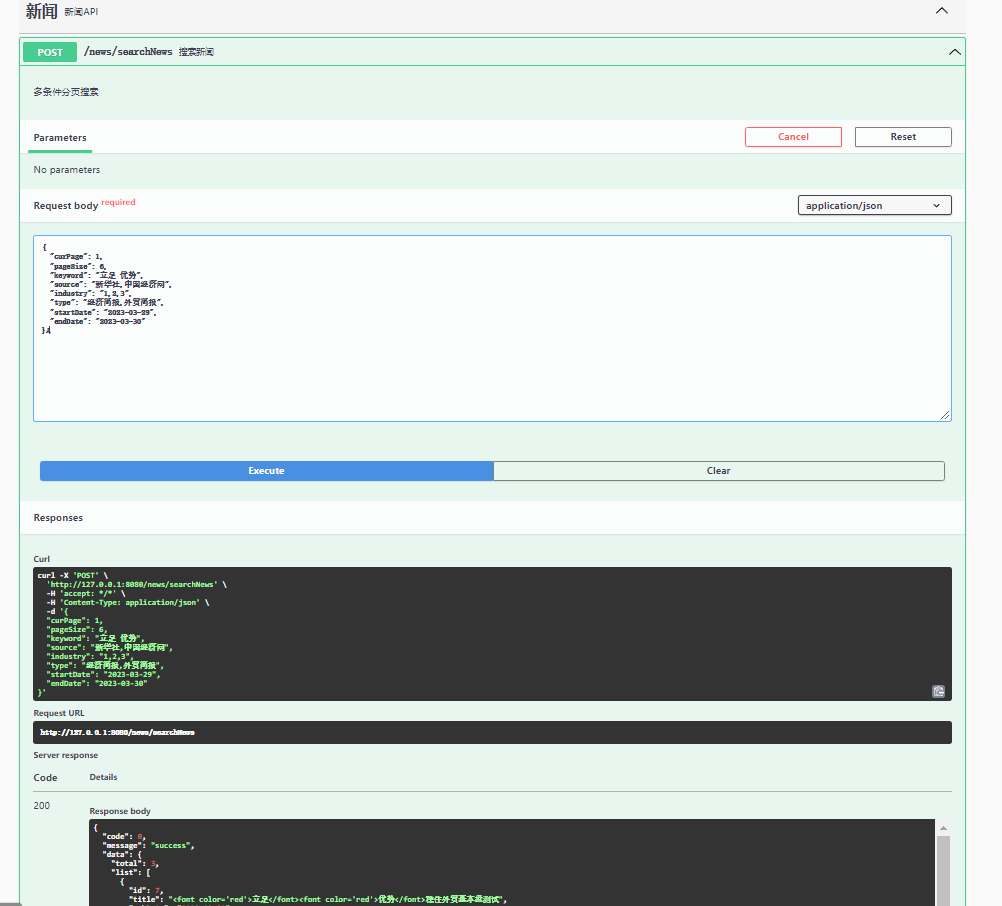
Elasticsearch搜索功能的实现(五)-- 实战的更多相关文章
- ElasticSearch(五):简单的ElasticSearch搜索功能
这里主要是一些简单的ElasticSearch的搜索功能,复杂的搜索,比如过滤,聚合等以后单独在写 1. 搜索全部 GET book/_search 直接搜索全部,下面是对搜索结果的详细介绍:默认情况 ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 四十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
Django实现搜索功能 1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` lis ...
- 「小程序JAVA实战」小程序搜索功能(55)
转自:https://idig8.com/2018/09/23/xiaochengxujavashizhanxiaochengxusousuogongneng54/ 通过用户搜索热销词,将热销词添加到 ...
- Django项目实战 - 搜索功能(转)
首先,前端已实现搜索功能页面, 我们直接写后台逻辑: Q()可以实现 逻辑或的判断, name_ _ icontains 表示 name字段包含搜索的内容,i表示忽略大小写. from djang ...
