webpack构建缓存机制-hash介绍
前言
浏览器为了优化体验,会有缓存机制。如果浏览器判断当前资源没有更新,就不会去服务端下载,而是直接使用本地资源。在webpack的构建中,我们通常使用给文件添加后缀值来改名以及提取公共代码到不会改变的lib包中来解决新资源缓存问题。
hash & chunkhash & contenthash
输出文件名output Filenames
我们在webpack构建中通过配置filenames来决定输出的文件名,比如我们的配置如下
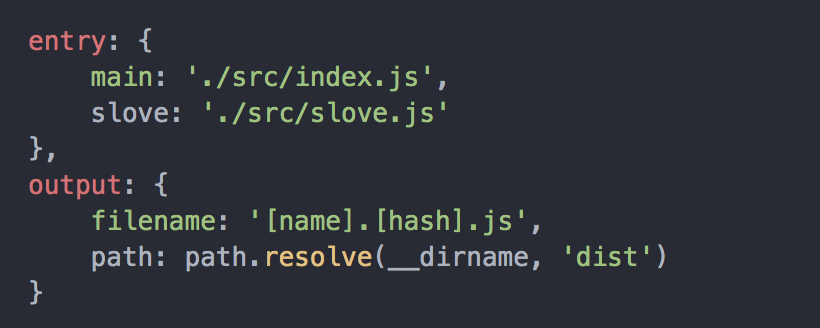
则打包出来的目录如下
可以看到, 打包出来的js名称对应的就是这样的规则,这里之所以name对应的是main, 是因为我们没有指定entry的key值,默认是main,否则就是相对于的key值。
hash
在上面,我们看到,我们配置的hash值,然后打包出的是一个长串字符串,这边的的长度我们可以指定,比如配置为
entry: './src/index.js',
output: {
filename: '[name].[hash:8].js',
path: path.resolve(__dirname, 'dist')
}
这样打包出来的就是8位的字符串,我们看到这边main模块打包出的和slove模块打包出的hash值是一样的,这个是什么原因呢?我们先来看一下官方对于hash的解释
模块标识符(module identifier)的 hash
这个不是很好理解,什么叫做模块标识符呢?我们知道对于webpack来说,它是一个打包编译的过程,也就是一个 compilation的过程,这个标识符,标识的就是这个打包的过程。这样就很好解释了模块标识符的概念就是在相同编译打包过程中的模块所共有的标识符,也就是说同一过程产出的产物的hash值都是一样的,也就解释了上面的过程。
但是这样会有很大的问题,因为我们不想改变css模块而去影响到js打包出来的名称,这样不利于我们去做缓存。那该怎么去解决这样的问题呢?
chunkhash
这时候我们就需要chunkhash出场来解决问题了,我们先来看一下官方对于chunkhash的解释
chunk 内容的 hash
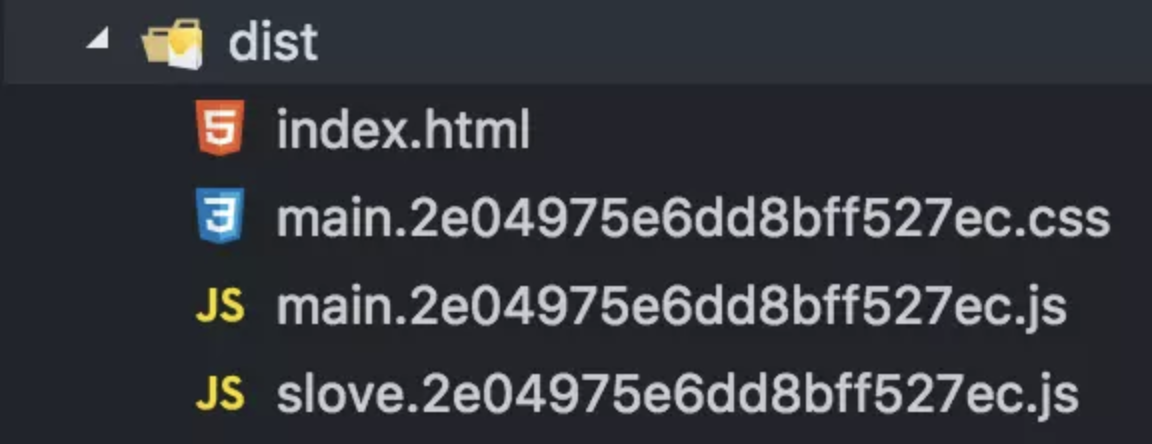
我们知道chunk指代的是模块,顾名思义,chunkhash就是模块的hash,也就是根据模块内容计算的hash值。那这边我们css模块的修改和js模块就没有关系,我们看一下使用chunkhash打包出来的结果,配置如下:
entry: {
main: './src/index.js',
slove: './src/slove.js'
},
output: {
filename: '[name].[chunkhash].js',
path: path.resolve(__dirname, 'dist')
}
这时候打包出来的目录如图所示:

这时候我们看到main模块与slove模块的hash值是不同的,这样我们修改main中的内容就不会修改slove的名称,slove的缓存就可以继续使用了。但是,这时候我们发现,main模块中的css文件和js文件的hash值是相同的。如果我们修改了js的内容,css的打包名称也会改变,这是我们不需要的,所以我们怎么解决这个问题呢。
contenthash
从名称上我们可以知道,它是根据文件内容来定义hash值得,所以我们就可以使用插件extract-text-webpack-plugin定义的contenthash来打包。配置如下:
new MiniCssExtractPlugin({
filename: "[name].[contenthash].css"
})
这样打包出来的结果是:

作者:JungleW
链接:https://www.jianshu.com/p/e609e7b55aa7
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
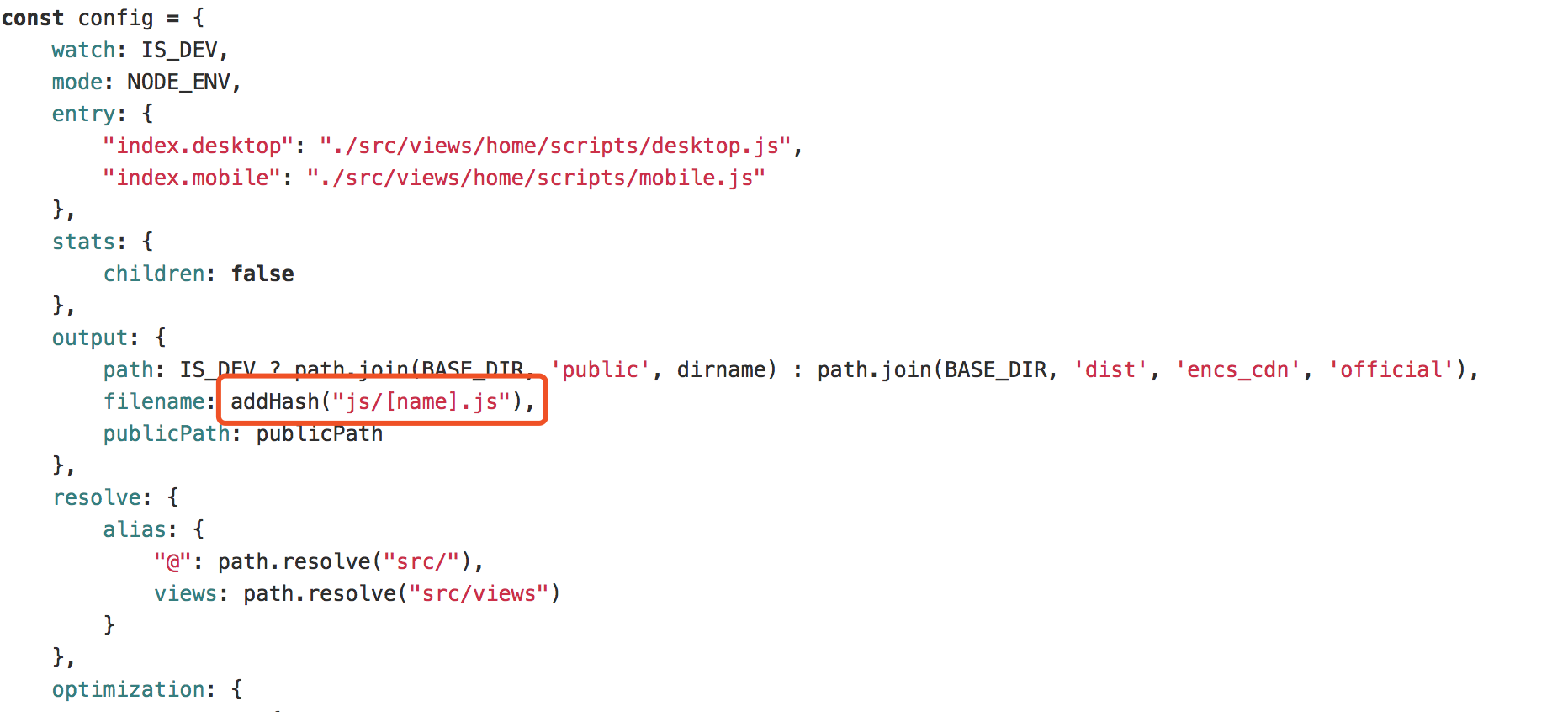
总结的一个方法:
const addHash = fname => {
var r = fname;
if (IS_DEV) return r;
const name = "[name]";
const index = fname.lastIndexOf(name);
if (index !== -1) {
const suffix = fname.substring(index + name.length);
let hash = 'hash'
if (suffix === '.js') {
hash = 'chunkhash'
} else if (suffix === '.css') {
hash = 'contenthash'
}
r = fname.replace(name + suffix, `${name}.[${hash}:8]${suffix}`);
}
return r;
};
引入的例子如下图:
webpack构建缓存机制-hash介绍的更多相关文章
- hibernate缓存机制详细介绍
hibernate的缓存机制,包括一级缓存(session级别).二级缓存(sessionFactory级别). 一:hibernate的 N+1问题 list()获得对象: 如果通过list()方法 ...