- 如何使用 Lucene 做网站高亮搜索功能?
现在基本上所有网站都支持搜索功能,现在搜索的工具有很多,比如Solr.Elasticsearch,它们都是基于 Lucene 实现的,各有各的使用场景.Lucene 比较灵活,中小型项目中使用的比较多 ...
- ElasticSearch搜索介绍四
ElasticSearch搜索 最基础的搜索: curl -XGET http://localhost:9200/_search 返回的结果为: { "took": 2, &quo ...
- 从 0 使用 SpringBoot MyBatis MySQL Redis Elasticsearch打造企业级 RESTful API 项目实战
大家好!这是一门付费视频课程.新课优惠价 699 元,折合每小时 9 元左右,需要朋友的联系爱学啊客服 QQ:3469271680:我们每课程是明码标价的,因为如果售价为现在的 2 倍,然后打 5 折 ...
- Elasticsearch搜索资料汇总
Elasticsearch 简介 Elasticsearch(ES)是一个基于Lucene 构建的开源分布式搜索分析引擎,可以近实时的索引.检索数据.具备高可靠.易使用.社区活跃等特点,在全文检索.日 ...
- ThinkPHP之中getlist方法实现数据搜索功能
自己在ThinkPHP之中的model之中书写getlist方法,其实所谓的搜索功能无非就是数据库查询之中用到的like %string%,或者其他的 字段名=特定值,这些sql语句拼接在and语句 ...
随机推荐
- spring管理配置文件实现注入
创建配置文件 写入以下内容: 创建配置文件的bean: <bean id="configProperties" class="org.springframework ...
- 查看mmdetection中模型的配置信息
方法一 可以直接打开mmdetection中的目录查看,/configs目录下都是对应的模型的配置 示例: 可以找到_base_目录下的这四个文件文件查看配置. 方法二 读取配置文件查看 在命令行中输 ...
- nextcloud file location
- 性能工具---JConsole基于JMX的可视化监视、管理工具
与visualvm类似: JConsole: (Java Monitoring and Management Console),一种基于JMX的可视化监视.管理工具 VisualVM:(All-in- ...
- 2019年居然还出版了一本ASP学习的书籍
ASP+Dreamweaver动态网站开发(第2版)孙更新,宾晟,李晓娜 著 内容简介 <ASP+Dreamweaver动态网站开发(第2版)>详细介绍了ASP的脚本语言基础.ASP的相关 ...
- 微信网页授权——获取code、access_token、openid,及跨域问题解决
首先在微信开发文档中有提到微信网页授权的操作步骤: 第一步:用户同意授权,获取code 在确保微信公众账号拥有授权作用域(scope参数)的权限的前提下(服务号获得高级接口后,默认拥有scope参数中 ...
- pytest用例管理框架实战(基础篇)
先安装pip install pytest pytest用例管理框架 默认规则: 1.py文件必须以test_开头或者_test结尾 2.类名必须以test开头 3.测试用例必须以test_开头 ge ...
- 还不知道如何在java中终止一个线程?快来,一文给你揭秘
目录 简介 Thread.stop被禁用之谜 怎么才能安全? 捕获异常之后的处理 总结 简介 工作中我们经常会用到线程,一般情况下我们让线程执行就完事了,那么你们有没有想过如何去终止一个正在运行的线程 ...
- 传输安全HTTPS
为什么要有 HTTPS 为什么要有 HTTPS?简单的回答是:"因为 HTTP 不安全".HTTP 怎么不安全呢? 通信的消息会被窃取,无法保证机密性(保密性):由于 HTTP 是 ...
- rosdep初始化顺利进行
rosdep初始化顺利进行 rosdep初始化需要两条命令 sudo rosdep init rosdep update 但在国内,我们通常会出现因为网络状况访问服务器超时的问题 解决方案就是将资源手 ...