- 利用构建缓存机制缩短Docker镜像构建时间
在使用Docker部署PHP或者node.js应用时,常用的方法是将代码和环境镜像打包成一个镜像然后运行,一些云厂商提供了非常便捷的操作,只需要把我们的代码提交到VCS上,然后它们就会帮我们拉取代码并 ...
- Sql Server tempdb原理-缓存机制解析实践
Tempdb就像Sqlserver的临时仓库,各式各样的对象,数据在里面进行频繁计算,操作.大量的操作使得tempdb可能面临很大压力,tempdb中缓存的设计就是为了缓解这些压力.这次就为大家介绍下 ...
- Solr4.8.0源码分析(19)之缓存机制(二)
Solr4.8.0源码分析(19)之缓存机制(二) 前文<Solr4.8.0源码分析(18)之缓存机制(一)>介绍了Solr缓存的生命周期,重点介绍了Solr缓存的warn过程.本节将更深 ...
- Halo 开源项目学习(七):缓存机制
基本介绍 我们知道,频繁操作数据库会降低服务器的系统性能,因此通常需要将频繁访问.更新的数据存入到缓存.Halo 项目也引入了缓存机制,且设置了多种实现方式,如自定义缓存.Redis.LevelDB ...
- 转:使用memc-nginx和srcache-nginx模块构建高效透明的缓存机制
原文地址:http://blog.codinglabs.org/articles/nginx-memc-and-srcache.html 为了提高性能,几乎所有互联网应用都有缓存机制,其中Memcac ...
- [转] 使用memc-nginx和srcache-nginx模块构建高效透明的缓存机制
为了提高性能,几乎所有互联网应用都有缓存机制,其中Memcache是使用非常广泛的一个分布式缓存系统.众所周知,LAMP是非常经典的Web架构方式,但是随着Nginx的 成熟,越来越多的系统开始转型为 ...
- mybatis的缓存机制及用例介绍
在实际的项目开发中,通常对数据库的查询性能要求很高,而mybatis提供了查询缓存来缓存数据,从而达到提高查询性能的要求. mybatis的查询缓存分为一级缓存和二级缓存,一级缓存是SqlSessio ...
- 【Redis缓存机制】1.Redis介绍和使用场景
(1)持久化数据库的缺点平常我们使用的关系型数据库有Mysql.Oracle以及SqlServer等,在开发的过程中,数据通常都是通过Web提供的数据库驱动来链接数据库进行增删改查. 那么,我们日常使 ...
随机推荐
- [CSP-S模拟测试]:mine(DP)
题目描述 有一个$1$维的扫雷游戏,每个格子用$*$表示有雷,用$0/1/2$表示无雷并且相邻格子中有$0/1/2$个雷.给定一个仅包含$?$.$*$.$0$.$1$.$2$的字符串$s$,问有多少种 ...
- 前端每日实战:29# 视频演示如何不用 transition 和 animation 也能做网页动画
效果预览 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/BxbQJj 可交互视频教程 此视频 ...
- 记录MNIST采用卷积方式实现与理解
从时间上来说,这篇文章写的完了,因为这个实验早就做完了:但从能力上来说,这篇文章出现的早了,因为很多地方我都还没有理解.如果不现在写,不知道什么时候会有时间是其一,另外一个原因是怕自己过段时间忘记. ...
- java中四种访问修饰符区别及详解全过程
客户端程序员:即在其应用中使用数据类型的类消费者,他的目标是收集各种用来实现快速应用开发的类. 类创建者:即创建新数据类型的程序员,目标是构建类. 访问控制存在的原因:a.让客户端程序员无法触及他们不 ...
- Cocos2d 之FlyBird开发---GameUnit类
| 版权声明:本文为博主原创文章,未经博主允许不得转载. 这节来实现GameUnit类中的一些函数方法,其实这个类一般是一个边写边完善的过程,因为一般很难一次性想全所有的能够供多个类共用的方法.下 ...
- Python基础代码1
Python基础代码 import keyword#Python中关键字 print(keyword.kwlist) ['False', 'None', 'True', 'and', 'as', 'a ...
- 深入研究浏览器对HTML解析过程
HTML HTML解析 HTML解析是一个将字节转化为字符,字符解析为标记,标记生成节点,节点构建树的过程. 标记化算法 是词法分析过程,将输入内容解析成多个标记.HTML标记包括起始标记.结束标记. ...
- poj3252 Round Numbers(数位dp)
题目传送门 Round Numbers Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 16439 Accepted: 6 ...
- nginx的原理
Nginx会按需同时运行多个进程:一个主进程(master)和几个工作进程(worker),配置了缓存时还会有缓存加载器进程 (cache loader)和缓存管理器进程(cache manager) ...
- IDEA compile successfully many errors still occur
Compile and install successfully with maven in IDEA, but error prompt still popup. Your local enviro ...